
Writing performant, portable, and correct parallel programs in multiprocessor systems or SMP, where each processor may load and store to a single shared address space, is not trivial. Programmers must be aware of the underlying memory semantics, i.e. the system optimizations performed by the clever beast hardware or cpu.


Writing performant, portable, and correct parallel programs in multiprocessor systems or SMP, where each processor may load and store to a single shared address space, is not trivial. Programmers must be aware of the underlying memory semantics, i.e. the system optimizations performed by the clever beast hardware or cpu. Failure to understand the complex specifications of the memory consistency model can lead to errors and counterintuitive results. Even when code is properly synchronized and fenced by experts, bugs can still exist and are often very difficult to detect.
One expects memory accesses to be executed in the same order defined in the source or program code, but this is not always the case. In modern multiprocessor shared-memory systems, CPUs employ out-of-order execution to optimize performance and reduce pipeline stalls, effectively hiding memory latency.
According to Moore’s law, the number of transistors on a microchip doubles roughly every two years, allowing CPU speeds to continue increasing while memory access speeds lag behind. To mitigate this disparity, CPU architectures introduced caches , duplicating data backed in main memory, thereby achieving faster access.
Unfortunately, without careful programming, memory reordering introduced mainly by caching structures can lead to aberrant and surprising behaviors, compromising both the reliability and security of software. The chief example is the Linux kernel which runs on SMP machines.
In addition to the CPU, the compilers can also disrupt the apparent order of operations and violate sequential consistency when synchronization primitives or barriers/fences are absent.
This article will equip you with at least a basic understanding of mechanisms for achieving scalable synchronization in shared memory systems. It covers how to effectively protect critical sections where multiple parallel contexts (e.g user and kernel) operate on the same shared data structure and how to ensure predictable results in multithreaded environments. As we will discuss later, performance metrics for scalable locks, with respect to cores, include the space complexity, time to acquire the lock in the absense of contention, the consumed bus cycles or generated traffic during lock handover, and fairness.
I discovered memory barriers and cpu caching gymnastics while reading the kernel source code for eBPF, specifically in the implementation of ring buffers (my post about it is almost finished, including using eBPF as a data source for training machine learning models for cybersecurity, more specifically for provenance graphs or PIDSs).
Understanding the kernel code requires to understand several topics, including memory consistency, cache coherence, memory barriers etc. That's why I decided to write a post about these topics.
I have also shared a simple code illustrating how memory reordering could lead to aberrant executions: https://github.com/mouadk/memory_havoc.
Recently, I was learning about the internals of eBPF and discovered that a ring buffer or circular buffers can be implemented without requiring a lock to serialize communication between the writer and the reader (i.e allowing concurrent read/write). This is achieved using memory barriers or more specifically acquire and release semantics (main topic of today). Mutual exclusion is achieved using spin locks (to sync multiple writers), which internally rely on memory barriers to prevent instruction reordering around synchronization primitives. That is, they ensure that code execution is not reordered around lock/unlock operations, thereby preventing data races.
As soon as data is shared between processors, the communication becomes error prone. Whether through global variables or shared memory via mmap ie physical pages shared between the kernel and user-space processes, serialization and low-level atomic operations become necessary.
Basically the source program order refers to the sequence of memory instructions (loads and stores) written by the programmer. Once the source program is compiled into assembly code, the compiler may reorder memory instructions and other kind of optimizations (as long as specific dependencies are respected). For example, it may load a shared memory variable into a temporary register (e.g., inside a loop). It would be foolish to assume that the generated assembly code will always match the exact source code order, the compiler can even eliminate code.
Once code is compiled, it is then handed over to the CPU for execution. The CPU, in turn, is allowed to reorder instructions at runtime provided program's causal dependencies are correctly maintained. As a result, the execution order at runtime can differ from both the source program order and the compiled program order, due to optimizations performed by both the compiler and the CPU.
The moment you start sharing data between CPU cores, memoring ordering becomes important and the CPU needs instructions or memory barriers to enforce strict ordering (same for the compiler).
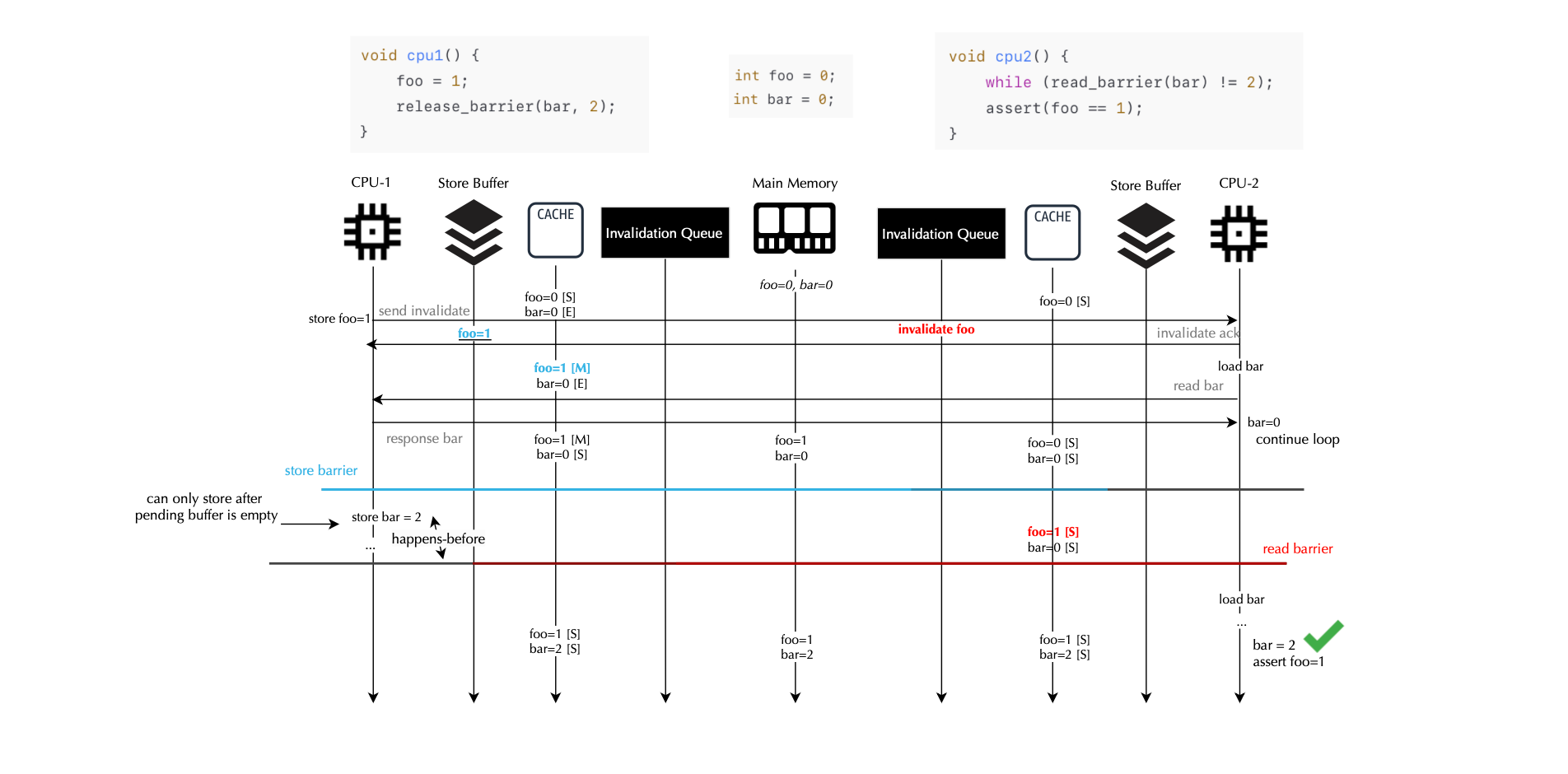
To better illustrate why this is important, consider a standard circular buffer. On one end, you have a consumer waiting for a signal (i.e., for the producer position to advance) in order to update the read the data and update consumer position (e.g., sending it to remote storage or simply logging it). The consumer reads data that is physically mapped to the same memory pages as the producer (the virtual memory area in the user address space maps to the same physical pages the kernel is using; this can be achieved usingmmap). Meanwhile, the producer writes data to the buffer and advances the producer position to signal to the consumer that new data has been added.
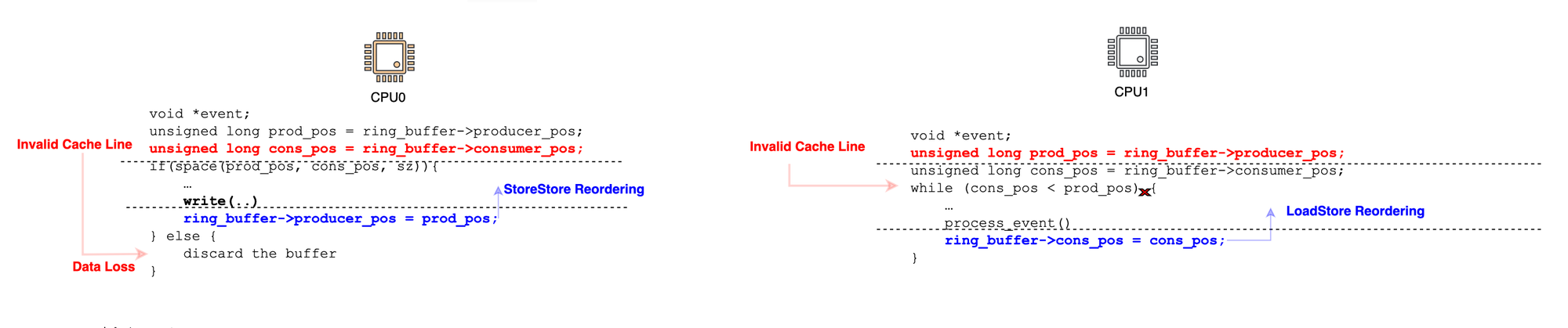
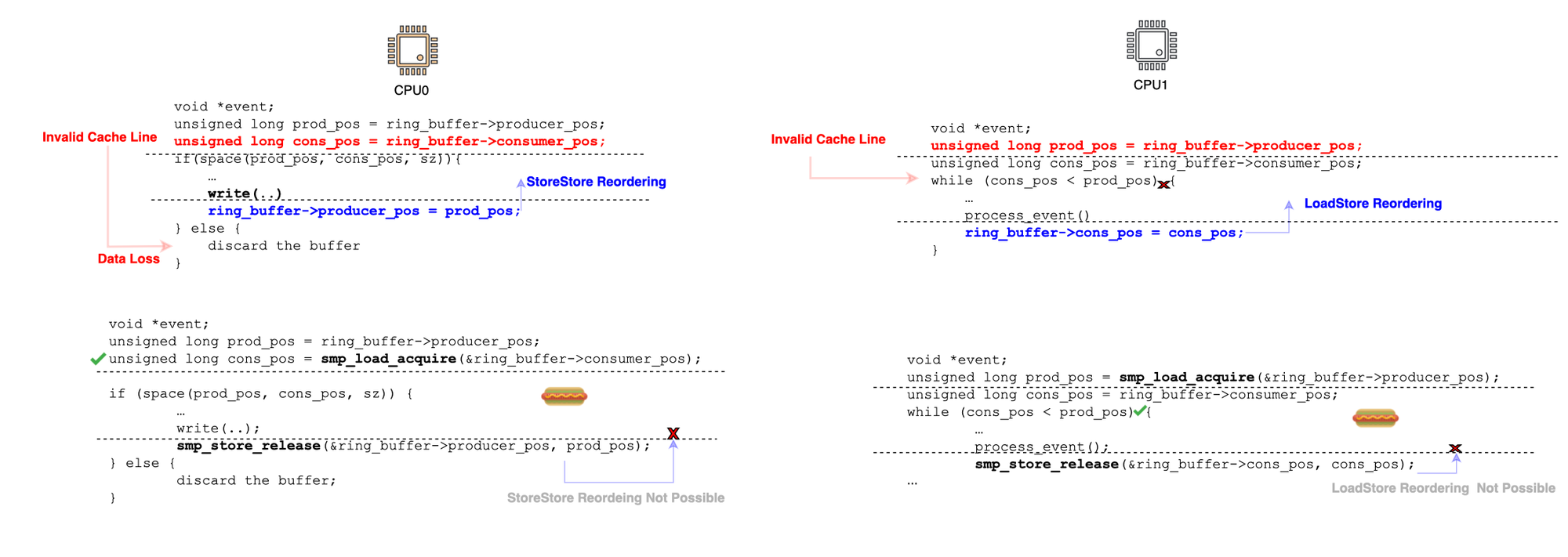
Suppose the producer is running on CPU0 and the consumer on CPU1. At some point, the consumer advances the consumer position and sends an invalidation message. However, CPU0 may place this invalidation in a queue and process it later. This means that if CPU0 is not explicitly instructed to synchronize, it may still use an old, stale cache line corresponding to the consumer position, incorrectly thinking that there is no available space (LoadLoad reordering), thereby discarding data. A similar issue occurs on CPU1 the producer may advance its position, but CPU1 may not immediately see the updated producer position and incorrectly assume the buffer is empty. Another issue is StoreStore reordering. Since the CPUs do not inherently recognize a data dependency between the consumer position and the data being written to the buffer, the producer may update the producer position before the actual data is fully written. This could cause the consumer to read uninitialized or garbage data. Similarly, CPU1 can experience LoadStore reordering in the absence of memory barriers. The consumer position could be prematurely committed, leading to a scenario where the producer overwrites data that the consumer has not yet processed.
The solution is to use memory barriers, specifically acquire/release primitives (sometimes also referred as happens-before), to properly synchronize the critical code. The fix is illustrated below, and we will later discuss what happens under the hood.
Compilers and CPUs, as long as they operate within their rights, can reorder instructions. By rights, we mean that, for the programmer, the sequence of execution should appear consistent with the source code. As long as control and data dependencies are met, the CPU is free to perform its own secret wizardry to stay entertained, and we usually don’t need to worry about the acrobatics performed by the hardware for single-threaded programs.
However, if a program accesses data shared by other programs or multiple CPUs, and the compiler or CPU is not explicitly instructed to enforce specific load and store ordering, the code can break.
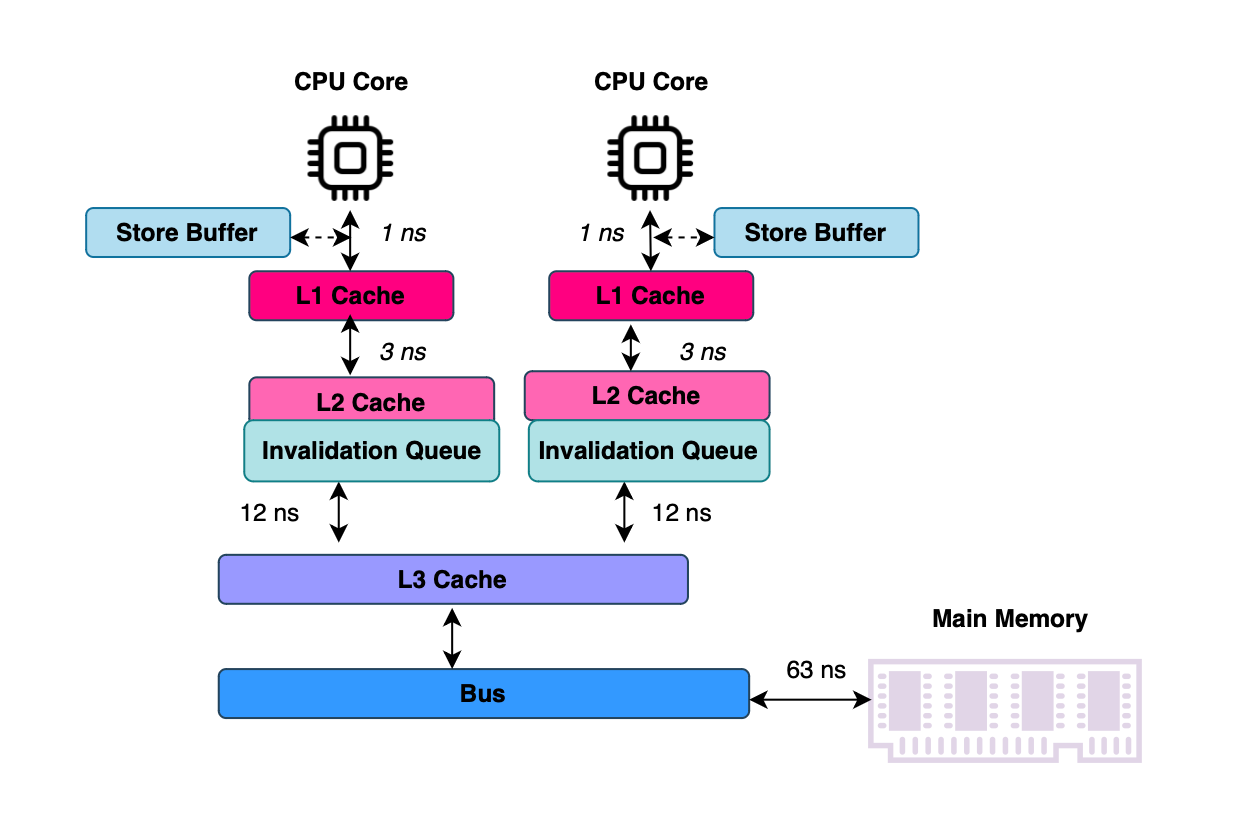
CPUs can execute instructions in a different order than developers define (to fully utilize CPU’s potential), but they must always ensure that execution appears to follow the order specified in the source code. Due to the significant speed imbalance between the CPU and main memory (e.g., fetching data from main memory takes around tens of nanoseconds, while a CPU can execute multiple instructions per nanosecond), hardware designers introduced several optimizations, including caching layers, store buffers, and invalidate queues, to maximize performance and keep CPUs as busy as possible.
