
The goal of this post is to provide an in-depth discussion of BPF ring buffers, covering their internals, including memory allocation, user-space mapping, locking mechanisms, and efficient data sharing with user-land processes. This article is quite detailed, and I understand that some of you may not want to spend minutes


The goal of this post is to provide an in-depth discussion of BPF ring buffers, covering their internals, including memory allocation, user-space mapping, locking mechanisms, and efficient data sharing with user-land processes.
This article is quite detailed, and I understand that some of you may not want to spend minutes or even hours reading through the entire piece. If you're looking for a quick overview, I begin with a non-technical discussion before diving into the technical details. Feel free to navigate to the section you prefer.
There is also a demo at the end of the post demonstrating how to deploy a BPF program that populates a ring buffer using the libbpf APIs we would have covered in this post. The code is accessible at https://github.com/mouadk/ebpf-ringbuffer/tree/main.
I decided to write a post about the internals of ring buffers because I have developed an interest in scalable provenance graph data collection using eBPF (e.g for provenance intrusion detection systems, threat hunting and machine learning i.e PIDS). It turns out that existing solutions suffer from data loss and memory/storage overhead (e.g APT attacks can last for months), so I needed to take a closer look at what is happening at the low level.
Basically, eBPF provides the capability to develop code that runs in the kernel space, similar to kernel modules, but in a safe fashion i.e., without risking kernel crashes ( cf https://www.oligo.security/blog/recent-crowdstrike-outage-emphasizes-the-need-for-ebpf-based-sensors). Running code directly in the kernel is highly efficient because it avoids excessive context switching i.e when intercepting system calls in user space. Since system calls will inevitably enter kernel space, it makes sense to execute the necessary code there safely and collect relevant data.
With eBPF, you can place probes or sensors almost anywhere in the kernel, including tracepoints. I won't go into the details here, as that is beyond the scope of today's discussion. Instead, we will focus on how, once we have a mechanism to tap in the kernel, we can efficiently send it to a remote persistent provenance storage. The most recommended and efficient way to do this right now is through ring buffers which uses zero copy under the hood.
A ring buffer is a kernel data structure that eBPF programs populate concurrently while observing activities like system calls. While the kernel specifies the format of the ring buffer, it is up to you to define the format of the samples housed in the buffer i.e you are responsible for parsing, eBPF only gives you the 'infra' to do it efficiently.
Now, if eBPF programs update the data structure that resides in kernel memory, how can user space access it efficiently? This is achieved by sharing physical pages backing the buffer with user space. Specifically, when a client application creates a BPF ring buffer, it receives a file descriptor or fd, an id that the kernel uses to identify the ring buffer of interest (or more specifically the file structure).
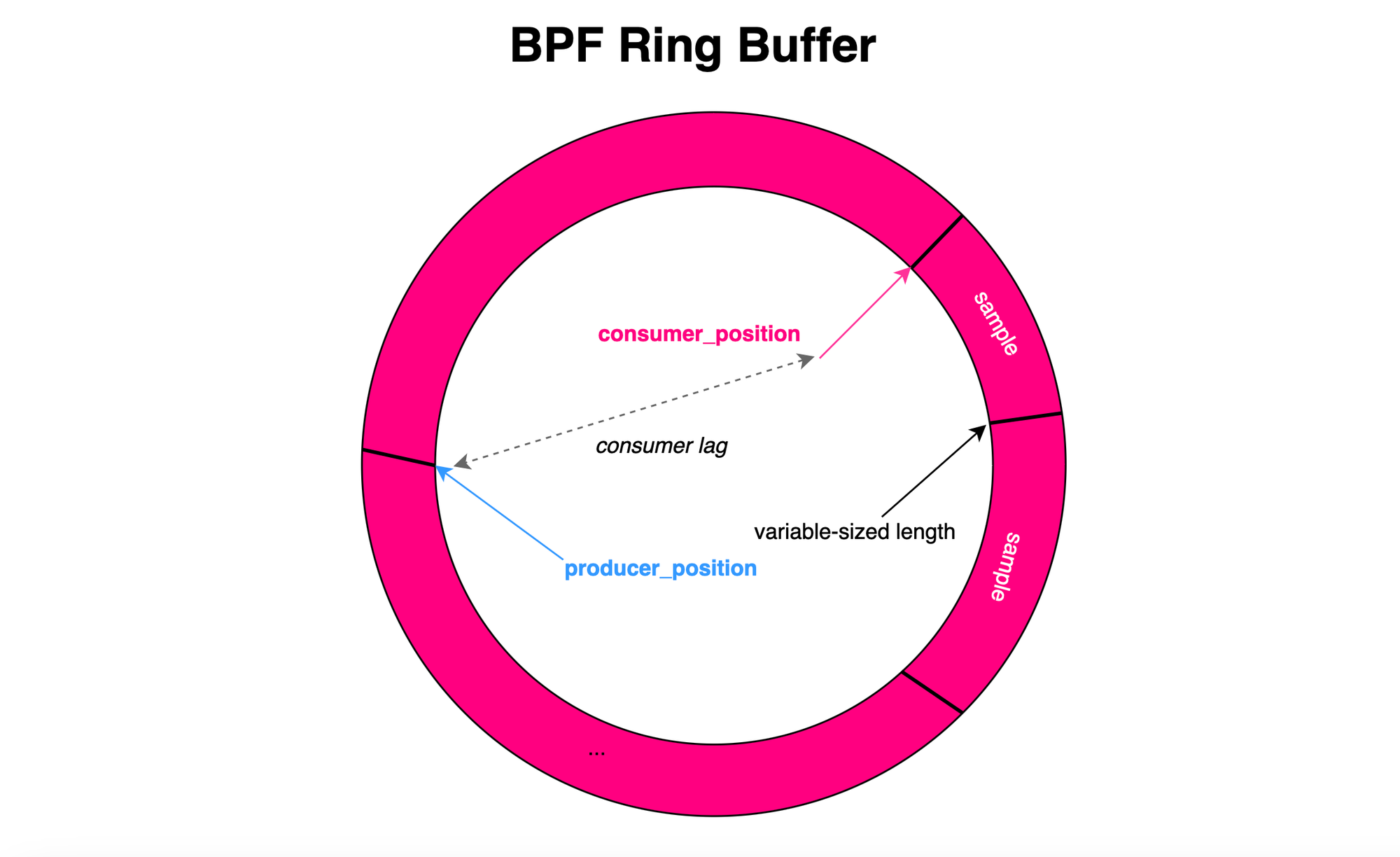
Multiple ring buffers can be created, for example, one per CPU ( ring buffers supports concurrent writers i.e processors can write data concurrently, the buffer is protected using a spin lock).
Using a file descriptor, the application can request access to the kernel buffer by mapping the physical pages to its own virtual address space allowing direct access to the ring buffer for reading and parsing samples using direct pointers i.e accessing data using memory locations.
The ring buffer consists of a data structure with a consumer position, a producer position, and a data buffer housing the samples. The consumer position indicates the read location in the data buffer, while the producer position indicates the next write location. The difference between the consumer and producer positions represents the lag. When the consumer position catches up to the producer position, the consumer is up to date. However, if the producer moves too quickly or the consumer lags behind, the producer will discard data (e.g reservation fails), leading to data loss. In the NMI context, as we will see later, the producer processor or core cannot keep spinning while waiting for the lock to be released. In this case, data loss is exacerbated.
Ok, now consumers or libraries interact with the ring buffer directly using the virtual addresses pointing to the same physical pages. But how do they know when new data is available? There are two primary approaches. The first is polling: the kernel can wake up the process and notify it that new data is available (e.g through epoll system call). The second option is through active spinning, basically the consumer continuously checks, e.g., in a loop, whether the producer pointer has advanced.
Once the data is collected, it is parsed according to the defined format or protocol and then sent to a provenance storage system for modelling. This is illustrated below.
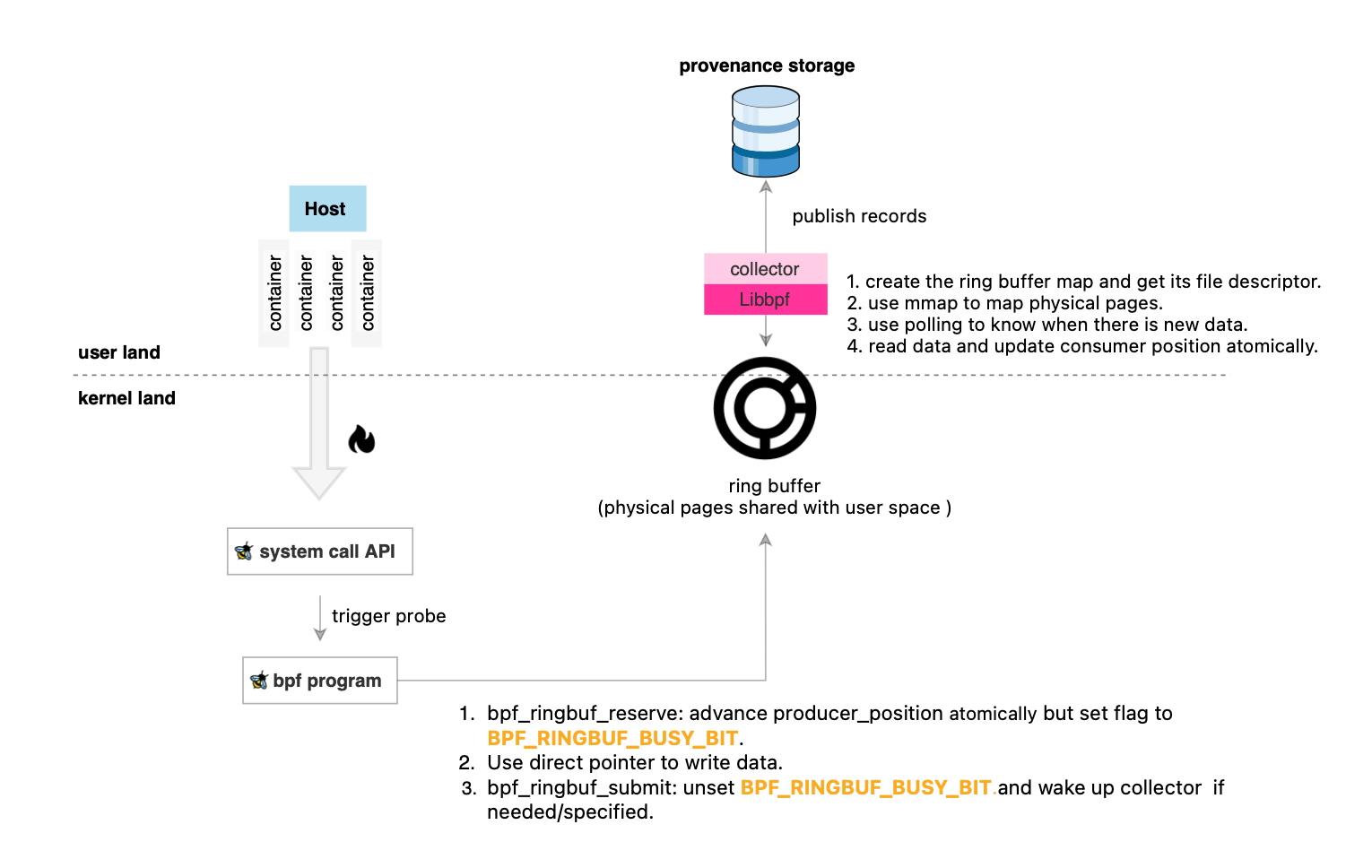
While you don’t need to learn all the internal mechanics, understanding them is essential for developing highly efficient and scalable programs. We will cover in this section ring buffers internals (this is also important for next posts about scalable provenance collection).
The BPF ring buffer is a power-of-2-sized data structure managed by the kernel, allowing BPF programs to efficiently send data to user space. The structure of bpf_ringbuf in the kernel is partially shown below.
struct bpf_ringbuf {
…
unsigned long consumer_pos __aligned(PAGE_SIZE);
unsigned long producer_pos __aligned(PAGE_SIZE);
unsigned long pending_pos;
char data[] __aligned(PAGE_SIZE);
}It has an 4/8-byte pointer for the consumer position, 4/8 bytes for the producer position, and additional internal structures. Both the consumer and producer will be housed in separate pages, enforced using __aligned(PAGE_SIZE). This alignment is crucial for mmap or memory mapping, allowing different protection flags to be applied when sharing the physical pages of the ring buffer with the user land. Specifically, user land programs are allowed to update the consumer position, while the data and producer position (including the pending position housed in producer_pos page, which you can omit for now) should remain protected with read-only access. To achieve this, the user (e.g., through libpf) will issue two mmap system calls, one to map the first part, starting from consumer_pos(hence the need for page alignment), and another for the rest.
If we look at the user-space library libbpf, struct ring_buffer is used to store pointer rings to an array of ring buffers (e.g., one per CPU if you want but kernel supports one for all CPUs).
struct ring_buffer {
struct epoll_event *events;
struct ring **rings;
size_t page_size;
int epoll_fd;
int ring_cnt;
};Then the ring structure is defined below. The consumer_pos, producer_pos and data are the data mapped from the kernel, the actual user space structure does not need to match the kernel version as libpf will pack other internal fields (e.g event handler).
struct ring {
ring_buffer_sample_fn sample_cb;
void *ctx;
void *data;
unsigned long *consumer_pos;
unsigned long *producer_pos;
unsigned long mask;
int map_fd;
};
map_fd is the file descriptor of the map i.e the ring buffer map. The id is obtained the map is created.
When libpf issues the system call to create a ring buffer, it gets a file descriptor which can be used to populate the ring buffer structure in user space. Specifically, this is achieved using two APIs ring_buffer__new and ring_buffer__add.
ring_buffer__new should always be called first, it will wrap the first ring buffer and if you need to create other ring buffers (e.g per cpu) you can invoke ring_buffer__add, the library will basically maintain an array of ring buffers.
Here is the code looks like for ring_buffer__new, it allocates memory for a struct ring_buffer discussed earlier, it then set page size, create epoll file descriptor (will be covered later) and finally delegates to ring_buffer__add.
struct ring_buffer *
ring_buffer__new(int map_fd, ring_buffer_sample_fn sample_cb, void *ctx,
const struct ring_buffer_opts *opts)
{
struct ring_buffer *rb;
int err;
if (!OPTS_VALID(opts, ring_buffer_opts))
return errno = EINVAL, NULL;
rb = calloc(1, sizeof(*rb));
if (!rb)
return errno = ENOMEM, NULL;
rb->page_size = getpagesize();
rb->epoll_fd = epoll_create1(EPOLL_CLOEXEC);
if (rb->epoll_fd < 0) {
err = -errno;
pr_warn("ringbuf: failed to create epoll instance: %s\n", errstr(err));
goto err_out;
}
err = ring_buffer__add(rb, map_fd, sample_cb, ctx);
if (err)
goto err_out;
return rb; Below is the code fo ring_buffer__add:
* Add extra RINGBUF maps to this ring buffer manager */
int ring_buffer__add(struct ring_buffer *rb, int map_fd,
ring_buffer_sample_fn sample_cb, void *ctx)
{
...
struct ring *r;
__u64 mmap_sz;
void *tmp;
int err;
...
tmp = libbpf_reallocarray(rb->rings, rb->ring_cnt + 1, sizeof(*rb->rings));
if (!tmp)
return libbpf_err(-ENOMEM);
rb->rings = tmp;
...
rb->rings[rb->ring_cnt] = r;
r->map_fd = map_fd;
r->sample_cb = sample_cb;
r->ctx = ctx;
r->mask = info.max_entries - 1;
/* Map writable consumer page */ <------- HERE WE MAP the consumer position as r/w ----->
tmp = mmap(NULL, rb->page_size, PROT_READ | PROT_WRITE, MAP_SHARED, map_fd, 0);
....
r->consumer_pos = tmp;
.....
<-------- here we map the producer pos and data as read only
tmp = mmap(NULL, (size_t)mmap_sz, PROT_READ, MAP_SHARED, map_fd, rb->page_size);
r->producer_pos = tmp;
r->data = tmp + rb->page_size;
----------
It allocates memory for the ring structure (which in turn points to the actual data). As discussed earlier, it then issues two mmap system calls. The first one is:
tmp = mmap(NULL, rb->page_size, PROT_READ | PROT_WRITE, MAP_SHARED, map_fd, 0);
r->consumer_pos = tmp;The first mmap call maps the physical page backing consumer position as read-write, which is why the head and tail pointers must reside in separate pages. We then immediately set the consumer position.
Next, the second mmap call is invoked. It maps twice the maximum entries (in bytes) of the data buffer plus one page for the producer position as read-only. After that, we immediately set the producer and data pointers.
mmap_sz = rb->page_size + 2 * (__u64)info.max_entries;
tmp = mmap(NULL, (size_t)mmap_sz, PROT_READ, MAP_SHARED, map_fd, rb->page_size);
...
r->producer_pos = tmp;
r->data = tmp + rb->page_size;It then uses epoll_ctl() to register map_fd to the interest list of the epoll file descriptor.
e->events = EPOLLIN;
e->data.fd = rb->ring_cnt;
if (epoll_ctl(rb->epoll_fd, EPOLL_CTL_ADD, map_fd, e) < 0) {
err = -errno;
pr_warn("ringbuf: failed to epoll add map fd=%d: %s\n",
map_fd, errstr(err));
goto err_out;
}
To consume data, you have two options. You can define a while (true) loop that continuously checks the ring buffers in the manager array to see if any data is available. Alternatively, you can use epoll, which sleeps on a set of file descriptors corresponding to the kernel buffers. When a buffer is ready, the kernel through epoll wakes up the application, ensuring that data is available. Once you obtain a data pointer via the consumer position in the data buffer, you can start reading data from memory and process it i.e parse it and send it to the provenance storage.
The BPF system call bpf() is registered in the syscall table, which is defined in arch/{arch}/entry/syscalls/syscall_xx.tbl. Below is an example of the entry for the BPF system call for x86:
321 common bpf sys_bpf
This means that sys_bpf is the handler for the system call. The linkage is as follows:
asmlinkage long sys_bpf(int cmd, union bpf_attr __user *attr, unsigned int size);
Where cmd represents the BPF command e.g BPF_MAP_CREATE, attr is a pointer to bpf_attr, which holds the attributes of the BPF operation provided by the user, size is the size of the bpf_attr structure.
The internal handler, __sys_bpf, is defined in linux/kernel/bpf/syscall.c:
SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size)
{
return __sys_bpf(cmd, USER_BPFPTR(uattr), size);
}linux/kernel/bpf/syscall.c
__sys_pbf first copies user attributes into kernel memory to prevent TOCTOU. Then, it invokes security_bpf() to enforce LSM security checks (invoking configured hooks). Based on the provided cmd(e.g., BPF_MAP_CREATE), it delegates the operation to the appropriate handler (e.g map_create, see next subsection).
The call to create the ring buffer map in the kernel is map_create (linux/kernel/bpf/syscall.c). Here is wha the code looks like:
static int map_create(union bpf_attr *attr)
{
const struct bpf_map_ops *ops;
struct bpf_token *token = NULL;
int numa_node = bpf_map_attr_numa_node(attr);
u32 map_type = attr->map_type;
struct bpf_map *map;
bool token_flag;
int f_flags;
int err;
...
/* find map type and init map: hashtable vs rbtree vs bloom vs ... */
map_type = attr->map_type;
if (map_type >= ARRAY_SIZE(bpf_map_types))
return -EINVAL;
map_type = array_index_nospec(map_type, ARRAY_SIZE(bpf_map_types));
ops = bpf_map_types[map_type];
if (!ops)
return -EINVAL;
....
....
/* Intent here is for unprivileged_bpf_disabled to block BPF map
* creation for unprivileged users; other actions depend
* on fd availability and access to bpffs, so are dependent on
* object creation success. Even with unprivileged BPF disabled,
* capability checks are still carried out.
*/
if (sysctl_unprivileged_bpf_disabled && !bpf_token_capable(token, CAP_BPF))
goto put_token;
...
map = ops->map_alloc(attr);
if (IS_ERR(map)) {
err = PTR_ERR(map);
goto put_token;
}
map->ops = ops;
map->map_type = map_type;
....
err = security_bpf_map_create(map, attr, token);
....
map = ops->map_alloc(attr);
if (IS_ERR(map)) {
err = PTR_ERR(map);
goto put_token;
}
map->ops = ops;
map->map_type = map_type;
....
err = bpf_map_new_fd(map, f_flags);
if (err < 0) {
/* failed to allocate fd.
* bpf_map_put_with_uref() is needed because the above
* bpf_map_alloc_id() has published the map
* to the userspace and the userspace may
* have refcnt-ed it through BPF_MAP_GET_FD_BY_ID.
*/
bpf_map_put_with_uref(map);
return err;
}
return err;There are different kind of maps, and each map creation is naturally handled differently. the kernel implements the through the use of virtual function table , that is, depending on the type of the map it dispatches to the the virtual functions table that implement the logic for kernel buffer creation, release, mmap etc. Here is what the table looks like bpf_map_ops:
struct bpf_map_ops {
/* funcs callable from userspace (via syscall) */
int (*map_alloc_check)(union bpf_attr *attr);
struct bpf_map *(*map_alloc)(union bpf_attr *attr);
void (*map_release)(struct bpf_map *map, struct file *map_file);
void (*map_free)(struct bpf_map *map);
int (*map_get_next_key)(struct bpf_map *map, void *key, void *next_key);
void (*map_release_uref)(struct bpf_map *map);
void *(*map_lookup_elem_sys_only)(struct bpf_map *map, void *key);
int (*map_lookup_batch)(struct bpf_map *map, const union bpf_attr *attr,
union bpf_attr __user *uattr);
int (*map_lookup_and_delete_elem)(struct bpf_map *map, void *key,
void *value, u64 flags);
int (*map_lookup_and_delete_batch)(struct bpf_map *map,
const union bpf_attr *attr,
union bpf_attr __user *uattr);
int (*map_update_batch)(struct bpf_map *map, struct file *map_file,
const union bpf_attr *attr,
union bpf_attr __user *uattr);
int (*map_delete_batch)(struct bpf_map *map, const union bpf_attr *attr,
union bpf_attr __user *uattr);
...}Both eBPF programs and user space can access it using bpf-helpers or via system calls for user space programs.