The problem arises when kernel engineers or low-level programmers (e.g JVM devs) do not fully understand how CPUs load and store data or how memory consistency protocols work. Without this understanding, a system may not fully prevent data loss and data inconsistencies; something paramount in cybersecurity domain.
There is a principle that most kernel developers are probably familiar with program locality, which encompasses both temporal and spatial locality. When a program operates on a piece of data, there is a high probability that the same memory location will be accessed again soon; this is known as temporal locality. Additionally, if a program accesses one variable, there is a high probability that variables located near that memory address will be accessed soon, this is referred to as spatial locality.
Memory in multi-processor systems is composed of several structures, one of the most important being CPU caches, typically three: L1, L2, and L3. L1 and L2 are usually not shared among cores and are exclusive to each CPU.
When a program, whether in user or kernel space, tries to access memory using a virtual address, the address is first translated into a physical address. The CPU then checks whether there is a cache line housing the requested data. If the caching layers do not contain the data, it is fetched from main memory, which is significantly slower.
Once retrieved, the data is stored in the cache so that if the CPU requests it again, it will either be in its cache layer or possibly in another CPU's cache.
Data between memory and CPU caches circulates in the form of blocks or cache lines. That is, when a CPU core requests data at a specific physical address, the entire block (cache line) containing that address is loaded into the cache, even if only one byte is requested. This behavior is motivated by spatial and temporal locality we presented earlier.
Here is how to check the cache line size in Mac OS (always a power of 2):

The cache consists of different sets or groups, with each set containing several entries called cache lines (generally k cache lines per-set are used in a k-way associative cache model, in a direct mapped or 1-way associative cache each set contains 1 cache line). A cache line is composed of the payload (data), a valid bit indicating whether the cache line contains valid data, and a tag (which I will explain shortly). The total cache size is given by E × S × B bytes, where E is the number of sets, S is the number of cache lines per set and B is the size of each cache line (in bytes).
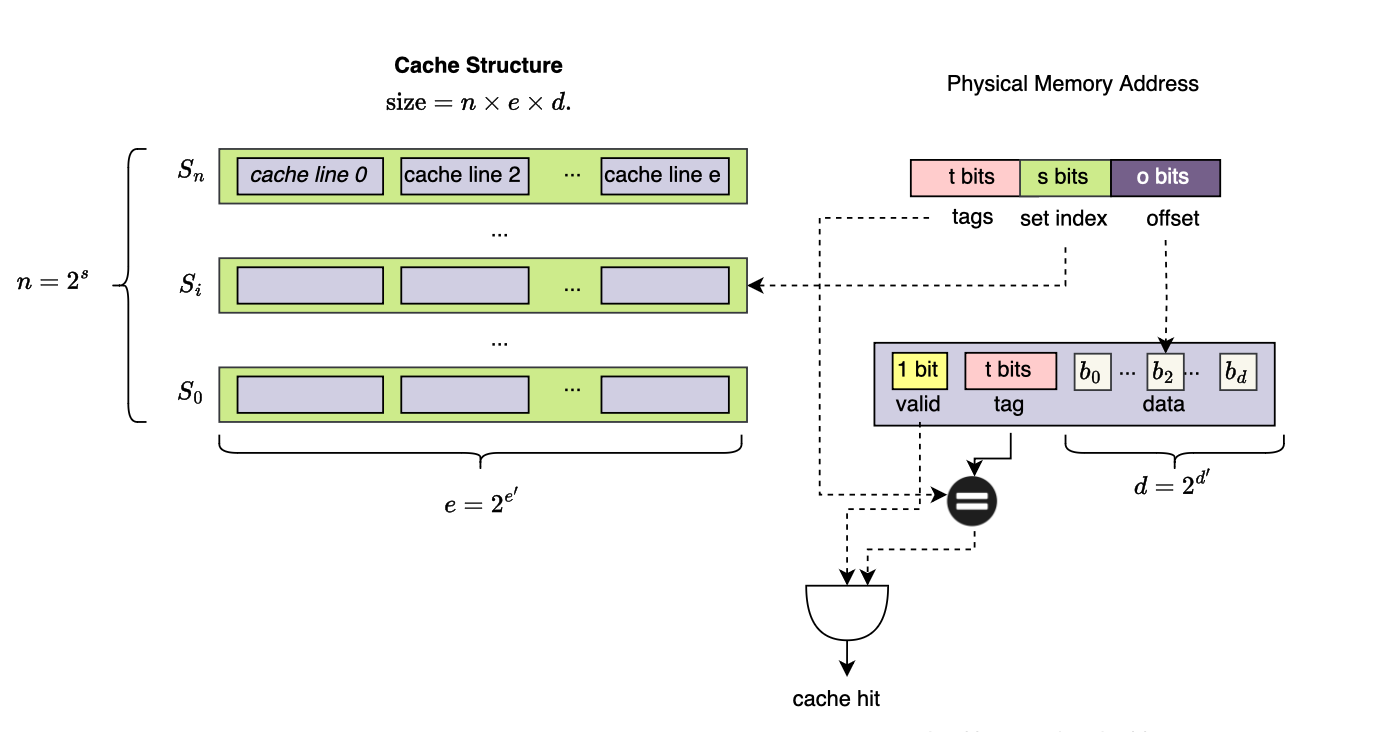
Suppose the hardware is using a direct placement policy i.e one direct mapping between memory block and cache line, main memory is divided into N blocks and when software accesses an address within block j \( \in \(0,N\]\), the CPU computes j mod E = k and checks whether block k is already loaded in the cache. Since N >> E, conflicts may arise. This is where group tags come into play, they provide an additional check to prevent collisions. And the cache line is selected only if the high bits of the memory address match. Specifically, the highest x bits of the address are used to resolve conflicts ,the lowest x bits (determined by cache line size, e.g., for a 64-byte cache line, the lowest 6 bits since 2⁶ = 64) specify the byte offset within the cache line. The middle bits serve as the index within the set structure. This structure allows the cache to be designed as multiple sets, with each set containing multiple cache lines, all mapped and retrieved based on the memory address.
When accessing data, the virtual address must first be translated into a physical address. This translation is performed by MMU/TLB, which maps virtual addresses to physical addresses. Once the physical address is obtained, the cache is searched to determine if the data is available.
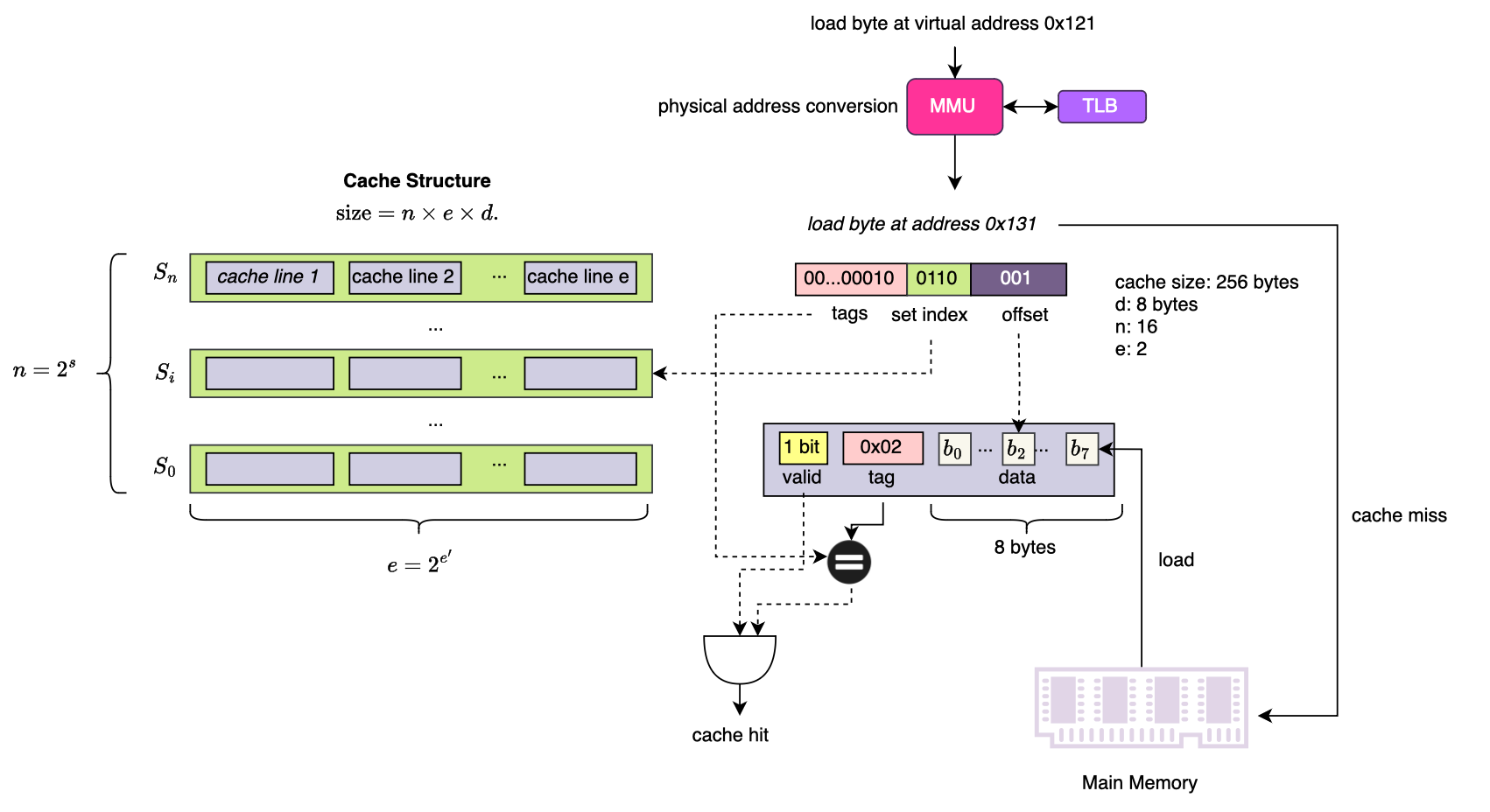
More specifically, to locate a cache line in the L1 cache, the memory address is divided into three components, the tag is used to determine whether the cache line corresponds to the requested physical block, the set index is used to locate the specific set within the cache structure, finally data offset specifies the byte to read within the cache line. If the requested data is found in the cache, this is called a cache hit. Otherwise, it results in a cache miss, requiring data fetching from higher-level caches or main memory. Note that the size of the tag and validity are not considered when computing the size of the cache.
In addition to performing arithmetic operations, the processor modifies the value of data in memory, and this data could be shared (e.g., through mmap). Question: Each processor holds a private copy of a shared variable/cache line, if one processor update the variable, how to prevent the reader from loading stale or incoherent data i.e let the readers know that the variable has changed ? this is known as the cache coherence problem. The cache coherence protocol (e.g MESI) perform the duty of enforcing the write or store atomicity i.e enforcing that stores to a given memory location are visible to everyone in the same order.
Briefly stated, cache coherence ensures coherent view of the same backed physical memory among several cores, it defines what values can be returned by a load operation and enforces the event ordering of stores to a single memory location. Cache coherence is typically achieved through invalidation-based protocols. Censier and Feautrier defined a coherent memory system as follows [14]:
"A memory scheme is coherent if the value returned on a LOAD instruction is always the value given by the latest STORE instruction with the same ad- dress."
Memory consistency, in contrast, governs the ordering and visibility (i.e. to other processors) to a all (single and different) locations issued by several processors with or without caches and thus cache coherence represents a means to implement a memory consistency model.
In uniprocessors, memory consistency is well-defined since only one core executes at a time, and every load issued after a store will see the latest value. Here, latest is precisely determined by program order. In multiprocessors, concurrent readers and writers may access the same memory address simultaneously, for instance, when a load and store occur on two different processors, the underlying semantic is not always intuitive, for instance a load can overtake a pending store in store buffer.
As a programmer, understanding the behavior of loads and stores in such cases is crucial. This is why memory models exist: they define the contract between the programmer and the memory system, specifying the possible executions in shared memory programs.
Different memory models have been proposed, including sequential or strong memory models and weak memory models. Some architectures adopt less intuitive semantics, specifically trading store atomicity for performance. In relaxed architectures, store atomicity is relaxed, a processor is allowed to read the value of its own store buffer or pending writes before they become visible to other cores this is known as store-load forwarding. As discussed later, relaxed memory models provide programmers with explicit fences or barriers to enforce ordering. However, the responsibility is delegated to the programmer.
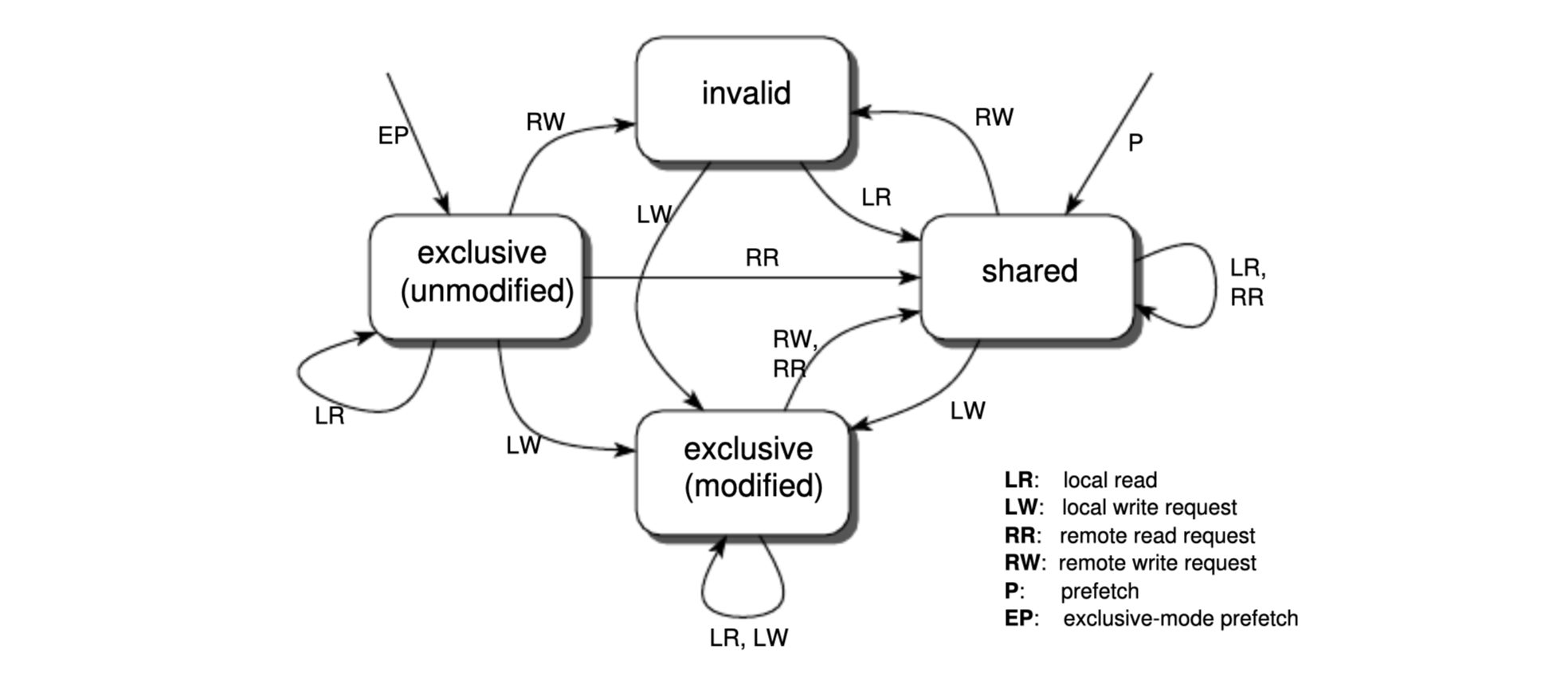
MESI is a four-state coherence protocol where each cache line (which stores data from a physical address) has four states:
When a CPU holds a cache line in the Exclusive state, it means that it has exclusive access to that memory address and is the only one allowed to update it, modifying it will invalidate copies in other CPUs' caches. Once data owner do not need to send the new value to other CPU thereby reducing bus traffic. When read miss is signaled, the memory is written back to the memory and the state transitions to Shared.
More specifically, when a CPU wants to update a variable shared by other processes (e.g., ring_buffer->consumer_position), it must first deliver an invalidation message to other CPUs. The CPU then waits for an acknowledgment or ACKs response from the other CPUs. Only after receiving the Invalid ACK can the CPU proceed with updating the data in the cache (it remains pending in store buffer). If another CPU later needs this updated data, it must retrieve it from the modifying CPU’s cache before the data is eventually written back to memory, transitioning the cache line to the Shared state.
The MESI protocol is essentially defined by a finite-state automaton. Each cache line has a state, and the actions or transitions applied to the cache line by other cores change its state. This is illustrated below.
While MESI solves the problem of cache consistency, transitioning a cache line to the invalid state is time-consuming. Since modern CPUs aim to stay busy, they introduce additional components between the CPU and the cache, namely the store buffer and invalidation queues.
With store buffers, instead of waiting for the invalidate ack response, the CPU writes the new version of the data into the store buffer, it is not yet committed in the cache (pending store). The CPU sends the read invalidate request, next, the CPU continue executing other unrelated instructions. Once the response from the other CPUs arrives, the CPU updates the cache line, marks it as Modified.
To avoid having two copies of the same data in both the store buffer and the cache line, every load has to look at the store buffer for pending stores with the same address (this is referred as store-to-load forwarding) in addition to the the cache lines (unfortunately this is not possible with invalidation queues as it is physically distant).
That being said, direct access to the store buffer is provided, allowing the CPU to use the pending value in the store buffer while waiting for the invalidate ack response. This enables the CPU to continue executing instructions without stalling.
However, if the store buffer is not large enough to hold a significant amount of data, at some point, the CPU will still have to wait. The main bottleneck, as mentioned earlier, is the time it takes to receive the invalid ack. So, why not introduce another storage mechanism to temporarily hold invalidate messages that will be processed by the receiving CPU (not instantly) and instead of invalidating the cache immediately, we defer the invalidation.