Now, each BPF map type has an associated bpf_map_ops structure that defines how it behaves. For ring buffers, the relevant operations are encapsulated in ringbuf_map_ops (for instance when the user space client issues mmapor pollsystem call, bpf_map_ops.map_mmap and bpf_map_ops.map_pollare invoked respectively:
const struct bpf_map_ops ringbuf_map_ops = {
.map_meta_equal = bpf_map_meta_equal,
.map_alloc = ringbuf_map_alloc,
.map_free = ringbuf_map_free,
.map_mmap = ringbuf_map_mmap_kern,
.map_poll = ringbuf_map_poll_kern,
.map_lookup_elem = ringbuf_map_lookup_elem,
.map_update_elem = ringbuf_map_update_elem,
.map_delete_elem = ringbuf_map_delete_elem,
.map_get_next_key = ringbuf_map_get_next_key,
.map_mem_usage = ringbuf_map_mem_usage,
.map_btf_id = &ringbuf_map_btf_ids[0],
};
linux/kernel/bpf/syscall.c
User space access ebpf objects through file descriptors and each file descriptor has a struct file_operationsthat will delegate to the map.
const struct file_operations bpf_map_fops = {
#ifdef CONFIG_PROC_FS
.show_fdinfo = bpf_map_show_fdinfo,
#endif
.release = bpf_map_release,
.read = bpf_dummy_read,
.write = bpf_dummy_write,
.mmap = bpf_map_mmap,
.poll = bpf_map_poll,
.get_unmapped_area = bpf_get_unmapped_area,
};linux/kernel/bpf/syscall.c
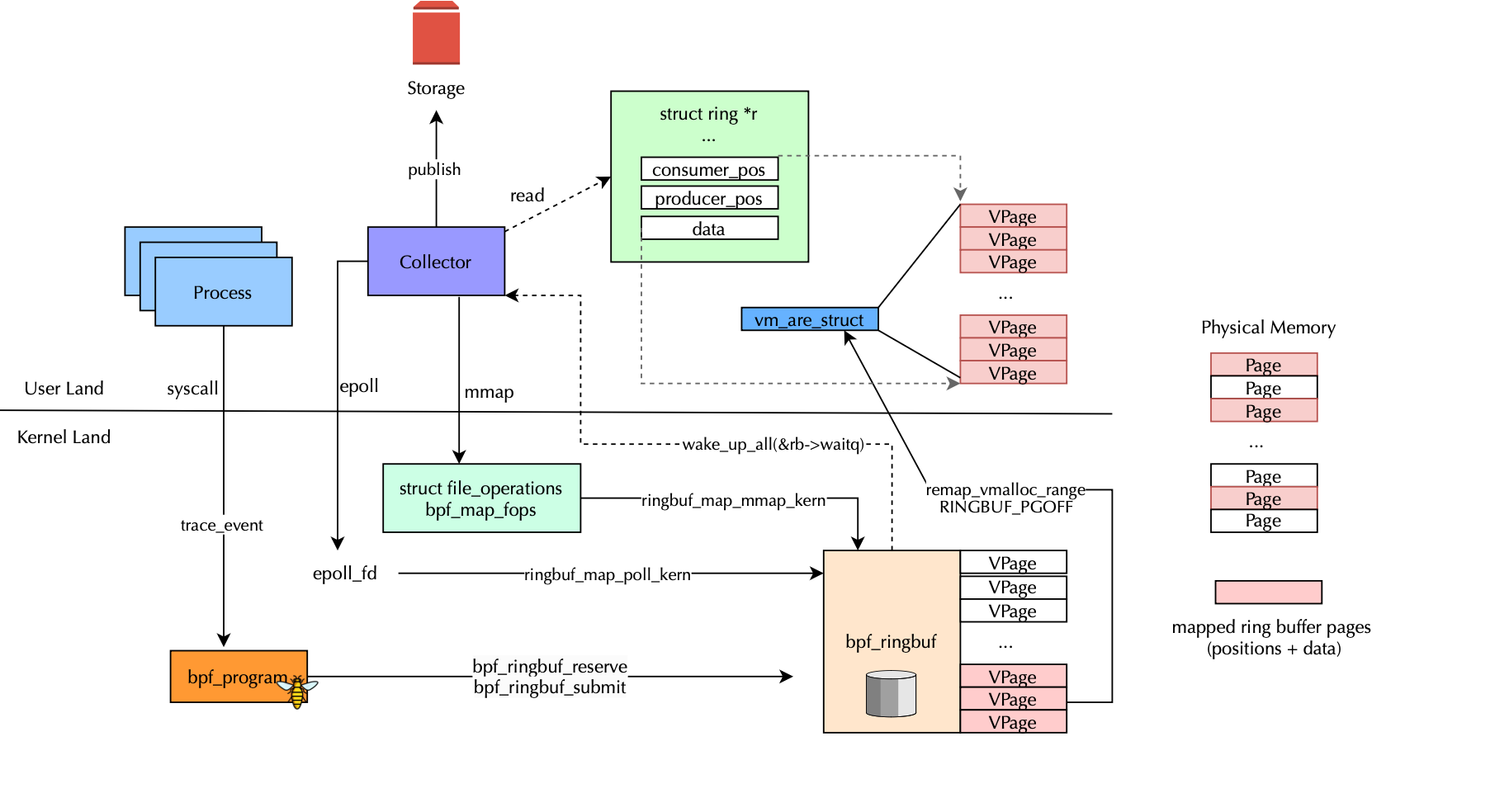
Once the bpf_map_ops wrapping the behavior of the map is identified, the kernel uses its .map_alloc to allocate physical memory for the ring buffer.
static struct bpf_map *ringbuf_map_alloc(union bpf_attr *attr)
{
struct bpf_ringbuf_map *rb_map;
if (attr->map_flags & ~RINGBUF_CREATE_FLAG_MASK)
return ERR_PTR(-EINVAL);
if (attr->key_size || attr->value_size ||
!is_power_of_2(attr->max_entries) ||
!PAGE_ALIGNED(attr->max_entries))
return ERR_PTR(-EINVAL);
rb_map = bpf_map_area_alloc(sizeof(*rb_map), NUMA_NO_NODE);
if (!rb_map)
return ERR_PTR(-ENOMEM);
bpf_map_init_from_attr(&rb_map->map, attr);
rb_map->rb = bpf_ringbuf_alloc(attr->max_entries, rb_map->map.numa_node);
if (!rb_map->rb) {
bpf_map_area_free(rb_map);
return ERR_PTR(-ENOMEM);
}
return &rb_map->map;
}The code for page allocation is shown below. The kernel implements a double-mapped circular buffer, where each data page is mapped twice (enough because you cannot surpass the buffer size so...), thereby simplifying both the kernel and user-land implementations tremendously. This is illustrated below. Pages are allocated normally page = alloc_pages_node(numa_node, flags, 0); , next extended page structures are filled with the same content pages[nr_data_pages + i] = page;. Finally the ring buffer is mapped via rb = vmap(pages, nr_meta_pages + 2 * nr_data_pages,VM_MAP | VM_USERMAP, PAGE_KERNEL);. (void *)rb->data points to the virtual memory region containing the ring buffer’s double-mapped pages, and both the consumer and producer don’t need to check for wraparound manually (this is a huge benefit) because the mirrored pages ensure continuous reading and writing.
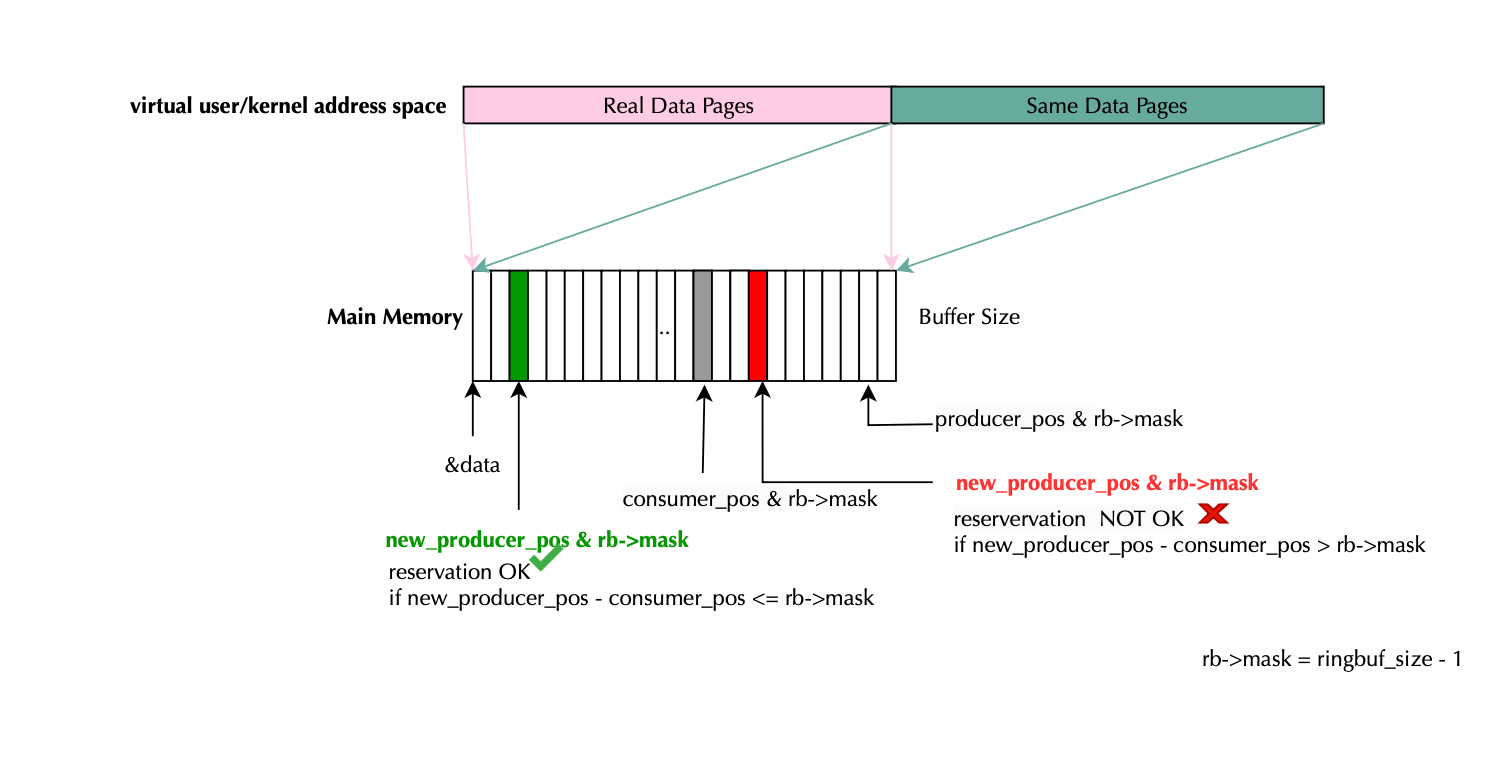
static struct bpf_ringbuf *bpf_ringbuf_area_alloc(size_t data_sz, int numa_node)
{
const gfp_t flags = GFP_KERNEL_ACCOUNT | __GFP_RETRY_MAYFAIL |
__GFP_NOWARN | __GFP_ZERO;
int nr_meta_pages = RINGBUF_NR_META_PAGES;
int nr_data_pages = data_sz >> PAGE_SHIFT;
int nr_pages = nr_meta_pages + nr_data_pages;
struct page **pages, *page;
struct bpf_ringbuf *rb;
size_t array_size;
int i;
/* Each data page is mapped twice to allow "virtual"
* continuous read of samples wrapping around the end of ring
* buffer area:
* ------------------------------------------------------
* | meta pages | real data pages | same data pages |
* ------------------------------------------------------
* | | 1 2 3 4 5 6 7 8 9 | 1 2 3 4 5 6 7 8 9 |
* ------------------------------------------------------
* | | TA DA | TA DA |
* ------------------------------------------------------
* ^^^^^^^
* |
* Here, no need to worry about special handling of wrapped-around
* data due to double-mapped data pages. This works both in kernel and
* when mmap()'ed in user-space, simplifying both kernel and
* user-space implementations significantly.
*/
array_size = (nr_meta_pages + 2 * nr_data_pages) * sizeof(*pages);
pages = bpf_map_area_alloc(array_size, numa_node);
if (!pages)
return NULL;
for (i = 0; i < nr_pages; i++) {
page = alloc_pages_node(numa_node, flags, 0);
if (!page) {
nr_pages = i;
goto err_free_pages;
}
pages[i] = page;
if (i >= nr_meta_pages)
pages[nr_data_pages + i] = page;
}
rb = vmap(pages, nr_meta_pages + 2 * nr_data_pages,
VM_MAP | VM_USERMAP, PAGE_KERNEL);
if (rb) {
kmemleak_not_leak(pages);
rb->pages = pages;
rb->nr_pages = nr_pages;
return rb;
}
err_free_pages:
for (i = 0; i < nr_pages; i++)
__free_page(pages[i]);
bpf_map_area_free(pages);
return NULL;
}The actual ring buffer, which stores the actual data is represented by thestruct bpf_ringbuf . consumer_pos,producer_pos/data again are page aligned in order to set different permissions i.e read/write for consumer and read only for the rest so that the user space can not mess with in-kernel tracking.
struct bpf_ringbuf {
wait_queue_head_t waitq;
.... we are mapping from here
unsigned long consumer_pos __aligned(PAGE_SIZE);
unsigned long producer_pos __aligned(PAGE_SIZE);
unsigned long pending_pos;
char data[] __aligned(PAGE_SIZE);
};bpf_map_ops functions as a virtual table and does not operate directly on the ringbuf_map_ops structure. Instead, it is accessed through bpf_map.
struct bpf_map {
const struct bpf_map_ops *ops;
struct bpf_map *inner_map_meta;
...
}Specifically, when allocating memory the following wrapping or container structure is created in the kernel virtual address space:
struct bpf_ringbuf_map {
struct bpf_map map;
struct bpf_ringbuf *rb;
};
and struct bpf_ringbuf_map-> map is what gets returned , when data needs to be unwrapped, one can use container_of macro to get the actual bpf_ringbuf.
Now that the BPF map is created, the next step is to store it in a location where both eBPF programs and the user-space application can access and operate on it.
eBPF objects including maps are accessed, controlled, and shared via a file descriptors. After creating the ring buffer, an entry in the file descriptor table is established using bpf_map_new_fd:
int bpf_map_new_fd(struct bpf_map *map, int flags)
{
int ret;
ret = security_bpf_map(map, OPEN_FMODE(flags));
if (ret < 0)
return ret;
return anon_inode_getfd("bpf-map", &bpf_map_fops, map,
flags | O_CLOEXEC);
}Here, bpf_map_fops defines how the file descriptor behaves. Two key functions in bpf_map_fops are: map_mmap, map_poll.
The bpf_map_mmap function is invoked when a user-space application wants to create a shared memory region and use virtual addresses directly to operate and reading data without issuing system calls (i.e create a virtual memory area pointing to physical pages backing the ring buffer). This allows direct memory access using pointers instead of consecutive system calls. On the other hand, bpf_map_poll is used when a user-space application wants to block until the file descriptor is ready.
Each file descriptor points to a struct file
struct file {
...
const struct file_operations *f_op;
struct address_space *f_mapping;
void *private_data;
struct inode *f_inode;
...
}The private_data field is used to points to the kernel buffer. In this case, private_data corresponds to struct bpf_map, which holds bpf_map_ops.
Now, using the the file descriptor, system calls can be issued, for instance to see if there is some data available. As said before, when the file descriptor was registered, a virtual table of type file_operations was added, and as shown below its .poll is invoked which basically delegates bpf_map_poll .
const struct file_operations bpf_map_fops = {
#ifdef CONFIG_PROC_FS
.show_fdinfo = bpf_map_show_fdinfo,
#endif
.release = bpf_map_release,
.read = bpf_dummy_read,
.write = bpf_dummy_write,
.mmap = bpf_map_mmap,
.poll = bpf_map_poll,
.get_unmapped_area = bpf_get_unmapped_area,
};And if we look at ringbuf_map_ops we observe that the call is actually delegated t0 ringbuf_map_poll_kern.
const struct bpf_map_ops ringbuf_map_ops = {
.map_meta_equal = bpf_map_meta_equal,
.map_alloc = ringbuf_map_alloc,
.map_free = ringbuf_map_free,
.map_mmap = ringbuf_map_mmap_kern,
.map_poll = ringbuf_map_poll_kern,
.map_lookup_elem = ringbuf_map_lookup_elem,
.map_update_elem = ringbuf_map_update_elem,
.map_delete_elem = ringbuf_map_delete_elem,
.map_get_next_key = ringbuf_map_get_next_key,
.map_mem_usage = ringbuf_map_mem_usage,
.map_btf_id = &ringbuf_map_btf_ids[0],
};The ring buffer has a wait queue (waitq), which the kernel uses to signal when data is available. Thepoll_wait function is invoked to register the calling process in the wait queue. When data becomes available, the task wakes up using wake_up(&rb_map->rb->waitq), signaling that data for this file descriptor is ready to be consumed.
static __poll_t ringbuf_map_poll_kern(struct bpf_map *map, struct file *filp,
struct poll_table_struct *pts)
{
struct bpf_ringbuf_map *rb_map;
rb_map = container_of(map, struct bpf_ringbuf_map, map);
poll_wait(filp, &rb_map->rb->waitq, pts);
if (ringbuf_avail_data_sz(rb_map->rb))
return EPOLLIN | EPOLLRDNORM;
return 0;
}But polling just let you know if the kernel buffer of a file descriptor is ready to be consumed (e.g new data appended that is there is new data that you probably did not see), this means you need first to have virtual access to the data, something achieved with mmap.
const struct bpf_map_ops ringbuf_map_ops = {
.map_meta_equal = bpf_map_meta_equal,
.map_alloc = ringbuf_map_alloc,
.map_free = ringbuf_map_free,
.map_mmap = ringbuf_map_mmap_kern,
.map_poll = ringbuf_map_poll_kern,
.map_lookup_elem = ringbuf_map_lookup_elem,
.map_update_elem = ringbuf_map_update_elem,
.map_delete_elem = ringbuf_map_delete_elem,
.map_get_next_key = ringbuf_map_get_next_key,
.map_mem_usage = ringbuf_map_mem_usage,
.map_btf_id = &ringbuf_map_btf_ids[0],
};As shown above, similar to poll, ringbuf_map_mmap_kern invoked.
static int ringbuf_map_mmap_kern(struct bpf_map *map, struct vm_area_struct *vma)
{
struct bpf_ringbuf_map *rb_map;
rb_map = container_of(map, struct bpf_ringbuf_map, map);
if (vma->vm_flags & VM_WRITE) {
/* allow writable mapping for the consumer_pos only */
if (vma->vm_pgoff != 0 || vma->vm_end - vma->vm_start != PAGE_SIZE)
return -EPERM;
} else {
vm_flags_clear(vma, VM_MAYWRITE);
}
/* remap_vmalloc_range() checks size and offset constraints */
return remap_vmalloc_range(vma, rb_map->rb,
vma->vm_pgoff + RINGBUF_PGOFF);
}ringbuf.c
It takes as input a pointer to the private data, that is, the kernel bpf map that lives or allocated in the kernel space and the virtual memory area vm_area_struct as input that needs to be filled; every virtual memory area in the user space is represented using vm_area_struct.