To maintain correctness, before sending an invalidate message, a CPU must ensure that its invalidate queue is empty meaning there are no pending invalidate messages that have yet to be processed. This ensures that all previous invalidation requests have been handled before any new ones are issued, preventing potential inconsistencies.
The store buffer and invalidation queue are among the main causes of memory reordering.
Since we tolerate that the CPU does not invalidate cache lines immediately (ack response is still sent though), it may lead to a situation where a CPU uses an invalid or incoherent value. However, this is not a fatality; read barriers smp_rmb() can be used to force processing the invalidation queue.
Furthermore, the store buffer can hold pending writes that are not immediately visible to other cores, creating opportunities for StoreStore reordering. Similarly, a store or write barrier, smp_wmb(), flushes the store buffer, ensuring that all pending writes become visible to other cores to prevent store disordering e.g. when subsequent stores do not require waiting for an acknowledgment as the cache line is already owned.
A program execution is said to have a data race when two threads or processors access the same memory location concurrently, with at least one of them performing a store, without ensuring that the operation is atomic or enforcing a happens-before ordering through synchronization primitives like spinlocks.
Data races can lead to aberrant executions. A typical example is implementing a ring buffer using lock-free programming, where the producer modifies the producer position while the consumer reads it. If the modification of the producer position does not happen before the consumer reads it (i.e., acquire-release semantics are not enforced), a data race occurs and the memory effects of the producer may not become visible to the consumer. Since naively synchronizing all potential racing memory accesses would incur significant performance overheads, we will discuss how lock-free data structures are implemented and how to avoid counterintuitive executions by using happens-before relationships (achieved using acquire and release fences).
As introduced earlier, compilers and microprocessors can reorder memory instructions as long as the execution remains unaffected when run on a single core. However, both the CPU and the compiler may be unable to reorder instructions when there is a data, control, or address dependency between them.
There is a data dependency occurs when a later store depends on the result of a previous load, preventing reordering because doing so would change the program’s behavior when executed in a single-threaded context. For example, consider the following code:
int foo = a;
bar = foo + 1;
x = y;Here, the assignment bar = foo + 1 cannot be reordered before the load of a and store into foo, while x = y could potentially be reordered before foo = a.
Address dependency happens when the memory address on which an instruction operates (load or store) is determined by a previous load. In such cases, the dependent instruction cannot be executed before the first load. For example:
foo = &e;
x =foo->bar;
In this scenario, the store to x cannot be reordered before the first instruction because it relies on the address stored in foo.
Finally control dependency exists when a condition based on a previous load influences a later load or store. For instance:
if (foo) {
bar = 1;
}Even though the control dependency prevents certain reorderings, compiler optimizations introduce surprising reordering. In this case, memory fences or barriers are still necessary to enforce proper ordering.
Lock contention arises as soon as at least one thread is spinning for a lock.
When synchronizing access to a critical section using locks (e.g., spinlocks), having all spinners spinning on a shared lock variable increases bus traffic due to cache-coherency operations and excessive cache misses, which can interfere with lock handover and other unrelated operations that also need the bus. As a result, overall performance can suffer, creating scalability bottlenecks. We will discuss how the Linux kernel handles lock contention and how it has evolved from simple spinlocks to ticket spinlocks, and eventually to modern queue spinlocks.
Locks used improperly can cause deadlocks.
In such scenarios, neither the lock owner nor the threads spinning on the lock can make progress. A common example occurs when a user task owns a lock and is then preempted by the kernel, the other task or interrupt handler (e.g. when using nested spinlocks) may attempt to acquire the same lock, which will never be released because the owner is sleeping, thereby blocking the lock acquisition path.
Another example is holding two locks in opposite order cpu1 holds lock1 while cpu2 holds lock2, then cpu1 tries to acquire lock 2 held by cpu2 at the same time cpu2 tries to acquire lock 1 owned by cpu1 creating a deadlock.
Some designs include deadlock detection mechanisms for cases where the spin or busy-wait loop is stuck, it could be as simple as timeouts.
When a user context holds a lock and is interrupted, if the interrupt handler attempts to access the same critical protected region, it will try to acquire the lock. However, since the user context that originally held the spinlock has been preempted, the handler running in interrupt context will spin indefinitely waiting for the lock to be released, resulting in a deadlock. We will discuss later during spinlock implementation how this can be avoided.
Not every lock implementation is fair.
Without a fairness guarantee, a thread or processor ready to make progress may never get a chance to enter the critical section.
This issue commonly arises in naive spinlock implementations based on read-modify-write or rwm operations. If the lock’s memory location is geographically closer to certain cpus, those cpus can acquire the lock more frequently, causing other cpus to starve. This can become especially problematic if the starved task is critical.
We will discuss later how the kernel ensures fairness in spinlock implementations.
One way to avoid exclusive locking and the necessity to use atomic operations is to avoid sharing memory between cpus, which can be achieved using per-cpu variables i.e one variable per cpu, trading storage for performance.
#define DECLARE_PER_CPU(type, name) \
DECLARE_PER_CPU_SECTION(type, name, "")linux/include/linux/percpu-defs.h
When using per-cpu variables, you eliminate cache bouncing and effectively reduce unnecessary traffic on the memory bus. This is utilized in x86 queue spin locks implementation in linux kernel, as discussed later.
Concurrency can arise from several sources, including preemptive scheduling (where a higher-priority task can preempt a lower-priority task) and symmetric multiprocessing or smp, where multiple CPUs can be active at the same time.
Concurrency can also originate from interrupts, which signal the CPU to request its immediate attention. When an interrupt is triggered, the CPU may suspend the current process and invoke a specific kernel routine (irq handler), the suspended process is then resumed as soon as the interrupt completes.
Broadly speaking, there are two types of interrupts, software and hardware interrupts. Software interrupts (e.g., system calls or traps), are synchronous and triggered by software. Hardware interrupts are asynchronous signals generated by external devices.
The kernel may also issue software interrupts that run in interrupt context, called softirqs. In turn, interrupts triggered by hardware are known as hardirqs. Note that a user context can be interrupted by a softirq, and a softirq can, in turn, be interrupted by a hardirq.
Race conditions can occur in several scenarios:between tasks running in process context (even on a single core), between a task and interrupt handlers, or between different interrupt handlers on different CPUs.
Execution within a critical section can be interrupted, if a higher-priority task accesses the same critical region concurrently, it may cause undefined behavior or deadlocks. Both user and kernel threads can be preempted at any time.
Even if preemption is disabled, hardware interrupts can still interrupt a task in a critical section. In some cases, interrupts must also be disabled (for instance, when using a spinlock).
On multicore systems, disabling preemption on one core does not prevent tasks running on other cores from entering the same critical section; synchronization primitives like spinlocks or mutexes are therefore necessary. However, code in interrupt context can also attempt to acquire a spinlock, again can lead to deadlocks unless hardware interrupts are disabled. The kernel provides dedicated APIs for this (e.g., spin_lock_irqsave(), spin_unlock_irqrestore(), spin_lock_irq(), spin_unlock_irq()).
Data races often arise when a thread performs non-atomic operations (e.g., load - process - store). If a thread is interrupted between the process and store steps, another thread or CPU could modify that same cache line and update the value; when the first thread resumes, it might overwrite that update, causing inconsistent state.
Disabling task switching or preemption and interrupts guarantees uninterrupted execution. However Non-maskable interrupts (NMIs) cannot be disabled and always require immediate handling.
Finally, disabling interrupts is expensive and can degrade overall performance, so it must be used with care. In Linux, the spinlock implementation may disable preemption and interrupts upon entry into the critical section, then re-enables them on exit. Other synchronization mechanisms, such as mutexes, cause tasks to sleep, but interrupt-context code cannot sleep. When a system call is issued, the kernel code runs in user or process context and has an associated task_struct. This allows the task to be put to sleep (by setting its state and invoking the scheduler) if necessary. Interrupt handlers, however, run in interrupt context and do not have an associated task_struct, which means they cannot sleep. Thus, mutexes must never be used in interrupt context.
Briefly stated, a read/write/modify operation is said to be atomic if it completes in a single, indivisible step without interruption from other concurrent threads (i.e no thread can see the operation or modification half-complete). Think of it as one compact, unique machine instruction. A simple use case is updating a shared integer counter, which involves loading the value, incrementing it, and storing the new value.
It would be foolish to assume that operations on shared memory are always atomic. Consider a scenario where two threads are racing to increment a shared value. The operation involves loading the value from memory, incrementing it, and then storing the updated value back. If not handled properly, another thread may interrupt this sequence, leading to unexpected results. For instance, a 64-bit store to memory may be broken into two 32-bit store instructions. If one thread updates only the first half while another thread reads the incomplete result, inconsistency arises. In this case, the individual instructions are atomic, but the entire store operation is not.
Hardware guarantees atomicity only when the variable is naturally aligned (and fits within a cache line). Naturally aligned means the memory address is a multiple of the variable's size. For example, an 8-byte double must be stored at an address that is a multiple of 8 (e.g., 0x1000).
However, atomic operations apply only to single elements of data, meaning that a sequence of atomic operations is not necessarily atomic as a whole. Additional synchronization mechanisms, such as mutexes or spinlocks, are required to protect critical sections.
Finally, atomic operations can be expensive and potentially several times slower than a normal read or write operation. We will explore different strategies to optimize atomicity, but often, using per-CPU context can be a more efficient alternative.
Compilers are allowed to reorder instructions as long as program behavior remains unchanged i.e not violating data and control flow dependencies within a CPU core. A memory load can be reordered before a memory write provided that they access two different memory locations.
But there’s a caveat, compiler reordering assumes a single-threaded execution model and operates under the assumption that memory or variables modified by the program are changed only within its scope. This assumption can introduce subtle issues, as the compiler may optimize away seemingly redundant operations leading to code elimination and unintentionally breaking the intended program logic.
The compiler may choose to store a variable in a register rather than repeatedly loading it from memory. While this is generally good for performance, it can lead to unexpected behaviors in multi-threaded programs such as infinite loops if another thread modifies the variable in memory without the compiler being aware of it.
To mitigate such issues, the volatile keyword can be used to instruct the compiler not to cache the variable in registers but instead fetch it from memory/cache on every access . However, this comes at a cost: operations on volatile variables are slower due to suppressed compiler optimizations. Additionally, volatile does not enforce atomicity, nor does it provide sufficient memory ordering guarantees for multi-threading. Since volatile alone is insufficient for preventing memory reordering in concurrent programs, it must be combined with memory barriers.
The compiler provides compiler barriers to prevent out-of-order execution of stores and loads around it. A compiler barrier is analogous to a read/write fence in an out-of-order CPU (note that the barrier doesn't generate any code). The following directive defines a compilation barrier:
#define barrier() asm volatile("" : : : "memory")
Pure compiler barriers have a side effect, they force the compiler to discard or flush all memory values from registers and reload them from memory, ensuring that stale values are not used. However, this can be expensive. A more efficient approach is using READ_ONCE, which is a weaker alternative that can be combined with hardware barriers (idea is being volatile in this path only and not other uses that do not care ).
#define __READ_ONCE(x) (*(const volatile __unqual_scalar_typeof(x) *)&(x))READ_ONCE is a signal that the referenced variable can be updated by other variables and that the current cpu is not the only one updating that variable, the compiler will then exercise caution when generating assembly code. Consider the following code:
foo[0]=bar; [1]
foo[1]=bar [2]The compiler can reorder loads and store older value in foo[1] i.e reorder [1,2]. In order to provide cache coherence and ensure that the code runs as intended in both single-threaded and concurrent code, READ_ONCE should be used.
foo[0]=READ_ONCE(bar); [1]
foo[1]=READ_ONCE(bar) [2]Similarly, in order to inhibit compiler optimization from breaking a code through fancy optimizations, stores to shared variables should be protected using WRITE_ONCE .
#define __WRITE_ONCE(x, val)
do {
*(volatile typeof(x) *)&(x) = (val);
} while (0)
#define WRITE_ONCE(x, val)
do {
compiletime_assert_rwonce_type(x);
__WRITE_ONCE(x, val);
} while (0)While READ_ONCE() and WRITE_ONCE() ensure that the compiler does not optimize away memory accesses to the indicated locations, the compiler can reorder READ_ONCE() and WRITE_ONCE() operations relative to statements that do not contain READ_ONCE(), WRITE_ONCE(), barrier(), or similar memory-ordering primitives.
Also, note that compiler barriers only apply to the compiler and do not prevent out-of-order execution on weakly-ordered architectures, whereas hardware barriers enforce ordering at both the compiler ( except the address-dependency barriers) and CPU levels. The kernel provide sychnirzation primitives, as we will cover later, that may or may not (depending on architecture and underlying memory consistency model ) use READ_ONCE() and WRITE_ONCE() in addition to memory barriers (below is from x86 arch code).
#define __smp_store_release(p, v) \
do { \
compiletime_assert_atomic_type(*p); \
barrier(); \
WRITE_ONCE(*p, v); \
} while (0)
#define __smp_load_acquire(p) \
({ \
typeof(*p) ___p1 = READ_ONCE(*p); \
compiletime_assert_atomic_type(*p); \
barrier(); \
___p1; \
})linux/arch/x86/include/asm/barrier.h
That said, in C and C++, the volatile keyword only signals to the compiler that a variable can be modified externally; it does not enforce atomicity or memory ordering guarantees. This makes volatile unreliable for multi-threading synchronization on its own. Volatile is almost never needed [https://www.kernel.org/doc/html/v4.13/process/volatile-considered-harmful.html].
Languages like Java and C# provide acquire-release memory ordering semantics for volatile variables, making them inherently safer for concurrent programming.
Now we know that the CPU can use a store buffer before updating a cache line while waiting for invalidate messages. This store buffer allows subsequent instructions to proceed without waiting for the cache update. However, this mechanism introduces the risk of memory reordering.
Stores can be observed out of order. As a consequence, other CPUs may see the new value at the wrong time, violating the expected data flow dependency. To mitigate this issue, CPUs implement write memory barriers (smp_wmb). These barriers ensure that all entries in the store buffer must be completed before further stores are allowed. The CPU can either wait for completion or continue adding new entries to the store buffer while ensuring that dependent variables’ cache lines are not prematurely updated.
Does this completely solve the problem? Not so fast.
To optimize performance and prevent the store buffer from stalling execution, CPUs introduce a per-CPU invalidation queue. This queue temporarily holds invalidation messages, allowing the CPU to quickly acknowledge invalidation requests from other CPUs while deferring actual cache invalidation. However, this introduces another risk of memory reordering.
Imagine the following scenario, CPU1 invalidates a variable a (requesting other CPUs to discard their cached copies), CPU2 immediately acknowledges the invalidation but queues the request for later processing instead of acting on it immediately, CPU2 continues executing instructions, potentially accessing a before processing the queued invalidation, leading to the use of a stale value of a.
This behavior can cause data inconsistency or even data loss. To keep that from happening, CPUs provide read memory fences (smp_rmb), which ensure that the CPU processes the invalidation queue before executing subsequent memory operations. These barriers enforce a consistent memory view by ensuring that previously issued invalidation messages are fully processed before any new loads occur i.e prevent LoadLoad reordering.
Memory barriers, also known as fences, membars, or simply barriers, ensure that concurrent threads observe memory operations in the correct order. They restrict both the hardware and the compiler from reordering memory operations aroud the barrier, allowing explicit enforcement of load and store ordering constraints.
Memory barriers can have different semantics depending on the type of reordering they prevent. Bi-directional barriers are very strict, as they prevent all loads and/or stores from being reordered in both directions before or after the barrier. These are referred to as coarse-grained barriers.
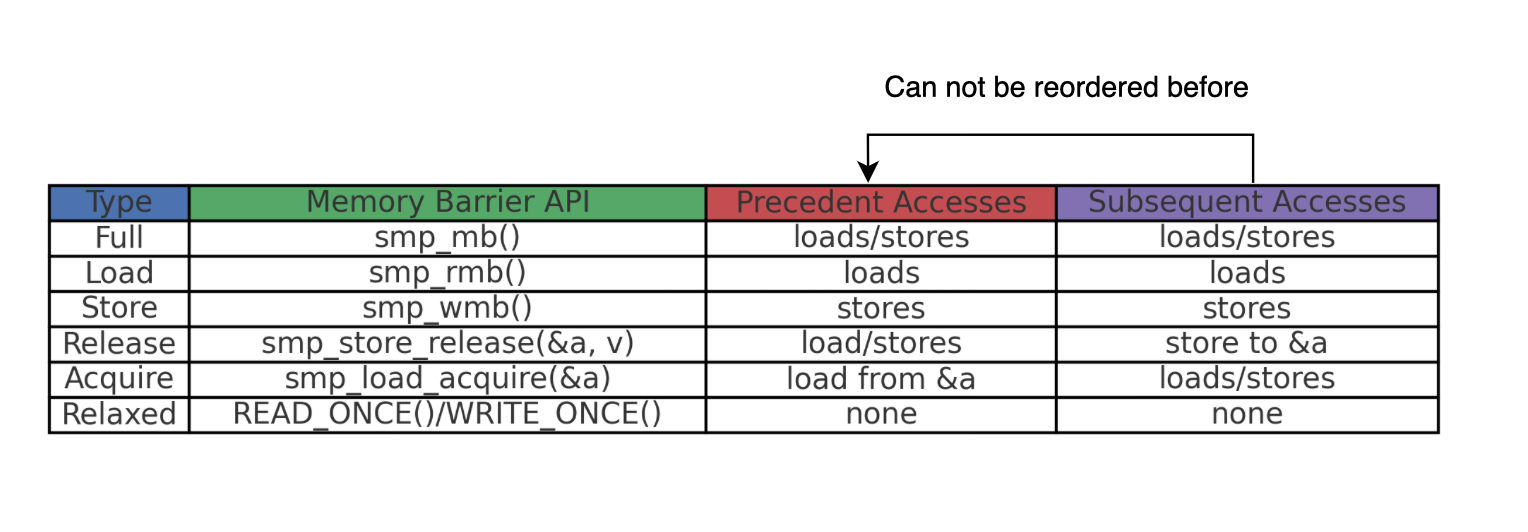
CPUs also provide instructions that impose weaker ordering requirements, such as one-way barriers like acquire barriers, which can be thought of as lightweight or half fences. These fine-grained barriers are named based on the type of memory reordering they aim to prevent. For instance, LoadStore barriers prevent the reordering of a load followed by a store. More generally, fine-grained barriers can be represented as XY, where X, Y \( \in {Load, Store}\), meaning all operations of type X before the barrier must complete before all operations of type Y after it.