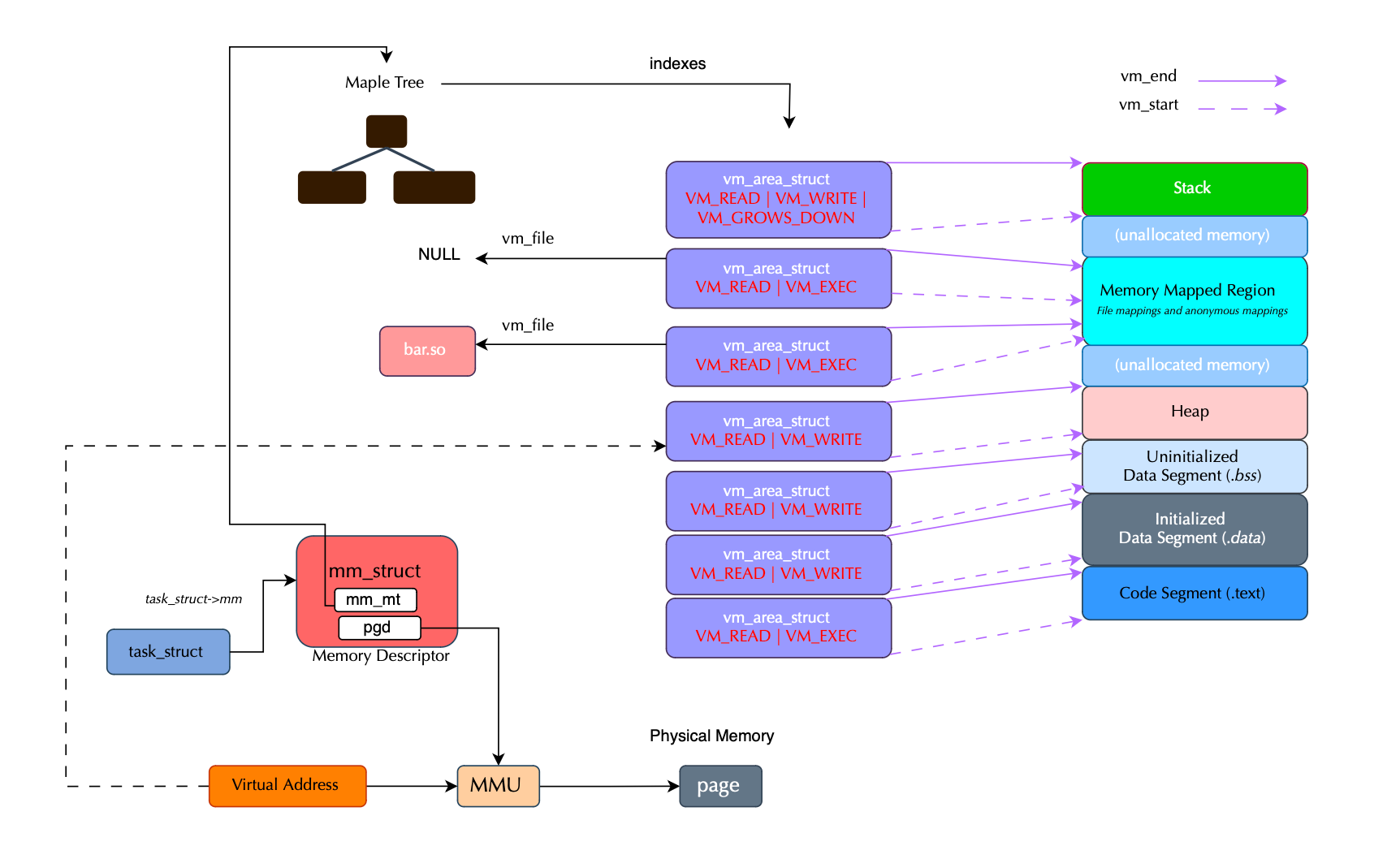
The code retrieves the corresponding ring buffer map (using the container object bpf_map) and maps the physical pages pointed by the kernel memory region into a user-space virtual memory area (vm_area_struct). The RINGBUF_PGOFF value determines the starting point of the mapping as we don't want to map internal fields that the user need not to see and we want to start only from the consumer page.
/* non-mmap()'able part of bpf_ringbuf (everything up to consumer page) */
#define RINGBUF_PGOFF \
(offsetof(struct bpf_ringbuf, consumer_pos) >> PAGE_SHIFT)We will discuss later how to control concurrent writes to the ring buffer.
When the application process wants to write data to a remote peer, through write system call, the kernel copies data to a socket send buffer before transmitting it to the peer. When the kernel receives data, it copies it to the socket’s recv buffer. The data remains in the recv buffer until it gets consumed by the application process through read system call.
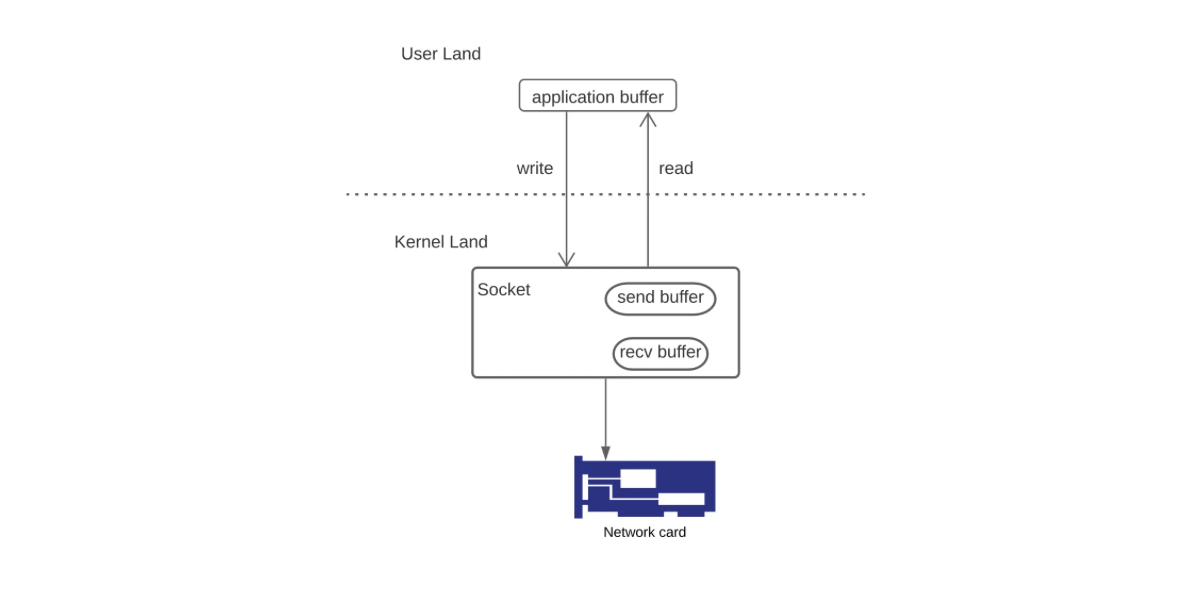
Blocking I/O Model is the default mode for all the sockets under Unix, the process initiates request by invoking recvfrom call, it blocks until data become available and copied from the kernel to the user buffer. In this mode, we are unable to process another descriptor that is ready by this time.
In contrast to Blocking I/O Model, In Non blocking I/O Model invoke recvfrom from time to time, if data is not immediately ready, EWOULDBLOCK error is returned, so we persist (loop) until data is ready, it is called polling. When EWOULDBLOCK is received, the user can decide to continue or to go do other things and come back to continue polling the kernel to see if some operation is ready. This is often a waste of CPU time.
I/O multiplexing is one of the most used model, the model allows to listen and block on a single thread on multiple resources simultaneously without needing to use polling (which wastes CPU cycles) or multithreading (not scalable), and inform the kernel that we want to be notified whenever any one of the channels is ready so that it can process data on that file descriptor (or timeout reached).
To implement I/O multiplexing, in the Unix world, we can use select() or poll(). In the MicrosoftWindowsApi world, it uses WaitForMultipleObjects().
The process blocks on the select call (so not on the I/O system call) by feeding one or more file descriptors that we are interested in (pipes, sockets…). When select returns, it indicates that there are file descriptors ready to be processed, we then call recvfrom to copy data from kernel buffer into our application buffer.
Note that even if we block in both models (Blocking and Multiplexing I/O model), the later has a a key advantage, which is, blocking on multiple file descriptors (like listening socket ect …).
Another, more efficient way to achieve I/O multiplexing is through epoll. Both select and poll require O(n) complexity because the kernel must scan all file descriptors on each call. In contrast, epoll has O(1) complexity as it maintains an internal event-driven mechanism and only returns the ready file descriptors. With select() and poll(), the kernel does not maintain any state about monitored file descriptors, requiring it to recheck all fds on every call. In contrast, with epoll, we create a persistent context in the kernel using epoll_create(). We then use epoll_ctl() to add or modify file descriptors to watch, and finally, we call epoll_wait() to retrieve only the ready file descriptors, avoiding unnecessary scanning. If you look at the libpf code, you will quickly recognize the aforementioned logic:
/* Add extra RINGBUF maps to this ring buffer manager */
int ring_buffer__add(struct ring_buffer *rb, int map_fd,
ring_buffer_sample_fn sample_cb, void *ctx)
{
struct epoll_event *e; <--- this is the epoll_event we create for the ring buffer with map_fd as fd.
tmp = libbpf_reallocarray(rb->events, rb->ring_cnt + 1, sizeof(*rb->events));
if (!tmp)
return libbpf_err(-ENOMEM);
rb->events = tmp; rb->events = tmp; <--- the ring buffer manager houses events so we update it
....
e = &rb->events[rb->ring_cnt];
memset(e, 0, sizeof(*e));
e->events = EPOLLIN;
e->data.fd = rb->ring_cnt;
<------- HERE we add the epoll event to the context using map_fd.
if (epoll_ctl(rb->epoll_fd, EPOLL_CTL_ADD, map_fd, e) < 0) {
err = -errno;
pr_warn("ringbuf: failed to epoll add map fd=%d: %s\n",
map_fd, errstr(err));
goto err_out;
}
To summarize, the ring buffer manager maintains pointers to ring buffers in shared memory with the kernel. These buffers can be accessed either directly or via epoll, as we have already populated the epoll context with the map’s file descriptors.
eBPF programs deployed in the kernel collect a sheer amount of data, and this data needs to be pulled into user space. In the naive, traditional approach, if one wants to read data from the kernel, say, from a file, the data must first be loaded into the kernel address space and then ultimately transferred to user space. Each process has its own address space, which is separate from kernel space.
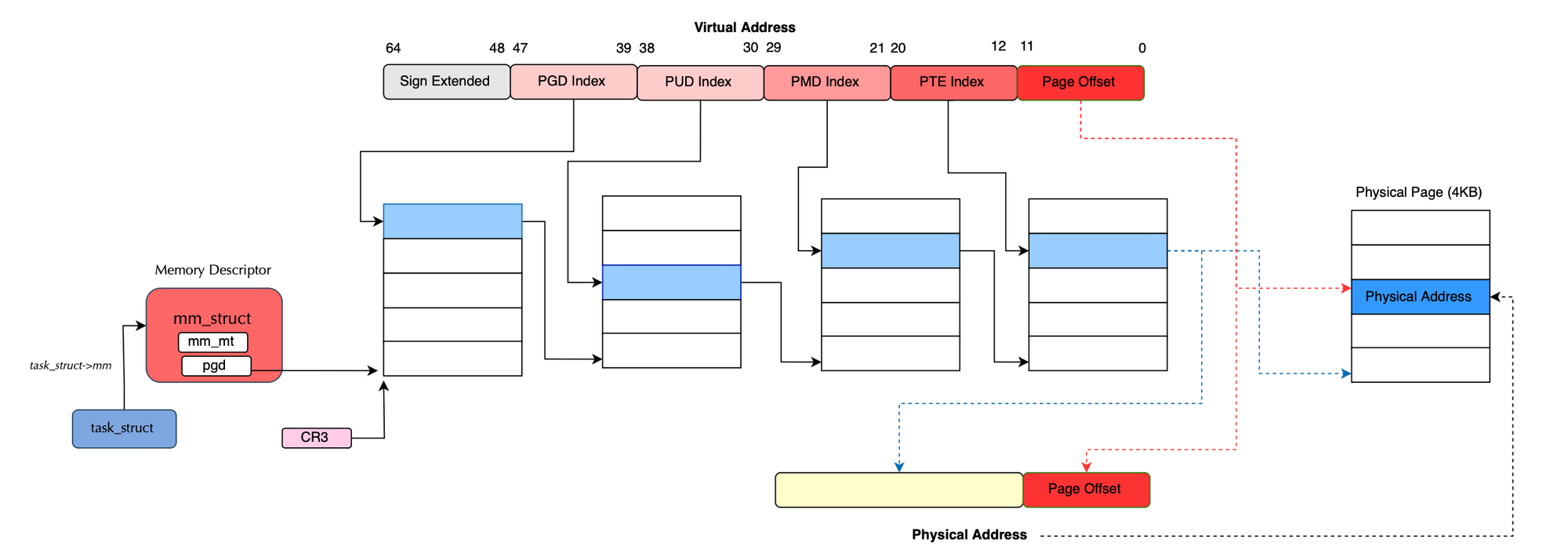
Direct access to kernel memory is not allowed because the CPU, specifically the MMU, enforces privilege levels on memory pages. Typically, to access kernel data, you must request the kernel to copy it to your user-space buffer. This buffer, residing in kernel space, is managed by the kernel and can be identified using a file descriptor.
In Linux, everything is treated as a file, so whether you're working with a socket, file, or other resources, you need a file descriptor, a non-negative integer that uniquely identifies the kernel resource.
If you want to read data from a kernel buffer, such as a ring buffer, you need to transfer it from the kernel buffer to the user buffer. However, this approach does not scale efficiently in streaming mode. Continuously issuing read/write system calls is prohibitively expensive and significantly degrades system performance.
Additionally, the physical memory used during a copy operation is twice the size of the data object being manipulated. This means that if you're collecting large volumes of data, you would quickly run out of memory. In other words, to achieve efficient data transfer, we need to reduce context switching and memory copying.
Instead of maintaining two separate buffers and copying data between user space and kernel space each time, why not just have 1 ring buffer and let the kernel share it with user space? thereby reducing kernel context switching. This is the idea behind using mmap also known to as zero-copy.
With mmap, we avoid calling read() and write() each time we want to access data from, say, a file. Instead, we get a direct a virtual memory address range sharing the same physical pages as the kernel.
Mmap allows us to map not only files but also any kernel object in memory (using its file descriptor) to a process's address space.
With ring buffers, the kernel creates a kernel object and provides user space with a file descriptor. Then, the user-space library can use mmap to map a section of virtual memory in kernel space to the same physical memory.
Both buffers (kernel and user space) point to the same physical memory or pages but use different virtual addresses because kernel space and user space have separate virtual memory tables.
The mmap() function is defined as follows:
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
if (offset_in_page(off) != 0)
return -EINVAL;
return ksys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
}void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
Where fd is the file descriptor, offset is the offset in kernel space (must be a multiple of the page size), prot is protection flags (e.g., read/write permissions). The function returns a pointer to the mapped region (start address of virtual memory area struct), allowing user-space libraries to access data directly using the virtual address (the cpu or mmu will cope with address conversion). This eliminates the need to callread() and write() system calls every time data is accessed. I will post a detailed article about how mmap works soon.
Many high-performance applications rely on zero-copy techniques, including Apache Kafka and Spring WebFlux/Netty.
Singular bpf ring buffer should be housed in the .maps ELF section, with libpfb you can define it as follows:
struct
{
__uint (type, BPF_MAP_TYPE_RINGBUF);
__uint (max_entries, 256 * 4096);
} events SEC (".maps")SEC (".maps") is used to place the anonymous structure in the .maps section of the elft, it is defined as follows:
#define SEC(NAME) __attribute__((section(NAME), used))The max_entries specifies the size of the buffer in bytes and should be multiple of the page size (e.g 4096, 8192). The __uint is a macro defined as follows:
#define __uint(name, val) int (*name)[val]
We live in an era where both compilers and CPUs are clever and highly optimized and can sometimes unintentionally break concurrent programs. In shared memory systems, they can reorder memory operations executing instructions out of order which can lead to unpredictable or undesirable results.
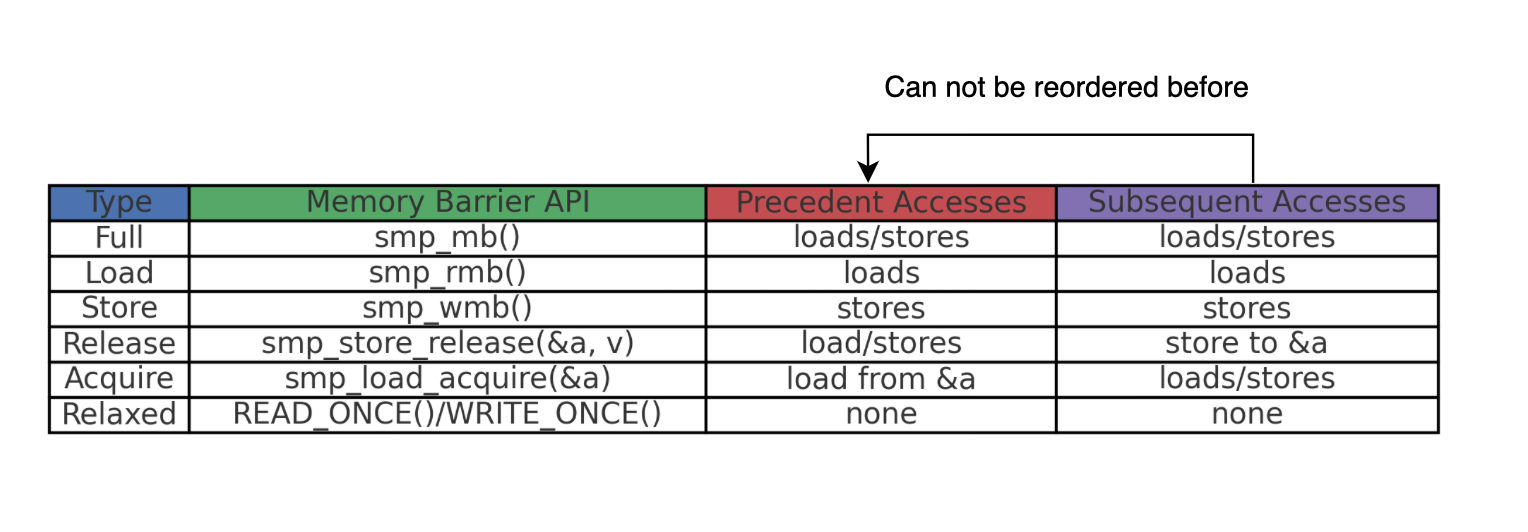
To avoid such issues, low-level programmers should rely on high-level primitives provided by the kernel to enforce acquire-release semantics between user-space and kernel-space code i.e enforce happens-before. Specifically, smp_load_acquire for reads and smp_store_release for writes are typically used to achieved happens-before semantic and synchronize the reader and the writer.
I have written a detailed post on this topic: https://www.deep-kondah.com/on-the-complexity-of-synchronization-memory-barriers-locks-and-scalability/, feel free to check it out!
There are two main ways to write data to a ring buffer. Using the bpf_ringbuf_output API (similar to the older bpf_perf_event_output). However, this requires the data to be already present in memory either on the stack (which is limited in size) or in a BPF per-CPU array, both of which involve a single memory copy.
bpf_ringbuf_reserve / bpf_ringbuf_submit / bpf_ringbuf_discard allows reserving space in the ring buffer and writing to it directly, achieving zero-copy. Additionally, there is an API for dynamically sized data bpf_ringbuf_reserve_dynptr. At any time, before committing, the writer can also discard reserved data (which advances the counter and sets the header bit signaling to the reader to ignore the data using the BPF_RINGBUF_DISCARD_BIT flag. Since multiple producers may write to the buffer simultaneously, updates are serialized under a spinlock to prevent data races.
Let's take a look at what happens behind the scenes. When a BPF program invokes bpf_ringbuf_reserve, it already has a pointer to the BPF map (see the definition section). More specifically, it holds a pointer to struct bpf_map *, which represents the ring buffer map in the kernel.
BPF_CALL_3(bpf_ringbuf_reserve, struct bpf_map *, map, u64, size, u64, flags)
{
struct bpf_ringbuf_map *rb_map;
if (unlikely(flags))
return 0;
rb_map = container_of(map, struct bpf_ringbuf_map, map);
return (unsigned long)__bpf_ringbuf_reserve(rb_map->rb, size);
}What happens internally is the pointer to the ring buffer map is obtained and then delegated to __bpf_ringbuf_reserve, see code snippet below. Notice the use of acquire-release semantics, which ensures synchronization between the consumer and producer without a lock, this is known as lock-free programming. Additionally, READ_ONCE is used to defeat compiler optimizations and safely read data (because it may happen that another core reserved data and we need to see it).
static void *__bpf_ringbuf_reserve(struct bpf_ringbuf *rb, u64 size)
{
unsigned long cons_pos, prod_pos, new_prod_pos, pend_pos, flags;
struct bpf_ringbuf_hdr *hdr;
u32 len, pg_off, tmp_size, hdr_len;
if (unlikely(size > RINGBUF_MAX_RECORD_SZ))
return NULL;
len = round_up(size + BPF_RINGBUF_HDR_SZ, 8);
if (len > ringbuf_total_data_sz(rb))
return NULL;
cons_pos = smp_load_acquire(&rb->consumer_pos); // Acquire semantic
if (in_nmi()) {
if (!raw_spin_trylock_irqsave(&rb->spinlock, flags))
return NULL;
} else {
raw_spin_lock_irqsave(&rb->spinlock, flags);
}
pend_pos = rb->pending_pos;
prod_pos = rb->producer_pos;
new_prod_pos = prod_pos + len;
while (pend_pos < prod_pos) {
hdr = (void *)rb->data + (pend_pos & rb->mask);
hdr_len = READ_ONCE(hdr->len);
if (hdr_len & BPF_RINGBUF_BUSY_BIT)
break;
tmp_size = hdr_len & ~BPF_RINGBUF_DISCARD_BIT;
tmp_size = round_up(tmp_size + BPF_RINGBUF_HDR_SZ, 8);
pend_pos += tmp_size;
}
rb->pending_pos = pend_pos;
/* check for out of ringbuf space:
* - by ensuring producer position doesn't advance more than
* (ringbuf_size - 1) ahead
* - by ensuring oldest not yet committed record until newest
* record does not span more than (ringbuf_size - 1)
*/
if (new_prod_pos - cons_pos > rb->mask ||
new_prod_pos - pend_pos > rb->mask) {
raw_spin_unlock_irqrestore(&rb->spinlock, flags);
return NULL;
}
hdr = (void *)rb->data + (prod_pos & rb->mask);
pg_off = bpf_ringbuf_rec_pg_off(rb, hdr);
hdr->len = size | BPF_RINGBUF_BUSY_BIT;
hdr->pg_off = pg_off;
/* pairs with consumer's smp_load_acquire() */
smp_store_release(&rb->producer_pos, new_prod_pos);
raw_spin_unlock_irqrestore(&rb->spinlock, flags);
return (void *)hdr + BPF_RINGBUF_HDR_SZ;
}First, the system atomically reads the consume_pos and then attempts to acquire the spinlock. To ensure that only one CPU core modifies rb->data at a time, the kernel uses spinlocks, by keeping the CPU in a busy or wait loop until the lock is released by the owner. If we are in an NMI context, raw_spin_trylock_irqsave is selective, which avoids spinning, because you just can't block (this also means that data is not guaranteed to be reserved -> data loss). Otherwise, we use raw_spin_lock_irqsave(cf https://github.com/torvalds/linux/blob/master/include/linux/spinlock.h) , a more expensive spinlock that disable local interrupts and preemption and involves active spinning.