That being said, if overused, memory barriers can eliminate performance gains.
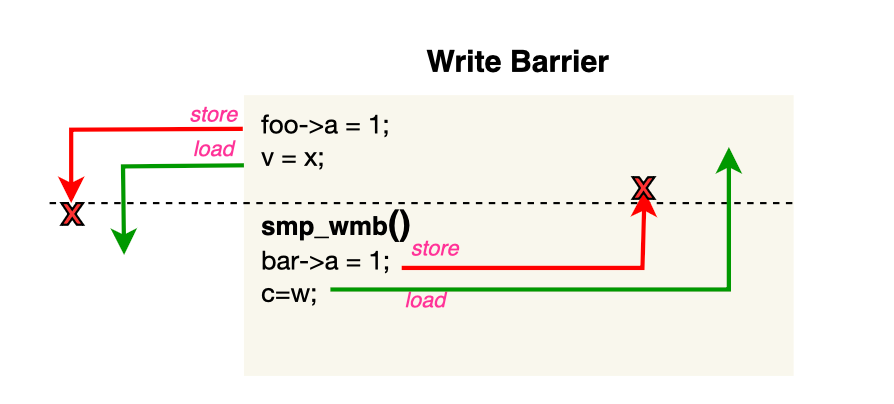
A write barrier (smp_wmb) prevents StoreStore reordering, meaning that stores before or after the barrier cannot be reordered across it. Any loads before or after the barrier can pass through.
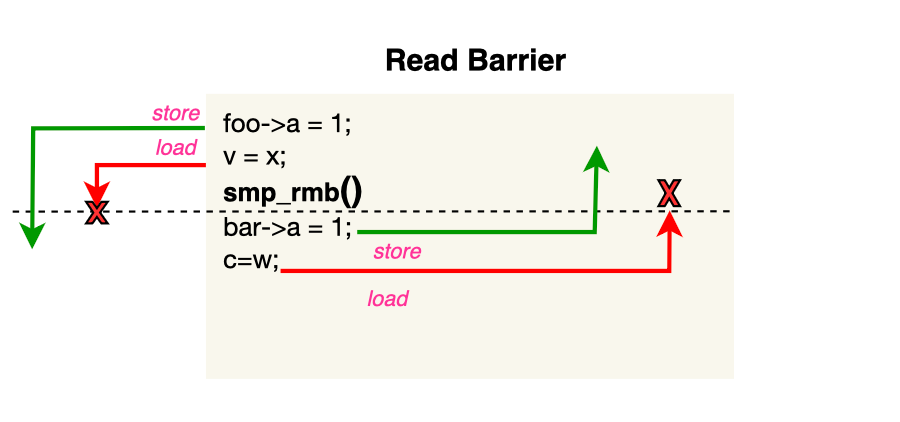
In the same spirit as a write barrier, a read barrier (smp_rmb) is also a two-way fence instruction that prevents LoadLoad reordering. In other words, it ensures that loads before the barrier cannot be reordered after it, and loads after the barrier cannot be reordered before it. However, stores before or after the barrier can still be reordered across it.
A release barrier instructs the CPU not to reorder loads and stores before the barrier after it. Compared to a full memory fence, StoreLoad and LoadLoad ordering are not enforced, meaning loads and stores after the barrier can still be moved before it, making it less expensive.

An acquire barrier is a one-way barrier that prevents stores and loads after the barrier from being reordered before it. However, stores and loads before the barrier can still be reordered after it.

An acquire fence should always be paired with a release barrier to protect critical or sensitive code blocks. This ensures that accesses made within the critical section are not reordered outside of it. Specifically, all stores before the release barrier on CPU1 become visible after the acquire barrier on CPU0. This is referred to as acquire-release semantics and is typically used in lock-free producer-consumer models (such as ring buffers).
Both release and acquire fences help mitigate performance impacts imposed by bidirectional barriers like read or write barriers.
This is the strictest fence. The smp_mb barrier is bi-directional, preventing loads and stores before or after the barrier from being reordered after or before it, respectively. It enforces both read and write barriers, ensuring that both the store buffer and the invalidation queue are properly handled, completely preventing any reordering across the barrier.

Full memory barriers are expensive and impose significant overhead, especially in fast paths, potentially degrading program performance. Weaker barriers are often cheaper and sufficient.
In the past, Linux used a ring buffer with full barriers but later optimized it by switching to cheaper acquire-release primitives.
Additionally, depending on the underlying protocol of the program, in strongly ordered architectures (e.g., x86), memory ordering can sometimes be guaranteed without explicit barriers [https://lwn.net/Articles/576486/]. This is why redundant barriers should be avoided whenever possible. In certain cases, such as per-CPU data structures, barriers may not be necessary even on weaker memory-ordering architectures [https://lwn.net/Articles/576492/].
When implementing ring buffers, it is extremely important to add synchronization primitives to avoid memory reordering and speculative loads. For instance, an earlier version of the Linux kernel [https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=2ed147f015af2b48f41c6f0b6746aa9ea85c19f3, https://dl.acm.org/doi/pdf/10.1145/3694715.3695944] contained a bug due to the absence of memory barriers. Specifically, a write barrier was not used to ensure that data was written before committing the head of the queue.
Another issue was related to speculative loads, where an uninitialized function pointer could be accessed speculatively. Since the CPU does not inherently recognize the implicit data dependency between the consumer and producer, the code lacked a fence or barrier to prevent speculation. The fix, shown below, includes load-acquire semantics.
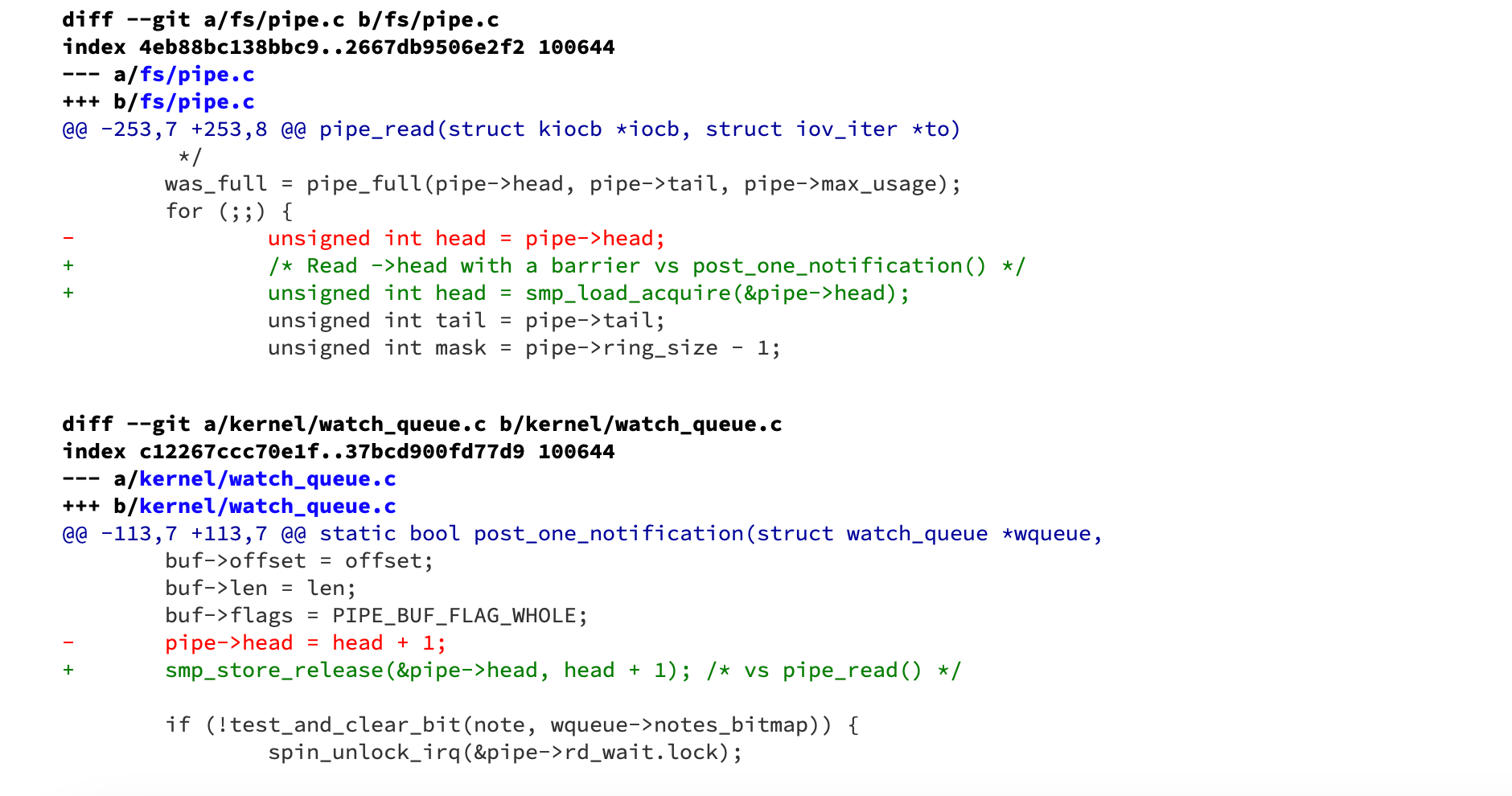
Finally, note that hardware memory barriers introduce overhead, and they are not always necessary if the data being modified does not have other CPUs as data consumers or subscribers. Consider the kernel code below (to be discussed later): it enters an MCS spin lock slow path and operates on a per-CPU variable. In this case, the kernel programmers only needed to ensure that a specific count (to be explained later) is executed first before updating other CPU-related data. Here, a barrier() or a compiler barrier is significantly cheaper and sufficient.
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
node = this_cpu_ptr(&qnodes[0].mcs);
idx = node->count++;
/*
* Ensure that we increment the head node->count before initialising
* the actual node. If the compiler is kind enough to reorder these
* stores, then an IRQ could overwrite our assignments.
*/
barrier();
node->locked = 0;
node->next = NULL;
}The memory consistency model or simply memory model defines the possible executions or behaviors a programmer should expect from the system when performing memory operations i.e loads and stores in a shared-memory program execution. Essentially, it serves as a contract that can be expressed as follows:
Memory Model = Instruction Reordering + Store Atomicity
Different processor architectures (e.g., x86, SPARC) implement distinct memory models, each with varying levels of strictness, relaxation, or counterintuitive semantics. For example, not every memory model enforces store atomicity. For example, in Sequential Consistency (SC), all forms of memory reordering involving loads and stores i.e., Load|Store-Store|Load are strictly prohibited. In contrast, the Total Store Order (TSO) memory model introduces a store buffer, which relaxes StoreLoad reordering. This relaxation allows a core to observe a pending store (via store-to-load forwarding) that has not yet been committed to the cache system. As a result, TSO is a non-atomic memory model.
In sequential or strong consistency model, the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program [Lamport].
While sequential consistency or SC corresponds to most programmers' intuition, enforcing it is computationally expensive. It imposes strict constraints that limit many performance optimizations. At both the hardware level (e.g., store buffers, invalidation queues) and the compiler level (e.g., code motion, register allocation for efficiency), numerous optimization techniques cannot be fully leveraged within this memory consistency model. The strict ordering requirements of SC prevent these systems from applying their optimizations effectively, thereby impacting performance.
With sequential consistency, the hardware and compiler cannot reorder operations, even for different memory locations. All memory accesses by a core must be issued and completed in strict program order. One technique used to enhance performance in this constrained regime is prefetching, which helps loads and stores complete faster by reducing cache misses. Prefetching converts potential cache misses into cache hits by proactively fetching data into the cache. When the address is known, a prefetch request can be issued, specifically a prefetch for ownership is useful when a later store is delayed due to pending writes in the store buffer. A prefetch for read-only helps when read access is expected. In all cases, the goal is to have the cache block or cache line in the Modified, Exclusive, or Shared state before the actual memory access occurs, thereby improving cache hits/performance.
Relaxed Consistency Models trade strict memory ordering for performance, allowing near-unrestricted reordering. This relaxation can partially or completely violate sequential consistency, requiring programmers to carefully manage memory synchronization. Several relaxed consistency models exist, including Total Store Order (TSO) and Weak Ordering (WO). TSO relaxes the StoreLoad ordering constraint, allowing loads to be reordered after stores. It violates write atomicity because a core can load the value of its own write early from the store buffer (store-to-load forwarding). WO further relaxes program order for all memory operations to different addresses, allowing multiple types of memory reordering violations, including LoadStore, LoadLoad, StoreLoad, and StoreStore. To prevent memory reordering, explicit memory barriers or fences must be inserted. Some hardware barriers, as examined later, can be either memory instructions (e.g xchg) or non-memory instructions (e.g WMB) .
Memory consistency models and memory reordering behavior vary across different CPU architectures, each implementing its own consistency guarantees. For instance, AMD64 and SPARC TSO relax StoreLoad reordering i.e loads can be reordered with respect to previous stores. By contrast, Alpha permits all types of reordering.
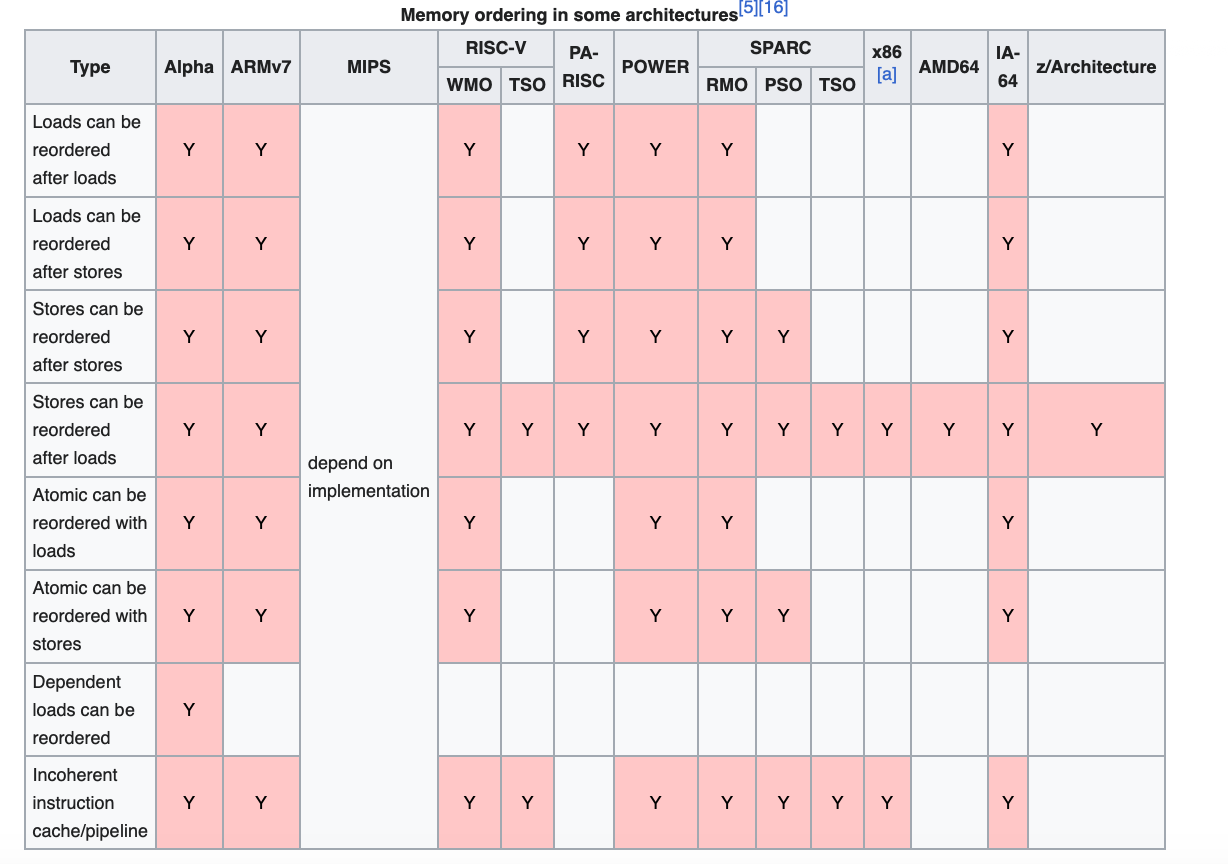
As briefly discussed in a previous section, relaxed memory models do not guarantee memory ordering, in contrast to strong sequential consistency. This presents a challenge for lock-free programmers writing code that shares data between threads.
When data flows from one thread or process to another without using any locks, we call it a lock-free pattern or lock-free programming. This is typically accomplished by enforcing a happens-before relationship between the two memory accesses on different processors, often achieved using acquire and release semantics. We also say that one thread or processor synchronizes with the other.