if (in_nmi()) {
if (!raw_spin_trylock_irqsave(&rb->spinlock, flags))
return NULL;
} else {
raw_spin_lock_irqsave(&rb->spinlock, flags);
}Once and if the lock is acquired, the header is populated and the producer_pos is incremented atomically with the surfaced size (note that the data is still not written, as indicated by BPF_RINGBUF_BUSY_BIT). The bitmask & rb->mask ensures wraparound (i.e modulo).
hdr = (void *)rb->data + (prod_pos & rb->mask);
...
rb->mask = data_sz - 1;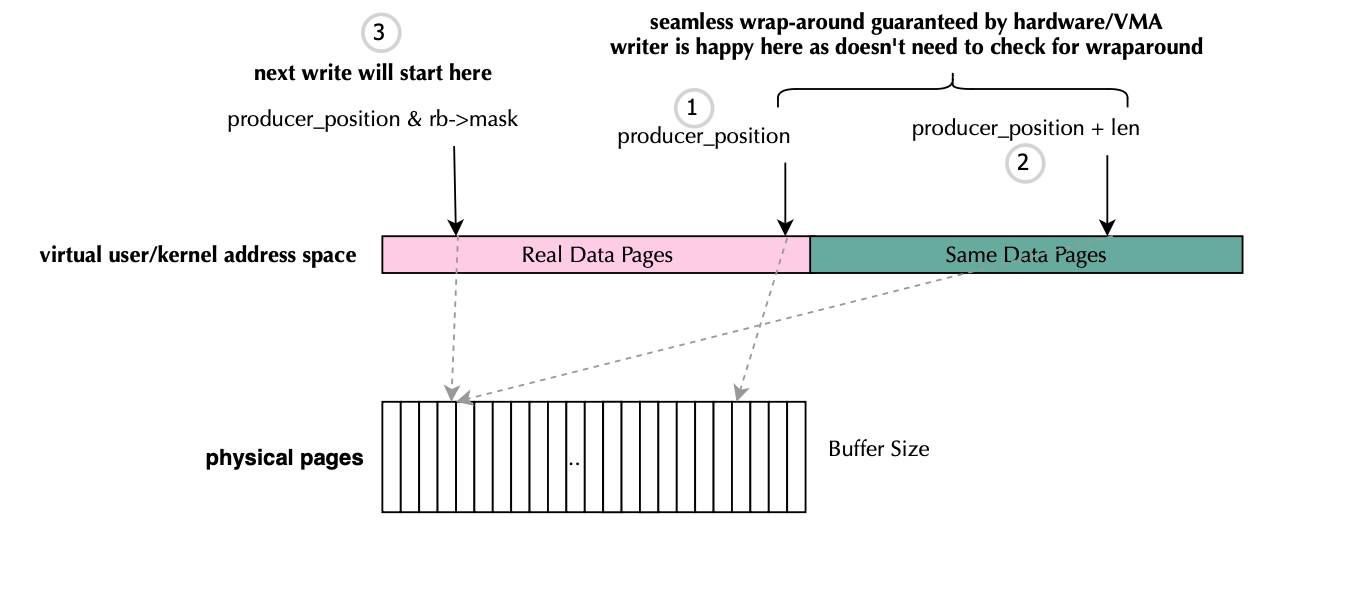
It then returns a direct pointer to the kernel virtual address space, allowing the BPF program to write data without caring too much about the underlying ring buffer structure.
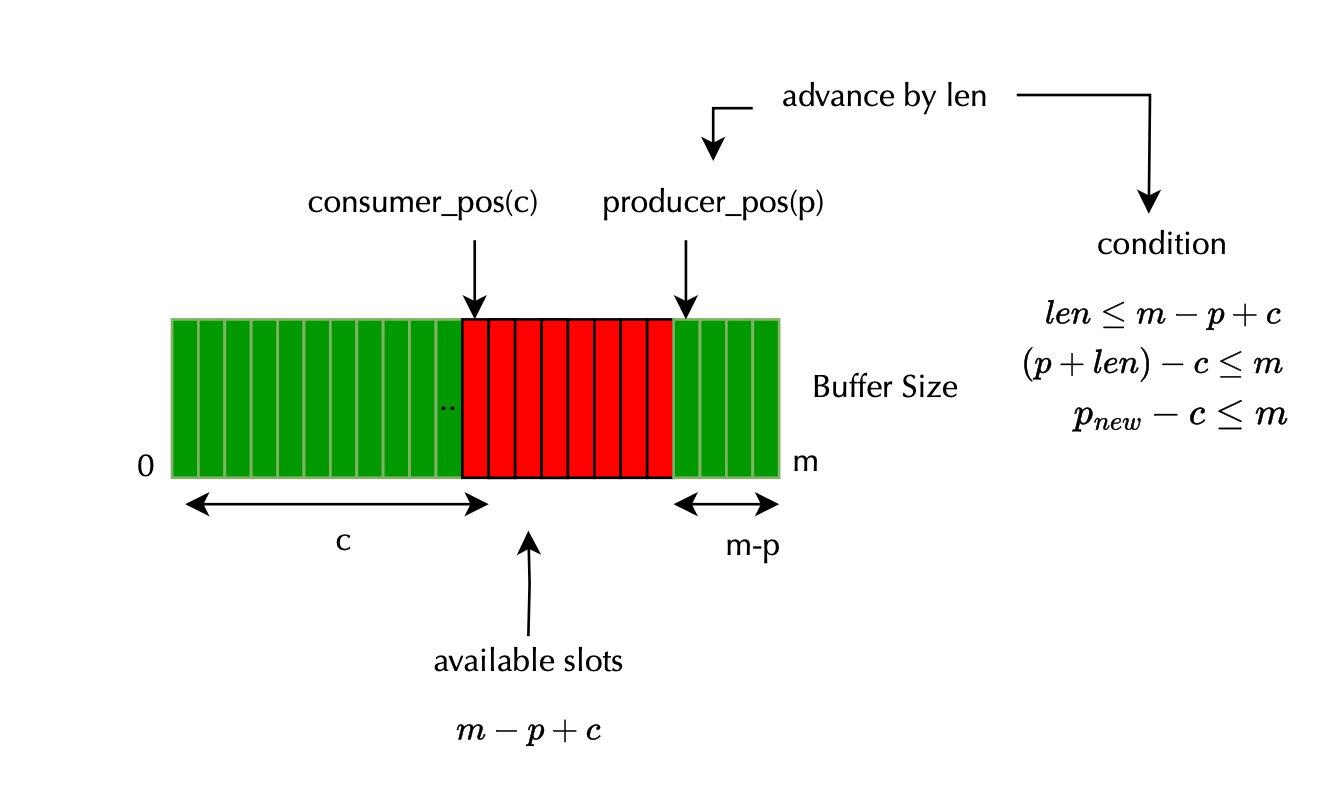
Here is the code that checks whether we have available slots. I also added a virtual illustration (without loss of generality, assuming there is no pending store).
if (new_prod_pos - cons_pos > rb->mask ||
new_prod_pos - pend_pos > rb->mask) {
raw_spin_unlock_irqrestore(&rb->spinlock, flags);
return NULL;
}
Next, the BPF program writes directly to the reserved space and commits using bpf_ringbuf_commit. At this stage, there is no need to acquire the spinlock since the producer_pos has already been updated atomically. The commit operation simply writes the data, finalizes the header with the correct length (using atomic exchange).
static void bpf_ringbuf_commit(void *sample, u64 flags, bool discard)
{
unsigned long rec_pos, cons_pos;
struct bpf_ringbuf_hdr *hdr;
struct bpf_ringbuf *rb;
u32 new_len;
hdr = sample - BPF_RINGBUF_HDR_SZ;
rb = bpf_ringbuf_restore_from_rec(hdr);
new_len = hdr->len ^ BPF_RINGBUF_BUSY_BIT;
if (discard)
new_len |= BPF_RINGBUF_DISCARD_BIT;
/* update record header with correct final size prefix */
xchg(&hdr->len, new_len);
/* if consumer caught up and is waiting for our record, notify about
* new data availability
*/
rec_pos = (void *)hdr - (void *)rb->data;
cons_pos = smp_load_acquire(&rb->consumer_pos) & rb->mask;
if (flags & BPF_RB_FORCE_WAKEUP)
irq_work_queue(&rb->work);
else if (cons_pos == rec_pos && !(flags & BPF_RB_NO_WAKEUP))
irq_work_queue(&rb->work);
}Finally, it triggers a wake-up for the user process using irq_work_queue(&rb->work), either if the surfaced flag is set to BPF_RB_FORCE_WAKEUP, or if the consumer has caught up and is waiting for our record (i.e., consume_pos matches the newly committed position. The consumer position is read safely using acquire semantic.
Specifically, readers wake up via irq_work_queue , which delegates to bpf_ringbuf_notify,set during the initialization of the map:
init_irq_work(&rb->work, bpf_ringbuf_notify);and as shown below bpf_ringbuf_notify wake up poll/epoll registered readers.
static void bpf_ringbuf_notify(struct irq_work *work)
{
struct bpf_ringbuf *rb = container_of(work, struct bpf_ringbuf, work);
wake_up_all(&rb->waitq);
}The code for bpf_ringbuf_output is shown below. It uses __bpf_ringbuf_reserve and bpf_ringbuf_commit.
BPF_CALL_4(bpf_ringbuf_output, struct bpf_map *, map, void *, data, u64, size,
u64, flags)
{
struct bpf_ringbuf_map *rb_map;
void *rec;
if (unlikely(flags & ~(BPF_RB_NO_WAKEUP | BPF_RB_FORCE_WAKEUP)))
return -EINVAL;
rb_map = container_of(map, struct bpf_ringbuf_map, map);
rec = __bpf_ringbuf_reserve(rb_map->rb, size);
if (!rec)
return -EAGAIN;
memcpy(rec, data, size);
bpf_ringbuf_commit(rec, flags, false /* discard */);
return 0;
}Now, let's examine how user-space code can consume events.