Consider the following example, where buf and data_ready are shared variables:
CPU 1 CPU 2
-------------------------------- --------------------------------
buf->data = 1; ready = data_ready;
data_ready = 1; if (ready)
printk("%d\n", buf->data);
Here, cpu1 and cpu2 clearly experience a data race because both operate on data_ready (one does a store, and the other does a read), and neither happens before the other and the operation is not atomic. A counterintuitive result can occur if cpu2 reads data_ready as true (1) but still sees an old value in buf->data (e.g., 0), due to possible reordering on cpu1. This can be fixed by enforcing that the store is given release semantics (i.e., it cannot be reordered across the barrier) and that the corresponding load is given acquire semantics (ensuring it sees the latest update):
CPU 1 CPU 2
-------------------------------- --------------------------------
buf->data = 1; ready = smp_load_acquire(data_ready);
smp_store_release(data_ready, 1); if (ready)
printk("%d\n", buf->data);The smp_store_release(data_ready, 1); call ensures that anything that happened before it (such as setting buf->data = 1;) is also visible to any CPU that performs an smp_load_acquire() on data_ready. In other words, data_readycannot be reordered before buf->data on CPU 1, and CPU 2 will see the correct buf->data value if it sees the updated data_ready.
In eBPF ring buffers, there are two positions, one for the consumer and one for the producer, often referred to as head/tail pointers. To enforce the happens-before relationship, the producer uses a store-release primitive, which synchronizes with a load-acquire operation on the consumer side. However, within the kernel, different BPF programs may race to write data into the buffer. In that case, pure lock-free programming can only handle a single producer, and so critical code (reservation code) must be protected using lock primitives (such as spinlocks) in the kernel. This illustrates that lockless techniques do not replace traditional synchronization primitives.
Another way to ensure accesses are ordered by the happens-before relationship is to use atomic operations, a successful compare-and-swap behaves as if the programmer had placed a memory barrier on each side of the operation. We will discuss atomic read-modify-write or rmw later.
Finally, remember that lock-free algorithms trade off simplicity for scalability. They often require complex and non-trivial designs to get right.
As discussed so far, aggressive synchronization primitives can be used to protect critical section code. Hardware support includes low-level atomic synchronization primitives such as compare and exchange (CMPXCHG) which provides a way to modify a single-word memory location conditionally.
CAS takes the address of a memory location and an expected value, then atomically compares the contents of the given location with a provided new value. If they match, the new value is stored.
The goal of CAS is to update the value only if the location’s value has not changed between the load and the CAS operation. In this case, the operation is completely lock-free since there is no need to lock the critical section that loads and modifies the value, thanks to hardware support. Any block protecting a 64-bit variable using a mutex can be converted into a CAS loop.

CAS is selective when multiple producers attempt to write to a shared variable. The typical CAS scenario follows these steps: first, load the value from the memory location; second, map it to a new value; and finally, set the value only if the memory location has not changed in the meantime; otherwise, retry (CAS loop).
However, while CAS avoids using traditional high-level locks, it is vulnerable to the ABA problem (typically occurs with CAS on pointers). This occurs when a shared memory location is read twice by two threads, A and B. If thread A is suspended after reading the value, and in the meantime, thread B performs two CAS operations that modify the value and then revert it to its original state (e.g., \(x -> y -> x\)), thread A resumes execution and successfully completes its cas operation. However, it has been tricked into believing that the value never changed when, in fact, it did leading to unexpected behavior. This kind of inconsistency is exactly what we intended to avoid in the first place.
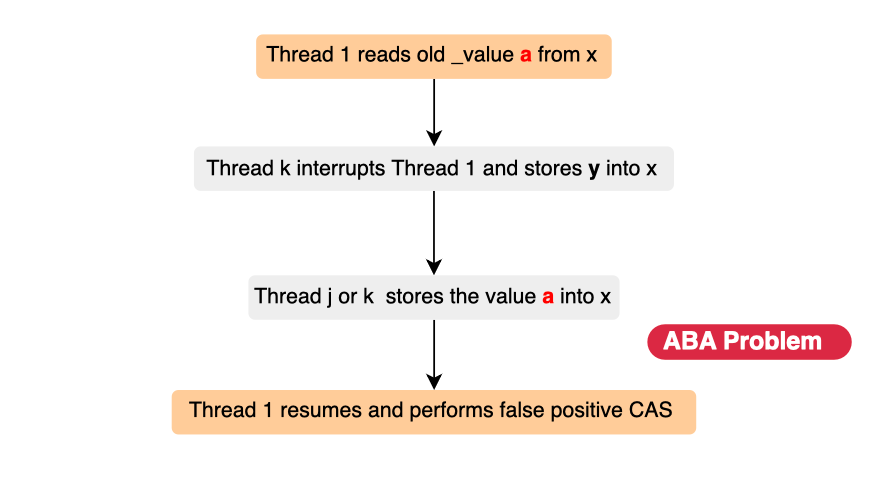
To prevent this issue, various techniques have been introduced, including Tagging, Double Compare-and-Swap (DCAS), and Mutexes (though using a mutex means the operation is no longer lock-free).
In the next subsections, we will look at some hardware primitives commonly used in kernel code to achieve synchronization (spinlocks, mutexes etc.), as understanding them is crucial for deriving proofs of correctness in multi-core systems (how to guarantee uninterruptible operations).
The LOCK prefix in x86 is used to lock a cache line for the duration of a read-modify-write operation. It also acts as a write barrier, flushing the store buffer and thereby preventing StoreLoad reordering. However, how the LOCK is actually implemented in hardware is architecture-specific, and we generally don't need to concern ourselves with it, just that it ensures atomicity. Earlier versions of x86 achieved this by locking the entire bus, whereas modern architectures typically lock only the cache line using the cache coherence protocol.
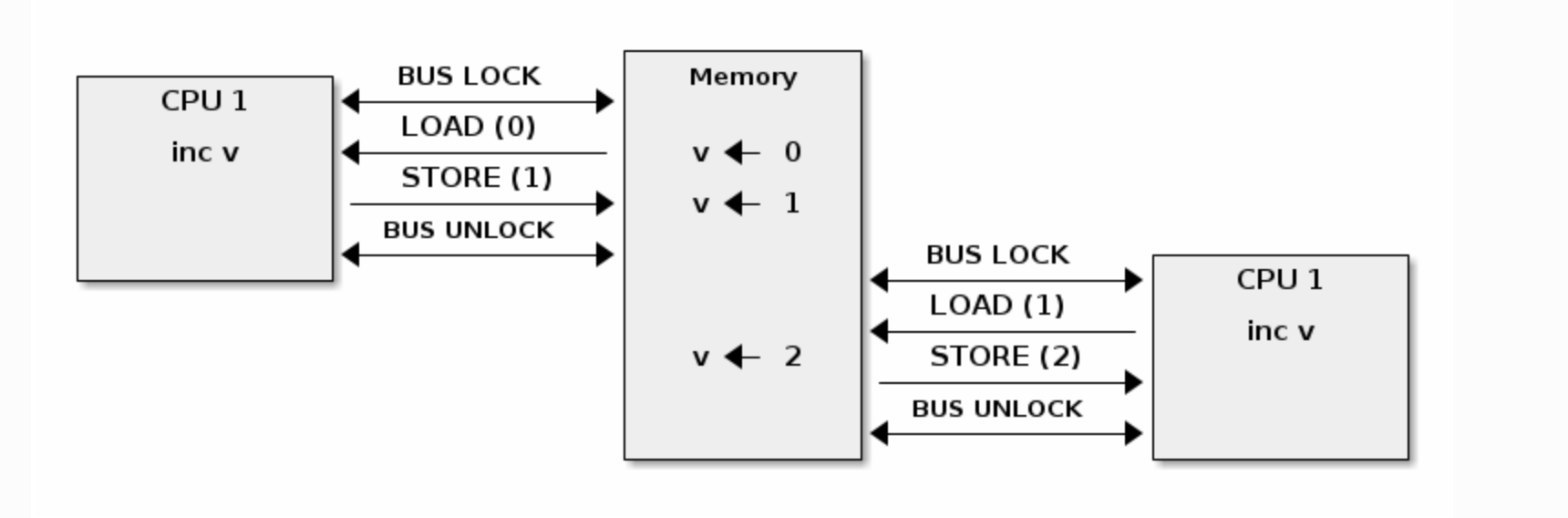
The XCHG destination, source instruction is an x86 exchange instruction that atomically swaps the value stored in a register with the value in a destination memory operand. Behind the scenes, the instruction consists of atomic moves using bus or cache locking (when a memory operand is involved; ask for exclusive access, read invalidate followed by denying all coherence request from other processors until the modify completes), preventing any other core from interrupting the instruction execution. For instance, the Linux kernel uses the xchg primitive in the qspinlock implementation to ensure that the pointer in tailis swapped atomically.
The CMPXCHG destination, source (compare and exchange) instruction in x86 reads the destination memory address and compares it with the value in the register (eax). If the value matches the expected value, the source operand is written to the destination. Otherwise, the register is updated with the current value of the destination memory .
mov rax, 0
mov rcx, 1
cmpxchg [locked], rcx // compare [locked] with rax and if equal, store rcx in [locked] (lock aquired)
The CMPXCHG instruction consists of three micro-operations that are not inherently atomic (unlike XCHG), so it requires the LOCK prefix (LOCK CMPXCHG) when used in a multi-core environment to ensure atomicity. In single-core CPUs, CMPXCHG is already atomic and does not require the LOCK prefix, as interrupts occur at instruction boundaries.
mov eax, 0
lock cmpxchg [locked], 1 // will exchange only if [locked] is 0, otherwise eax is set to original value e.g 1 indicating lock is already held.
Since CMPXCHG can fail, a busy loop is usually introduced to spin the variable .As we will discuss later, qspinlock in the Linux kernel is implemented using CMPXCHG.
In x86, there is no invalidation queue or said differently you don't to add a read memory barrier to prevent LoadLoad reordering , the only possible type of memory reordering is StoreLoad , meaning a load can be performed while the store buffer is still waiting for invalidation messages. To handle StoreLoad reordering, a memory barrier can be added to flush the store buffer to L1 cache if necessary. x86 guarantees acquire-release semantics, meaning reading a shared variable does not require a read memory barrier (though you still need to add barriers for the compiler https://lwn.net/Articles/847481/). We can confirm it by looking at the source code.
#define __smp_store_release(p, v) \
do { \
compiletime_assert_atomic_type(*p); \
barrier(); \
WRITE_ONCE(*p, v); \
} while (0)
#define __smp_load_acquire(p) \
({ \
typeof(*p) ___p1 = READ_ONCE(*p); \
compiletime_assert_atomic_type(*p); \
barrier(); \
___p1; \
})linux/arch/x86/include/asm/barrier.h
In architecture versions prior to LSE (Large System Extensions), LOCK CMPXCHG in x86 translates to the LDAXR (Load-Acquire Exclusive) and STLXR (Store-Release Exclusive) access pair in ARMv8. In fact, before ARMv8.1, there was no direct equivalent for implementing an atomic compare-and-exchange operation. Atomicity was achieved by loading the memory location, invalidating the cache and using a conditional store (STLXR).
ARM contrasts with x86 which provides stronger memory ordering guarantees. Instead, ARM implements a weakly ordered memory model. Load-Acquire, Store-Release semantics can be achieved using LDAXR (Load-Acquire Exclusive) and STLXR (Store-Release Exclusive). LDAXR and STLXR ensure that invalidations are processed before executing subsequent loads (preventing LoadLoad reordering) and the store buffer is drained before issuing further stores (preventing StoreStore reordering).
In newer ARM versions, LSE introduced new atomic instructions, allowing read-modify-write operations in a single step. Instead of using LDAXR/STLXR, we can now replace them with a single RMW operation.
Spinlocks are used to achieve mutual exclusion, synchronizing access to small critical sections, typically in the kernel, where locks are expected to be held for a very short time i.e lock is expected to be released soon. A spinlock is typically achieved using a busy-waiting mechanism, where a processor continuously attempts to acquire the lock to enter the critical section and thus is used in scenarios where sleeping is not an option. This also means that critical sections should remain short.
A common example is the eBPF ring buffer implementation, where spinlocks are used to reserve data space during allocation. However, spinlocks are not recommended for user-space applications, as user-space tasks can be scheduled off the CPU, making spinlocks inefficient.
Spinlocks comes with memory barriers or more specifically, acquire and release semantics, so there is no need to explicitly place them to prevent memory reordering.
When multiple CPU cores compete for the same lock to access a shared memory region, fairness determines whether the lock is granted in order of arrival. Fair access ensures that cores acquire the lock in FIFO order. However, fairness is not always guaranteed. For example, in a NUMA system, cores closer to the lock (on the same NUMA node) may have a significant advantage. Early versions of the Linux kernel used unfair spinlock implementations, leading to starvation [https://lwn.net/Articles/267968/]. A well-designed spinlock should consider fairness, starvation prevention, and overall performance.
In the next two subsections, we discuss three spinlock implementations including Ticket spinlocks, which suffer from performance bottlenecks but work well in low-contention cases and MCS locks, which offer better scalability under contention.
Compare and swap, cas, or compare-and-exchange can be used to implement straightforward spin locks. The lock data structure corresponds to a single variable, an integer, indicating whether the lock is acquired or free (0 or 1). The variable is spun on by all cores wishing to enter the race. Once the lock is acquired, the winner sets the bit to busy and enters the critical section. Finally, it atomically releases the lock afterward by setting the variable to 0.
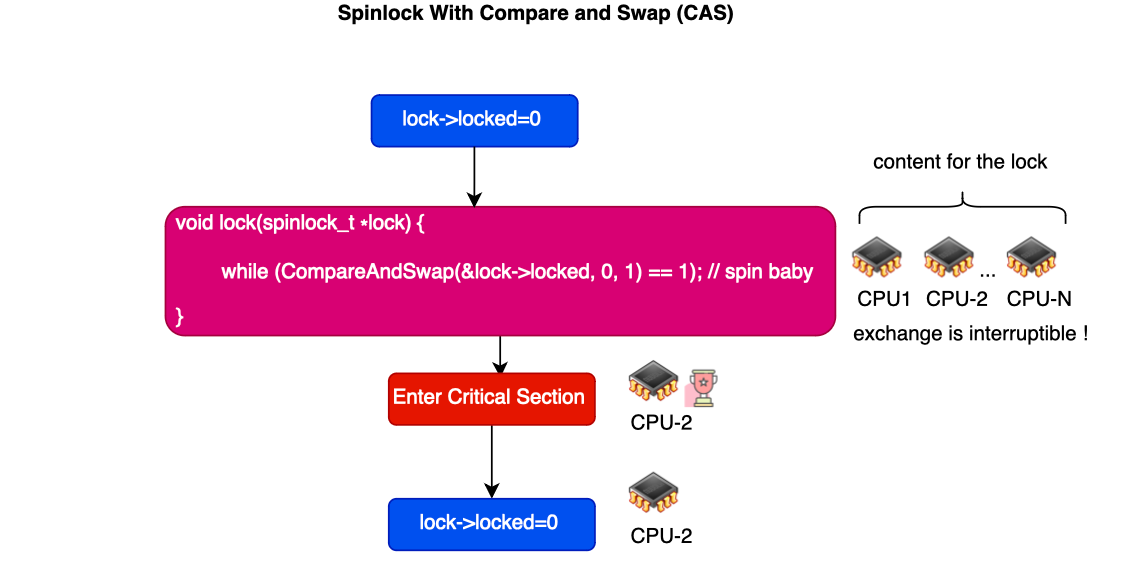
The acquisition and release of the lock are demonstrated below.
static inline unsigned __sl_cas(volatile unsigned *p, unsigned old, unsigned new)
{
__asm__ __volatile__("cas.l %1,%0,@r0"
: "+r"(new)
: "r"(old), "z"(p)
: "t", "memory" );
return new;
}
/*
* Your basic SMP spinlocks, allowing only a single CPU anywhere
*/
#define arch_spin_is_locked(x) ((x)->lock <= 0)
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
while (!__sl_cas(&lock->lock, 1, 0));
}
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
__sl_cas(&lock->lock, 0, 1);
}There are several problems with the above lock. The first issue is lock handover. When the owner releases the lock, it must compete with all waiting threads spinning on the lock, each executing atomic instructions thus generating O(n) traffic. This creates a delay in actually gaining exclusive access to the memory location. Additionally, the bus is utilized for operations that are almost guaranteed to fail, which not only consumes cycles but also delays the processing of other requests. Furthermore, the algorithm is not fair (instead of handling it properly, we delegate it to the CPU’s memory subsystem); during contention, some cores may end up spinning and waiting while others receive an unfair advantage in acquiring the lock. For example, in a NUMA architecture, where multiple nodes or sockets exist, access to local memory is significantly faster than access to a remote memory line on another socket or node. This can lead to core starvation. Additionally,while CAS utilizes a single bus transaction, during contention, the bus can become saturated, affecting other unrelated memory accesses.
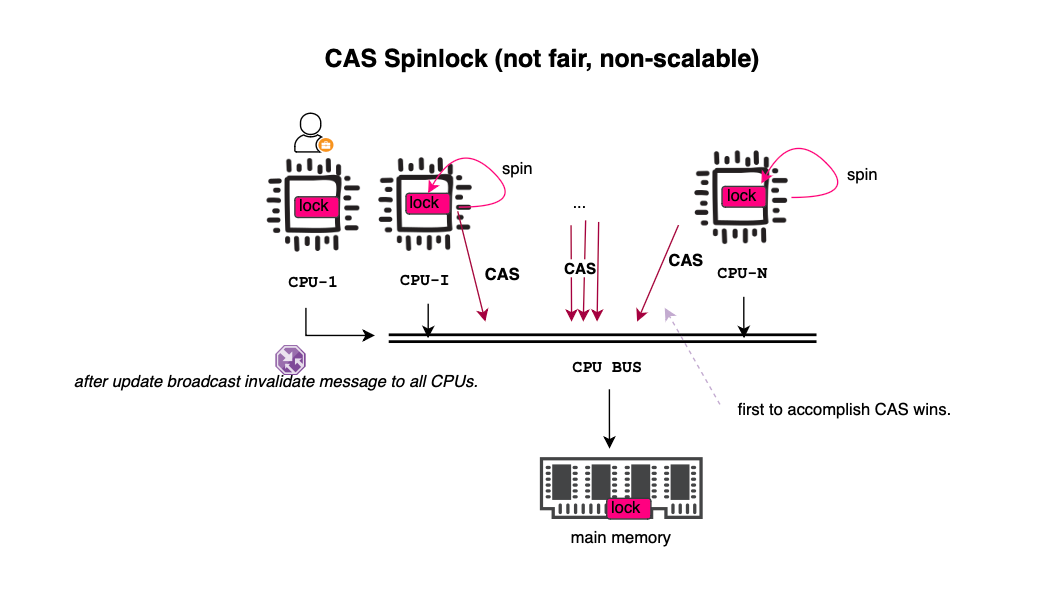
A straightforward way to reduce contention and bus traffic overhead is to introduce exponential backoff. Another way is to spin on the cache i.e busy-wait on load and avoid generating bus transactions when the lock is owned ( cf Test-and-Test-and-Set). Each CPU core spins on its own cached copy of the lock data, reducing bus usage. However, this method has two key problems. First, when the lock is released, an invalidation message is broadcasted, forcing all cores to reread the memory variable into their cache. The waiters or cores then detect that the lock is free and race to acquire it again. Despite traffic or more specifically wait traffic is reduced, excessive coherence traffic is generated during lock release (O(n) cache misses for each core -> O(n^2) global cost); because each atomic operation results in a cache miss, impacting all cores that had started spinning again. In fact, hardware atomics issue a read-for-ownership cache line operation, triggering a broadcast invalidation that invalidates other copies in different caches. As a result, it becomes evident that the Test-and-Test-and-Set mechanism does not scale well for short critical sections with larger numbers of fast cores. Additionally there is no fairness guarantee.
We discus alter two implementations that guarantee fairness one trading storage for bus traffic generation during release while the other has constant storage while experiencing high traffic during lock release or handover. In fact, several solutions have been proposed to ensure fairness and avoid starvation. The MCS lock employs a multipath approach. The fast path is implemented as a read-modify-write atomic lock. The slow path (where contention occurs) uses a more scalable, queue-based locking mechanism. The queue-based mechanism ensures that each core spins on a separate local flag, requiring only a single cache miss (since the owner explicitly wakes up the next core in the queue). This significantly reduces cache invalidations and bus traffic.
To sum up, the performance of straightforward non-scalable locks degrades as the number of processors increases and is only effective in low-contention workloads.
In a ticket spinlock (second version that was implemented in the kernel), the spinlock is implemented using a ticketing system. Specifically, the lock data structure consists of two fields, owner , the ticket of cpu core currently holding the lock, next representing the next available ticket number (indicating the next core in line, enforcing FIFO order).
struct spinlock_t {
int owner; // current ticket number
int next; // next ticket number
}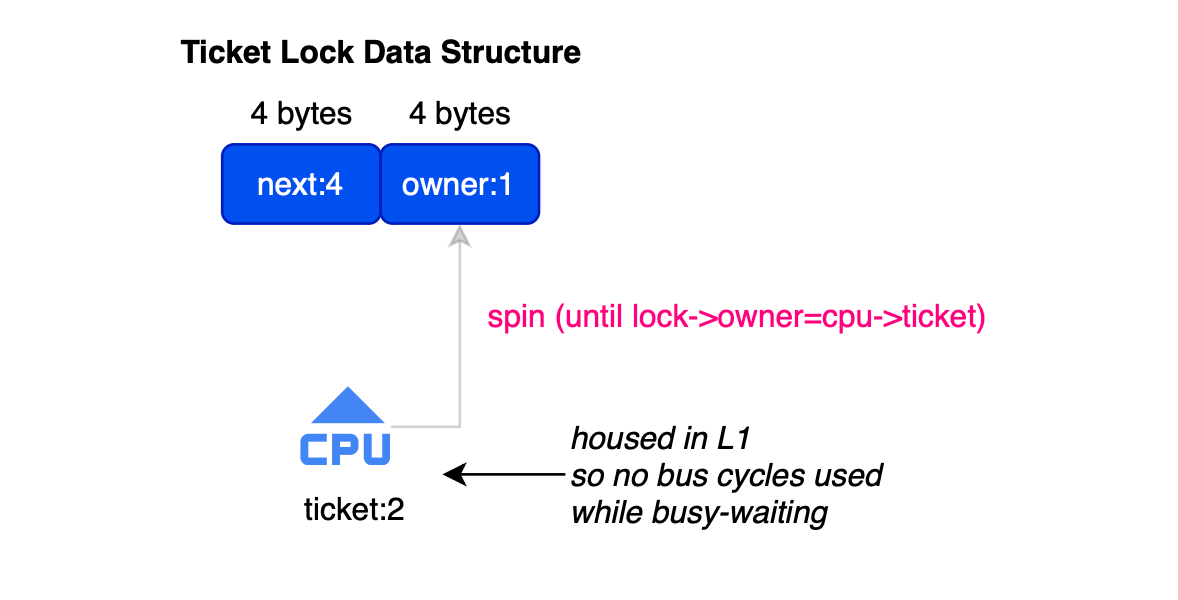
When a core or process acquires the lock, it requests a ticket (a number). It then spins (polls the lock) until its ticket matches the owner value. Specifically, to get a ticket, a core must issue an atomic increment on next and then loop or spin until owner == ticket. Once the condition holds (owner == ticket), the core enters the critical section.
void spin_lock(spinlock_t *lock) {
int temp = atomic_fetch_and_increment(&lock->next);
while (temp != lock->owner) ; // spin
}After executing the critical section, the core must release the lock. Releasing the lock involves incrementing owner, which grants the lock to the next core in line. The waiting cores wakes up and check again, the one whose ticket matches the updated owner enters the critical section.
void spin_unlock(spinlock_t *lock) {
lock->owner++; // lock handover
}As discussed in the CPU cache structure section, each CPU core has its own private cache. When a core releases the lock, it updates owner, which triggers cache invalidation messages to all waiting cores. All waiting cores then reload the owner field, leading to a surge of cache coherence traffic (the cache line here, of course, holds spinlock data along with surrounding and related data structures, the spinlock is usually only few bytes). Thus, lock handoff time scales linearly with the number of waiting cores, if there are n waiting cores, each release causes O(n) cache misses significantly slowing the lock owner (overall traffic for N cores is O(n^2) same as CAS) . In other words, transferring ownership of the spinlock takes linear time in the number of waiting cores. When contention is low, a core can quickly acquire the spinlock. However, as soon as many cores start competing for the lock, the handover time increases drastically, leading to performance collapse. There are different ways to improve the ticketing scheme including backoffs, instead of continuously spinning, a waiting core pauses briefly before retrying to reduce cache contention and bus traffic.
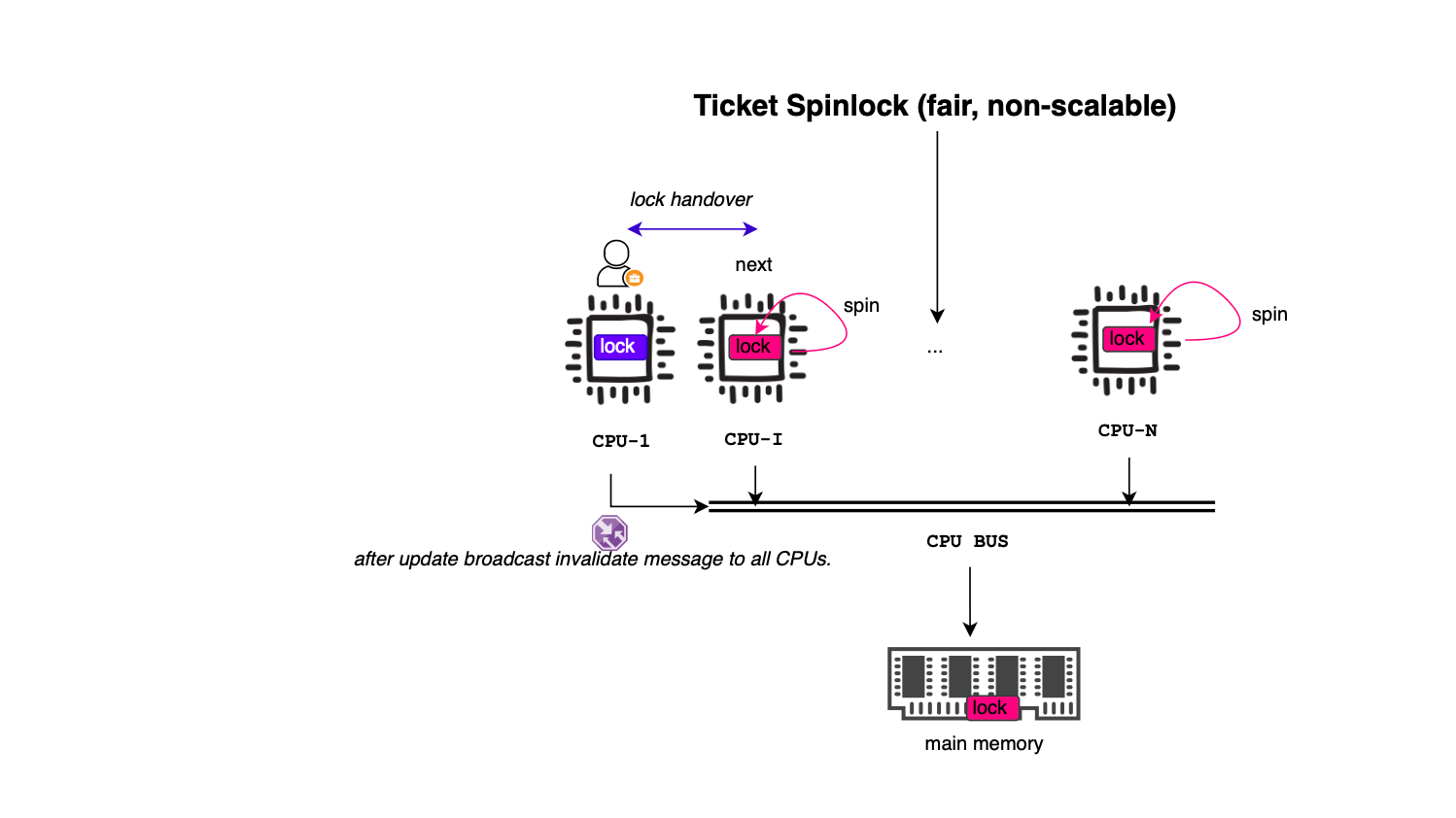
The Linux kernel provides different implementations or APIs to acquire a lock including spin_trylock, spin_lock, spin_lock_irq, and spin_lock_irqsave.
spin_trylock only attempts to acquire the lock once and returns immediately, indicating whether it succeeded or failed. It does not implement a spin loop, making it useful for the fast path or uncontended situations.spin_lock, on the other hand, disables preemption and attempts to acquire the lock using busy-waiting or spinning. However, it can still be interrupted by software or hardware interrupts.Here is what the code looks like in the kernel:
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_); // ignore this just for debugging
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);<---
}It starts by disabling preemption. Next, it attempts to acquire the lock using do_raw_spin_trylock (fast path). If this attempt fails, it falls back to do_raw_spin_lock.
The macro LOCK_CONTENDED is defined as follows. The idea is to first attempt to acquire the lock without spinning:
#define LOCK_CONTENDED(_lock, try, lock) \
do { \
if (!try(_lock)) { \
lock_contended(&(_lock)->dep_map, _RET_IP_); \
lock(_lock); \
} \
lock_acquired(&(_lock)->dep_map, _RET_IP_); \
} while (0)The unlock process is shown below. It invokes do_raw_spin_unlock and finally re-enables preemption.
static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
spin_release(&lock->dep_map, _RET_IP_);
do_raw_spin_unlock(lock);
preempt_enable();
}do_raw_spin_lock delegates to an architecture-specific implementation, arch_spin_lock.
static inline void do_raw_spin_lock(raw_spinlock_t *lock) __acquires(lock)
{
__acquire(lock);
arch_spin_lock(&lock->raw_lock);
mmiowb_spin_lock();
}Without loss of generality, we examine the ARM architecture. Below is the spinlock data structure and its corresponding implementation in the kernel:
#define TICKET_SHIFT 16
typedef struct {
union {
u32 slock;
struct __raw_tickets {
#ifdef __ARMEB__
u16 next;
u16 owner;
#else
u16 owner;
u16 next;
#endif
} tickets;
};
} arch_spinlock_t;Note that arch_spinlock_t is 32-bit, and slock is used for atomic operations, union structure is used to cope with little-endian and big-endian formats otherwise one can mess with portability.
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
prefetchw(&lock->slock);
__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"
" teq %2, #0\n"
" bne 1b"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
while (lockval.tickets.next != lockval.tickets.owner) {
wfe();
lockval.tickets.owner = READ_ONCE(lock->tickets.owner);
}
smp_mb();
}linux/arch/arm/include/asm/spinlock.h
prefetchw is used as an optimization to reduce the latency of the next store operation and has been shown to boost performance. The Load-Exclusive (LDREX) and Store-Exclusive (STREX) instructions discussed earlier perform an atomic read and update, incrementing by 1 << TICKET_SHIFT, as the next ticket occupies the upper 16 bits. If the lock is contended, it enters a while loop, spinning on the owner field (i.e., checking if the current lock owner matches its ticket number). The wfe() (wait for event) instruction is used for power saving while waiting for the lock. The smp_mb() is full memory barrier and ensures that the critical section is properly sandwiched, preventing memory reordering around the barrier.
The unlock code is relatively simple: issue a full memory fence (smp_mb()) to prevent reordering and then handover ownership by incrementing the owner number.
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
smp_mb();
lock->tickets.owner++;
dsb_sev();
}dsb_sev() is used to wake up other waiters (paired with wfe()).
arch_spin_trylock is almost the same with the only difference is no spin loop is used (if lock already acquired it fails immendiatly ). A memory barrier is also needed to prevent memory reordering.
static inline int arch_spin_trylock(arch_spinlock_t *lock)
{
unsigned long contended, res;
u32 slock;
prefetchw(&lock->slock);
do {
__asm__ __volatile__(
" ldrex %0, [%3]\n"
" mov %2, #0\n"
" subs %1, %0, %0, ror #16\n"
" addeq %0, %0, %4\n"
" strexeq %2, %0, [%3]"
: "=&r" (slock), "=&r" (contended), "=&r" (res)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
} while (res);
if (!contended) {
smp_mb();
return 1;
} else {
return 0;
}
}The problem with spin_lock is that disabling preemption is only effective in normal tasks, meaning that interrupts can still occur. If an interrupt handler attempts to acquire the same lock, a deadlock occurs. This is why spin_lock should only be used when there is 100% certainty that no interrupt will attempt to access the same critical section. If the lock can be accessed by interrupt routines, one should use spin_lock_irq which additionally disables local interrupts. The corresponding kernel code is shown below. First it disable interrupts using local_irq_disable(). Next, disable preemption using preempt_disable(). The flow then follows the same pattern discussed earlier.
static inline void __raw_spin_lock_irq(raw_spinlock_t *lock)
{
local_irq_disable();
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}This means that we resolve the previous issue where interrupts could access the same critical section, preventing potential deadlocks. However, spin_lock_irq does not support nested scenarios. The problem arises when an interrupt is disabled, but then re-enabled after entering a critical section. In this case, the parent section (the original critical section) would again be vulnerable to deadlocks between the interrupt handler and the task holding the lock.To address this, spin_lock_irqsave saves the current state of local interrupts, allowing nested spin_lock_irq calls to track and restore their previous interrupt states. This ensures that the original state is correctly restored, preventing deadlocks while still maintaining proper interrupt handling.
static inline unsigned long __raw_spin_lock_irqsave(raw_spinlock_t *lock)
{
unsigned long flags;
local_irq_save(flags);
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
return flags;
}spin_lock is the cheapest locking mechanism (after spin_trylock). spin_lock_irq and spin_lock_irqsave introduce additional overhead, as they disable interrupts, so they should only be used when necessary to avoid unnecessary performance degradation.
Finally, ticket spinlocks can severely degrade performance. If you deploy software on a multi-core system expecting better performance, you may actually experience performance collapse (see the picture below). As an alternative, one can consider lock-free data structures, though they require careful and subtle design to ensure correctness and efficiency.