As discussed in an earlier section, the ring buffer manager maintains ring buffers. To read data from them, ring_buffer__consume_n is used, as shown below:
int ring_buffer__consume_n(struct ring_buffer *rb, size_t n)
{
int64_t err, res = 0;
int i;
for (i = 0; i < rb->ring_cnt; i++) {
struct ring *ring = rb->rings[i];
err = ringbuf_process_ring(ring, n);
if (err < 0)
return libbpf_err(err);
res += err;
n -= err;
if (n == 0)
break;
}
return res > INT_MAX ? INT_MAX : res;
}ring_buffer__consume_n iterates over the ring array (ring_cnt buffers, one for each created buffer) and invokes the callback function registered via ring_buffer_sample_fn when calling ring_buffer__new. This callback is responsible for handling data.
As shown below, the libbpf library automatically updates the consumer’s buffer position. Once again, acquire-release semantics are used to synchronize with the producer, ensuring correct ordering of memory operations (if you remember earlier producer updated len atomically using xchg, cache line will be invalidated and thus the consumer needs to use acquire barrier to force the processing of invalidation messages).
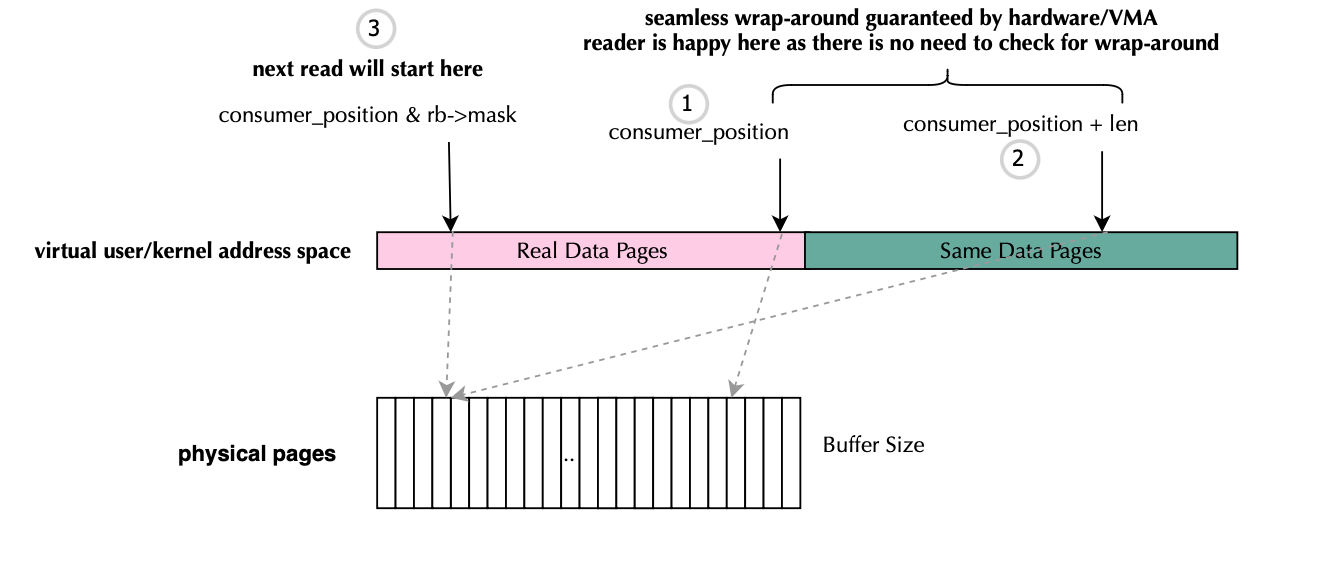
static int64_t ringbuf_process_ring(struct ring *r, size_t n)
{
int *len_ptr, len, err;
/* 64-bit to avoid overflow in case of extreme application behavior */
int64_t cnt = 0;
unsigned long cons_pos, prod_pos;
bool got_new_data;
void *sample;
cons_pos = smp_load_acquire(r->consumer_pos);
do {
got_new_data = false;
prod_pos = smp_load_acquire(r->producer_pos);
while (cons_pos < prod_pos) {
len_ptr = r->data + (cons_pos & r->mask);
len = smp_load_acquire(len_ptr);
/* sample not committed yet, bail out for now */
if (len & BPF_RINGBUF_BUSY_BIT)
goto done;
got_new_data = true;
cons_pos += roundup_len(len);
if ((len & BPF_RINGBUF_DISCARD_BIT) == 0) {
sample = (void *)len_ptr + BPF_RINGBUF_HDR_SZ;
err = r->sample_cb(r->ctx, sample, len);
if (err < 0) {
/* update consumer pos and bail out */
smp_store_release(r->consumer_pos,
cons_pos);
return err;
}
cnt++;
}
smp_store_release(r->consumer_pos, cons_pos);
if (cnt >= n)
goto done;
}
} while (got_new_data);
done:
return cnt;
}
Once the data is consumed, the consumer advances using release barrier preventing LoadStore reordering.
Data can also be consumed via polling where execution is delegated to ringbuf_process_ring to invoke the registered callback.
int ring_buffer__poll(struct ring_buffer *rb, int timeout_ms)
{
int i, cnt;
int64_t err, res = 0;
cnt = epoll_wait(rb->epoll_fd, rb->events, rb->ring_cnt, timeout_ms);
if (cnt < 0)
return libbpf_err(-errno);
for (i = 0; i < cnt; i++) {
__u32 ring_id = rb->events[i].data.fd;
struct ring *ring = rb->rings[ring_id];
err = ringbuf_process_ring(ring, INT_MAX);
if (err < 0)
return libbpf_err(err);
res += err;
}
if (res > INT_MAX)
res = INT_MAX;
return res;
}
What differs from the previous approach is the following call:
cnt = epoll_wait(rb->epoll_fd, rb->events, rb->ring_cnt, timeout_ms);
which blocks on all fds (buffers if you want) until some data is ready. The BPF program determines whether the wake-up should be immediate or delayed.
In this section, we use what we learned in this post to demonstrate how to populate a ring buffer using the libpf API. The code is available in github: https://github.com/mouadk/ebpf-ringbuffer/tree/main.
The ring buffer will be populated with samples that have the following structure: a process id, a task command, and a filename.
struct event {
u32 pid;
char comm[TASK_COMM_LEN];
char filename[FILE_NAME_LEN];
};Next, we declare our ring buffer map:
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 16);
} events SEC(".maps");Finally, we hook into the openat system call and provide a handler (probe) that will 1.reserve space inside the ring buffer using e = bpf_ringbuf_reserve(&events, sizeof(*e), 0);. 2. If the reservation succeeds, populate the reserved memory using the event structure. 3.Use the BPF helper function bpf_probe_read_user_str to populate the filename field. Finally commit the sample to make it readable with bpf_ringbuf_submit. Here is the corresponding BPF program:
SEC("tracepoint/syscalls/sys_enter_openat")
int handle_openat(struct trace_event_raw_sys_enter *ctx) {
struct event *e;
const char *filename;
e = bpf_ringbuf_reserve(&events, sizeof(*e), 0);
if (!e) return 0;
e->pid = bpf_get_current_pid_tgid() >> 32;
bpf_get_current_comm(&e->comm, sizeof(e->comm));
filename = (const char *)ctx->args[1];
bpf_probe_read_user_str(e->filename, sizeof(e->filename), filename);
bpf_ringbuf_submit(e, 0);
return 0;
}Now that we have our BPF program, we need to load and deploy it using the Libpf BPF CO-RE. We first compile the program using clang ... -c src/syscall.bpf.c -o build/syscall.bpf.o. Next, generate a skeleton using bpftool gen skeleton build/syscall.bpf.o > src/syscall.skel.h.
The loader and collector code is shown below:
#include <stdio.h>
#include <stdlib.h>
#include "syscall.skel.h"
#include "signal.h"
#include "bpf.h"
#include "libbpf.h"
#define LOG_FILE "file_access.log"
#define TASK_COMM_LEN 16
#define FILE_NAME_LEN 256
struct event {
int pid;
char comm[TASK_COMM_LEN];
char filename[FILE_NAME_LEN];
};
static volatile sig_atomic_t exiting = 0;
static void on_sig(int sig) {
exiting = 1;
}
static int handle_event(void *ctx, void *data, size_t data_size) {
struct event *e = (struct event *)data;
FILE *file = fopen(LOG_FILE, "a");
if (!file) {
perror("Failed to open log file");
return 0;
}
fprintf(file, "pid=%d, comm=%s, filename=%s\n", e->pid, e->comm, e->filename);
fflush(file);
fclose(file);
return 0;
}
int main(int argc, char **argv) {
struct syscall_bpf *skel;
struct ring_buffer *rb;
fprintf(stdout, "ebpf loader starting...\n");
signal(SIGINT, on_sig);
signal(SIGTERM, on_sig);
skel = syscall_bpf__open_and_load();
if (!skel) {
fprintf(stderr, "failed to load BPF program.\n");
return 1;
}
if (syscall_bpf__attach(skel)) {
fprintf(stderr, "failed to attach BPF program.\n");
goto teardown;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "failed to create ring buffer.\n");
goto teardown;
}
printf("successfully started, events are logged at %s, press Ctrl+C to exit.\n", LOG_FILE);
while (!exiting) {
int err = ring_buffer__poll(rb, 100);
//printf(poll returned %d, exiting=%d\n", err, exiting);
if (err < 0 && err != -EINTR) {
fprintf(stderr, "ring_buffer__poll() failed: %d\n", err);
break;
}
}
teardown:
printf("shutting down...:)\n");
ring_buffer__free(rb);
syscall_bpf__destroy(skel);
return 0;
}
Finally, we compile the collector using gcc.
gcc -o build/collector src/collector.c ...Then, we deploy it.
./build/collector
The collector outputs logs to a log file. You can open the file and check the logged entries inside file_access.log.

You can reproduce above output using the docker file in https://github.com/mouadk/ebpf-ringbuffer/tree/main.
In this post, we discussed the ring buffer data structure in eBPF and how the kernel shares memory pages with user space to efficiently consume data. We also explored how a double-mapped ring buffer drastically reduces the complexity of reading from and writing to the buffer. Additionally, we covered data space reservation and spin locks used to synchronize access to the ring buffer.
In the next post, I will discuss how provenance graphs can be built using eBPF probing and how security solutions, including Falco and SysFlow, leverage eBPF for security, and how to apply taint propagation and machine learning to provenance graphs i.e specification and learning-based provenance IDs.
BPF ring buffer: https://nakryiko.com/posts/bpf-ringbuf/
eBPF Docs: https://docs.ebpf.io
BPF ring buffer : https://www.kernel.org/doc/html/v6.6/bpf/ringbuf.html
Memory barriers for TSO architectures: https://lwn.net/Articles/576486/
BPF CO-RE reference guide: https://nakryiko.com/posts/bpf-core-reference-guide/