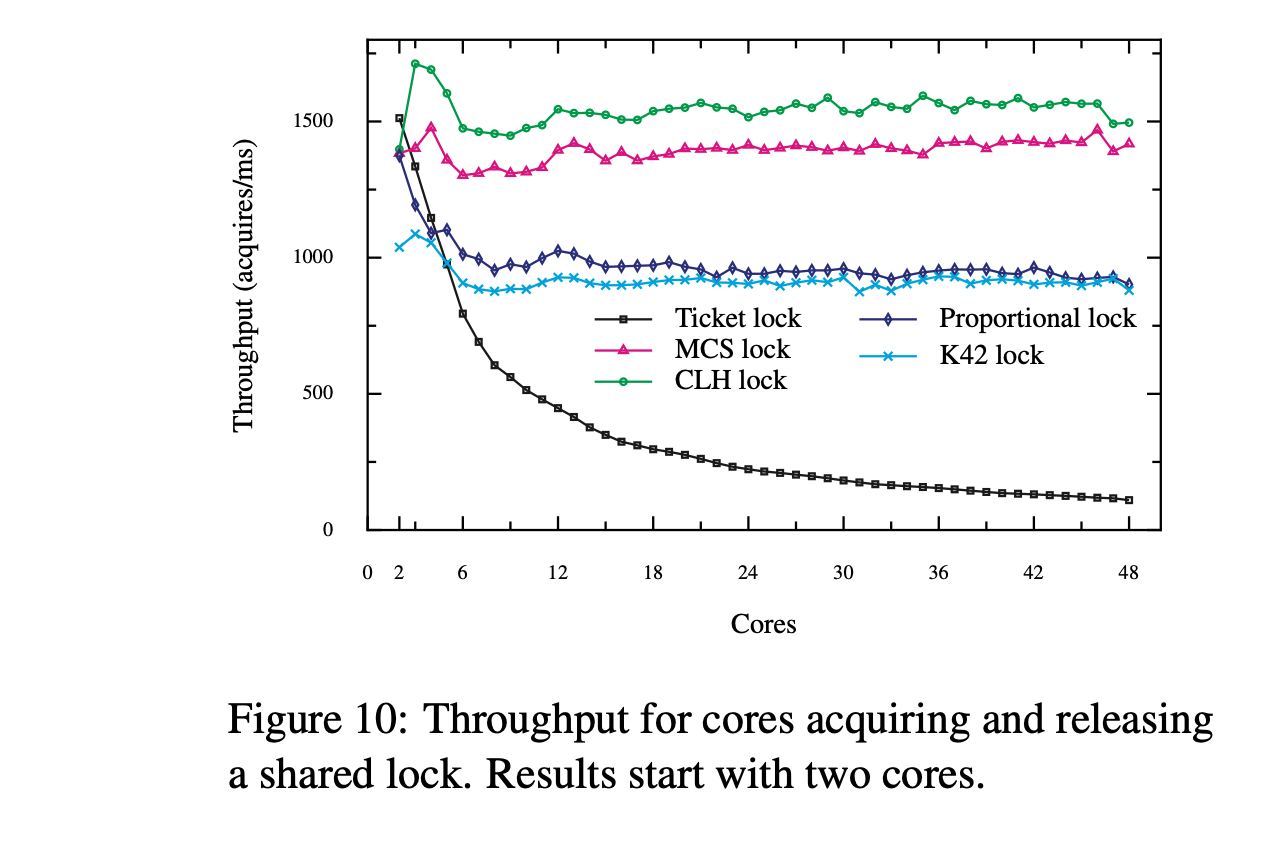
As briefly mentioned in the previous subsection, ticket spinlocks are non-scalable locks that can cause system performance to collapse under high contention. In contrast, MCS locks significantly improve scalability by ensuring that the number of cache misses remains independent of the number of waiting threads.
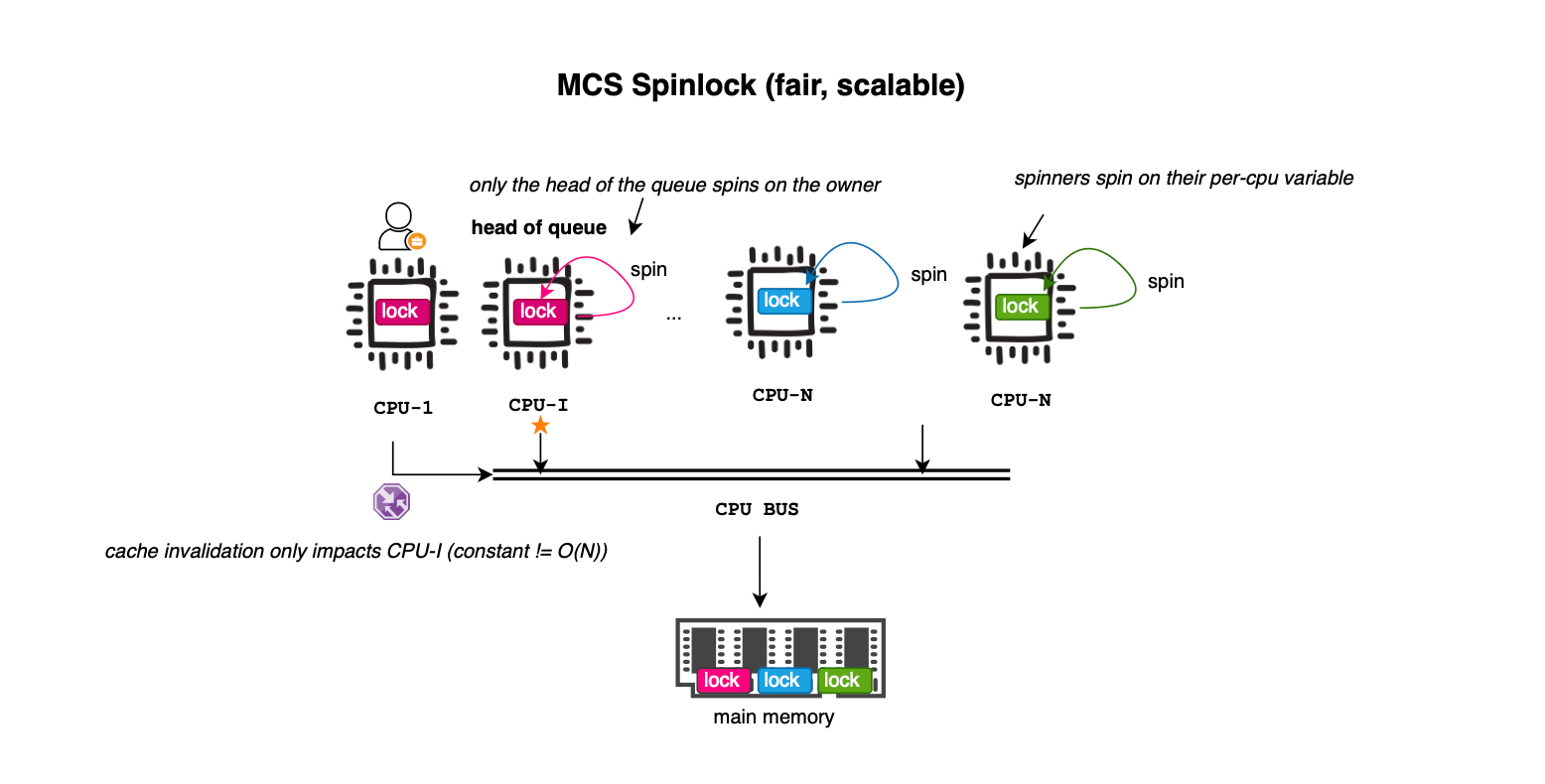
MCS locks efficiently manage contention by ensuring that each core spins on a local memory location or variable, rather than competing for a shared lock. This minimizes cache contention and results in constant O(1) bus traffic one for acquiring the lock and another for cache invalidation (i.e., updating the cache line of the next waiting thread). However, MCS lock trades storage for performance and require O(n) space (one queue node per waiting core), compared to the O(1) storage required by ticket spinlocks.
In MCS, a queue of qnode (queue node) structures is maintained. The qnode structure, represented below, contains a local locked flag, which is the variable each core spins on. The head of the queue is implicitly indicated by the locked flag (true means waiting for the lock), while the tail is explicitly pointed to by the lock structure.

In the MCS lock, the lock itself is represented as a pointer to a qnode (queue node). Unlike traditional spinlocks (and similar to ticket locks), MCS locks organize waiting CPUs into a queue rather than having them aggressively spin on a shared variable.

As shown above, when a CPU acquires the lock, it brings its own qnode data structure and atomically updates the lock to point to its qnode. This is achieved using an atomic swap or xchg operation (swap(x, y)), which places y in the memory location pointed to by x. In this case, swap(lock_node, cpu_qnode) means that the lock’s tail now points to cpu_qnode, and the swap operation returns the previous tail. If there was no previous node, the CPU acquires the lock immediately. Otherwise, the previous node’s next pointer is updated to point to cpu_qnode, and cpu_qnode spins on its local locked variable until the lock is released.

On lock release, the current lock holder follows these steps. If there is a successor (next != NULL), it simply sets the successor’s locked flag to false, allowing the next CPU in line to proceed. If there is no successor (next == NULL), it attempts to set the lock to NULL using a cas operation. If the cas operation succeeds, the lock is now free. If the CAS operation fails, it means another CPU core has already updated the next field, and the releasing CPU must wait until the successor appears before setting locked = false.
With this approach, contention is minimized, as the lock handover does not depend on the number of processors involved. This makes MCS locks significantly more scalable than ticket spinlocks. Other advanced lock variants, such as K42 MCS lock and CLH locks were proposed. Their analysis is left as an exercise.
Now, let's look at the implementation of MCS locks in the kernel. Most of the implementation is housed in kernel/locking/qspinlock.c. The data structure of the spinlock is defined as follows (4 bytes):
typedef struct qspinlock {
union {
atomic_t val;
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
};
} arch_spinlock_t;
Locked is a byte indicating whether or not a node or cpu core holds the lock (1 for true, otherwise 0).
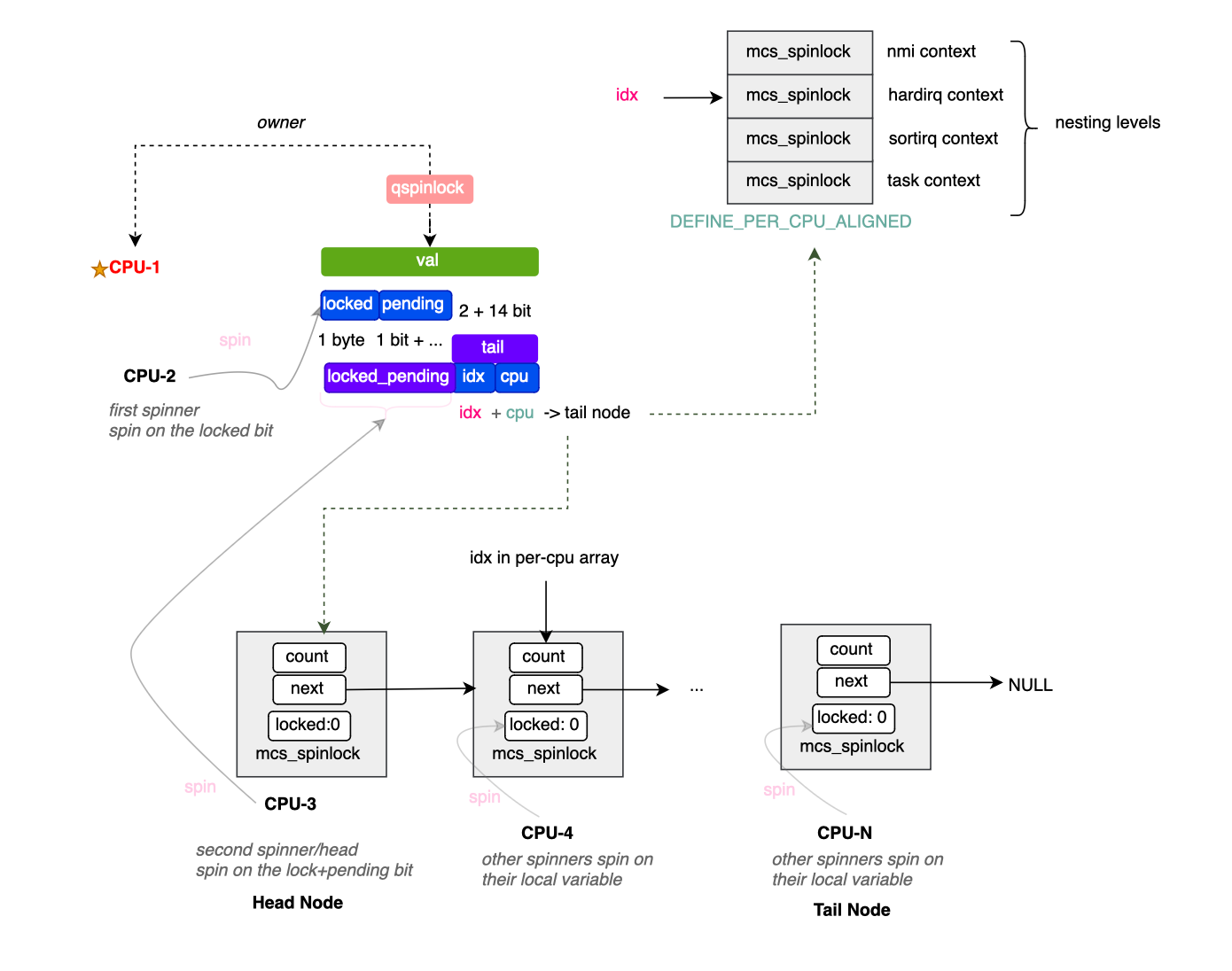
As illustrated above, a per-CPU variable is used to hold mcs_spinlock nodes. More precisely, each CPU holds four nodes, one for each kernel context. This means a spinlock can be held up to four times by the same CPU in four different contexts, allowing nested lock access and thereby avoiding deadlocks.
The tail encodes a pointer to the tail node. More specifically, it encodes the tail CPU (to access the array of mcs_spinlocknodes) and the index within that array. The tail index corresponds to the position in the per-CPU array that represents the current tail node.
Additionally, a pending bit is used to indicate to other CPUs that there is work in progress. Similar to the previous implementation, a union is used to facilitate atomic operations and provide different views for accessing the lock data (for portability).
The code to acquire the lock is defined below.
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{
int val = 0;
if (likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL))) // _Q_LOCKED_VAL = 1U << _Q_LOCKED_OFFSET; // 001
return;
queued_spin_lock_slowpath(lock, val);
}It first attempts to acquire the lock immediately, assuming there is no contention at all. It uses the atomic operation atomic_cmpxchg_acquire, defined below. If the current value is 0, it sets the locked bit to 1.
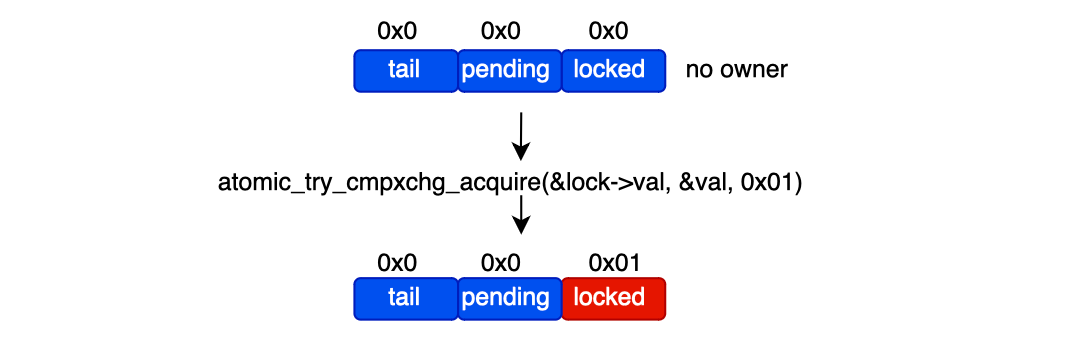
static __always_inline bool
atomic_try_cmpxchg_acquire(atomic_t *v, int *old, int new)
{
instrument_atomic_read_write(v, sizeof(*v));
instrument_atomic_read_write(old, sizeof(*old));
return raw_atomic_try_cmpxchg_acquire(v, old, new);
}For ARM, here is the compare-and-exchange implementation. As shown below, and as we have learned throughout this post, a memory fence (aquire semantic) should be added.
static __always_inline bool
raw_atomic_try_cmpxchg_acquire(atomic_t *v, int *old, int new)
{
#if defined(arch_atomic_try_cmpxchg_acquire)
return arch_atomic_try_cmpxchg_acquire(v, old, new);
#elif defined(arch_atomic_try_cmpxchg_relaxed)
bool ret = arch_atomic_try_cmpxchg_relaxed(v, old, new);
__atomic_acquire_fence();
return ret;
static inline int arch_atomic_cmpxchg_relaxed(atomic_t *ptr, int old, int new)
{
int oldval;
unsigned long res;
prefetchw(&ptr->counter);
do {
__asm__ __volatile__("@ atomic_cmpxchg\n"
"ldrex %1, [%3]\n"
"mov %0, #0\n"
"teq %1, %4\n"
"strexeq %0, %5, [%3]\n"
: "=&r" (res), "=&r" (oldval), "+Qo" (ptr->counter)
: "r" (&ptr->counter), "Ir" (old), "r" (new)
: "cc");
} while (res);
return oldval;
}If the compare-and-exchange operation fails, it means there is at least one owner. In the best-case scenario, we are in an uncontended situation (this is depicted below).
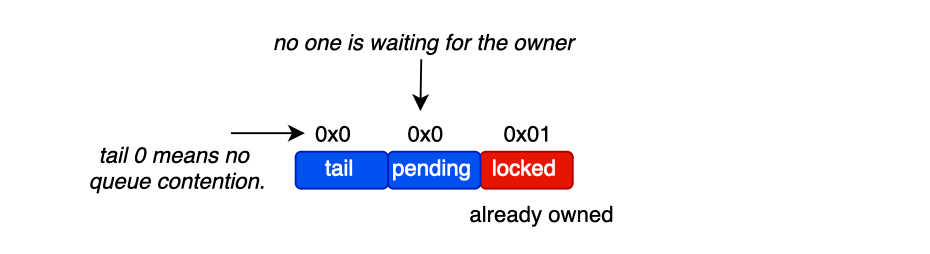
Now, the call is delegated to queued_spin_lock_slowpath for different types of spinning, depending on the current situation (pending, uncontended queue, or contended queue). Before we move forward, here is the data structure of the nodes in the MCS queue:
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked; /* 1 if lock acquired */
int count; /* nesting count, see qspinlock.c */
};As discussed earlier, each CPU has its own data structure or variable. More specifically, the kernel defines a per-CPU queue node structure for four different contexts: task, softirq, hardirq, and NMI (to allow nested locks).
static DEFINE_PER_CPU_ALIGNED(struct qnode, qnodes[MAX_NODES(=4)]);The qnode is just a proxy to mcs_spinlock and is defined as follows:
struct qnode {
struct mcs_spinlock mcs; <---
#ifdef CONFIG_PARAVIRT_SPINLOCKS
long reserved[2];
#endif
};Please refer to the earlier image depicting the whole flow to help yourself.
Ok now back to our queued_spin_lock_slowpath . First, we need to check if there is an ownership handover with zero queue contention. This means an owner is leaving, and a pending waiter is attempting to acquire the lock, so we give it a chance.
The code handling this is shown below, we essentially spin until the lock value is different from the pending state (0,1,0).
if (val == _Q_PENDING_VAL) {
int cnt = _Q_PENDING_LOOPS;
val = atomic_cond_read_relaxed(&lock->val,
(VAL != _Q_PENDING_VAL) || !cnt--);
}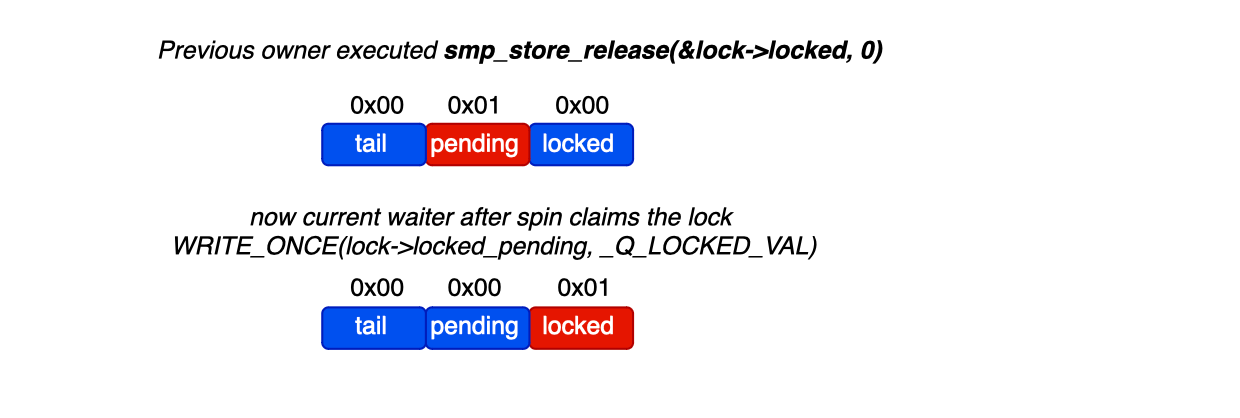
If anything other than the lock is set, it means there is contention most likely because at least the pending bit is set. In the best-case scenario, we secure the first position in the queue.
Here is the code that performs this check:
if (val & ~_Q_LOCKED_MASK)
goto queue;
Otherwise, if there is no contention, it means that the current lock value is 0,0,1 (since we have already looped on that). We then set the pending bit to claim the pending position.
val = queued_fetch_set_pending_acquire(lock);
...
static __always_inline u32 queued_fetch_set_pending_acquire(struct qspinlock *lock)
{
return atomic_fetch_or_acquire(_Q_PENDING_VAL, &lock->val);
}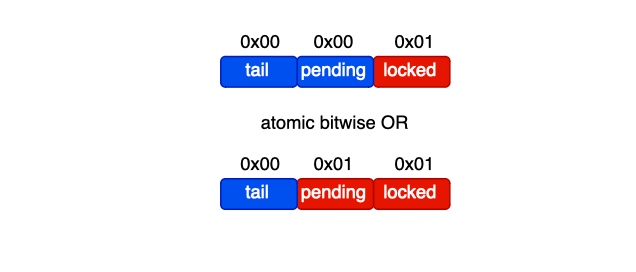
Now that we have set the pending bit, we have a pending position. We then spin on the owner, i.e., the locked byte.
if (val & _Q_LOCKED_MASK)
smp_cond_load_acquire(&lock->locked, !VAL);
Finally take ownership.
/*
* take ownership and clear the pending bit.
*
* 0,1,0 -> 0,0,1
*/
clear_pending_set_locked(lock);
lockevent_inc(lock_pending);
return;
Now that we have discussed the best-case scenario, where there is either no contention at all or only a pending situation, let's analyze the queuing process.
The first step is to prepare the new tail candidate. We increment the nested count, retrieve the current node pointer, and encode the CPU and index in the new tail, as explained earlier.
node = this_cpu_ptr(&qnodes[0].mcs);
idx = node->count++;
tail = encode_tail(smp_processor_id(), idx);If there are more than four nodes, we cannot proceed because the per-CPU variable only holds four entries. In this case, we fall back to normal spinning and then finally release once the lock is acquired (meaning we exit the queue, not the lock!). Otherwise, we retrieve our node entry and continue.
if (unlikely(idx >= MAX_NODES)) {
lockevent_inc(lock_no_node);
while (!queued_spin_trylock(lock))
cpu_relax();
goto release;
}
node = grab_mcs_node(node, idx);As illustrated before, the tail node always points to NULL and is set to locked = false (0).
node->locked = 0;
node->next = NULL;Next, we update atomically the lock's tail with our newly created node.
old = xchg_tail(lock, tail);If there was a previous node before us, we atomically add a link to it. The process involves decoding the tail, extracting the CPU and index from it, then obtaining a pointer to the corresponding mcs_spinlock node in the other CPU, and finally linking the current node to the previous node.
Once linked, we start spinning on our CPU's locked variable using arch_mcs_spin_lock_contended. During this busy loop, another CPU may enter the race, meaning we might no longer be the tail. Therefore, we must refresh the nextpointer to ensure we have the correct view of the queue.
if (old & _Q_TAIL_MASK) {
prev = decode_tail(old);
/* Link @node into the waitqueue. */
WRITE_ONCE(prev->next, node);
pv_wait_node(node, prev);
arch_mcs_spin_lock_contended(&node->locked);
/*
* While waiting for the MCS lock, the next pointer may have
* been set by another lock waiter. We optimistically load
* the next pointer & prefetch the cacheline for writing
* to reduce latency in the upcoming MCS unlock operation.
*/
next = READ_ONCE(node->next);
if (next)
prefetchw(next);
}Otherwise, if we are at the head of the queue, we spin on LOCKED_PENDING instead of LOCK, since another core is already spinning on the lock itself.
Now, the head of the queue is promoted and can spin on the LOCKED_PENDING byte (essentially monitoring both the owner and pending position).
val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK));Once the spin loop exits, it is time to acquire the lock.
The first scenario is that we are still the tail after exiting the spin loop. In this case, we can safely override the lock to 0,0,1.
if ((val & _Q_TAIL_MASK) == tail) {
if (atomic_try_cmpxchg_relaxed(&lock->val, &val, _Q_LOCKED_VAL))
goto release; /* No contention */
}
Otherwise, we should carefully modify only the locked byte without interfering with the tail. Additionally, we need to wake up the node behind us to promote it to our position meaning it will now start spinning on LOCKED_PENDING instead of its local variable.
/*
* Either somebody is queued behind us or _Q_PENDING_VAL got set
* which will then detect the remaining tail and queue behind us
* ensuring we'll see a @next.
*/
set_locked(lock);
/*
* contended path; wait for next if not observed yet, release.
*/
if (!next)
next = smp_cond_load_relaxed(&node->next, (VAL));
arch_mcs_spin_unlock_contended(&next->locked);
pv_kick_node(lock, next);The code for releasing is very simple and is shown below:
static inline void queued_spin_unlock(struct qspinlock *lock)
{
smp_store_release(&lock->locked, 0);
if (_Q_SPIN_MISO_UNLOCK)
asm volatile("miso" ::: "memory");
}It uses the release semantic barrier and sets locked = 0. Now, if there is any thread spinning, it will detect this change and take ownership of the lock (if there are others it will cascade). I have no clue what asm volatile("miso" ::: "memory"); means.
Here is the illustration provided by the kernel developers, which you should now be able to traverse on your own, try it !.

The MCS lock, however, is NUMA-oblivious, and an improvement has been proposed in CNA lock. To make the MCS lock NUMA-aware, the proposal suggests using two queues instead of one, as in the original MCS lock. Specifically, a main queue for cores or threads running on the same socket as the lock owner. A secondary queue for the remaining cores running on different sockets.
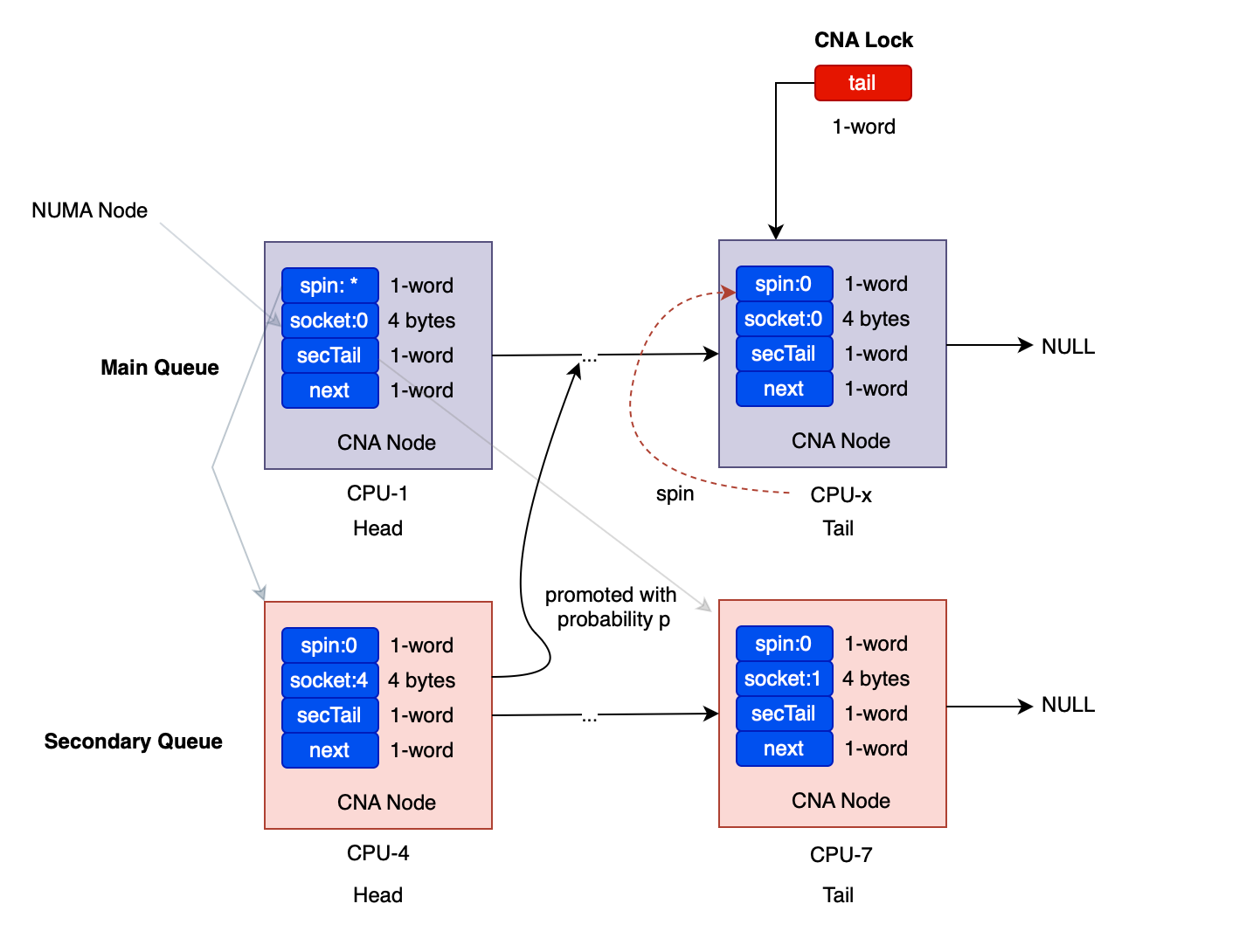
Lock Acquisition When the first core joins, it always joins the main queue, similar to MCS, by swapping the tail pointer with a pointer to its node regardless of its socket. This ensures that the basic locking mechanism remains almost the same as in MCS.
Lock Handover Once the lock is released, the owner traverses the main queue to find the first core on the same socket. Any visited nodes in between are moved to the secondary queue. A new owner is then elected from the main queue. Each queue node holds a pointer to the first node in the secondary queue. They proposed storing the secondary head pointer by recycling the spin field, as the newly elected node no longer needs to spin.
Processing the Secondary Queue The secondary queue is processed when the main queue is empty (i.e., no immediate handover is possible within the same socket). Threads can also be periodically moved from the secondary queue to the main queue. To maintain fairness, nodes from the secondary queue are promoted with a low (but non-zero) probability.
Compared to spinlocks, mutexes are used when the waiting time to acquire a lock is unpredictable, and the waiters can afford to sleep. Instead of wasting CPU cycles by continuously polling for the lock, a task sleeps or parks while waiting for the lock to become available. This allows the CPU to schedule other tasks while the lock is contented. Once the lock becomes available, the sleeping task wakes up, acquires the lock, performs its operations, and releases the lock once finished to the next waiter in line.
Unlike some other synchronization mechanisms, recursive locking is not allowed in mutexes. This means a task cannot acquire the same mutex multiple times without releasing it first. Attempting to do so may lead to deadlocks or undefined behavior.
It is recommended to always use mutexes as first choice for locking primitive unless the critical region is does not allow sharing the underlying critical section of the code or simply does not fit for the situation at hand.
Here, we specifically cover vanilla mutexes (also known as sleeping locks). WW mutexes are very similar, with only slight algorithmic differences, and are left as an exercise.
In the kernel, the data structure for mutex is implemented in include/linux/mutex.c.
struct mutex {
atomic_long_t owner;
raw_spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
struct list_head wait_list;
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};It holds a single atomic variable, owner, which encodes both a pointer to struct task_struct, representing the current lock owner (NULL if not owned), and additional metadata or state (e.g to signal immediate handoffs).
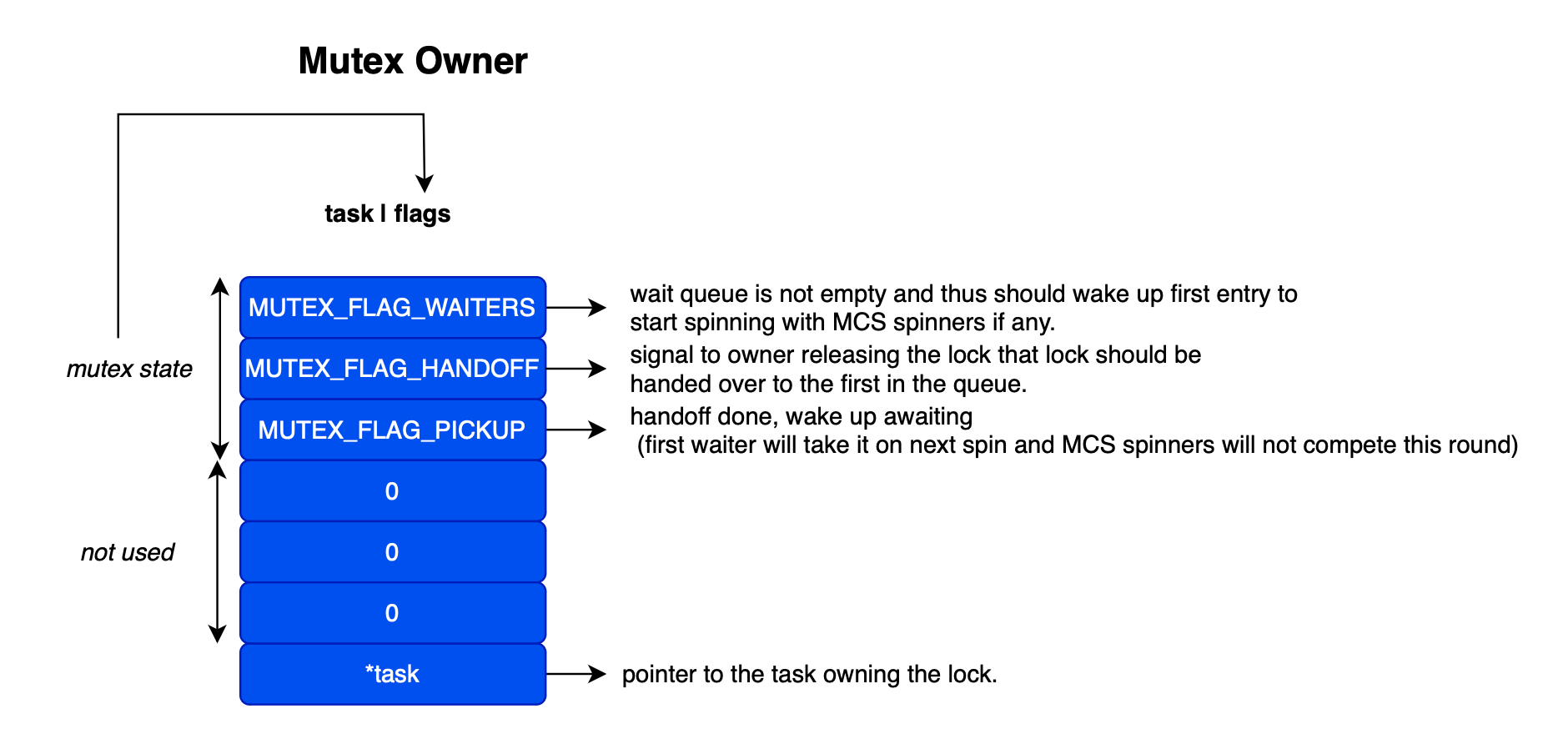
Since the address of task_struct is always aligned to at least L1_CACHE_BYTES, the lowest 6 bits are always zero(e.g., 0000 0000 0100 0000). The kernel repurposes these unused bits to store extra metadata:
MUTEX_FLAG_WAITERS): Indicates that the wait queue is non-empty.MUTEX_FLAG_HANDOFF): Signals that unlocking should hand the lock to the top waiter in the queue.MUTEX_FLAG_PICKUP): Indicates that handoff has been completed, and the next owner is waiting to pick up the lock.Additionally, mutexes maintain a wait queue and a spinlock to serialize access to the queue. There is also a possibility to use an hybrid approach i.e include conditionally a spinner using MCS lock when CONFIG_MUTEX_SPIN_ON_OWNER=y.
void
__mutex_init(struct mutex *lock, const char *name, struct lock_class_key *key)
{
atomic_long_set(&lock->owner, 0);
raw_spin_lock_init(&lock->wait_lock);
INIT_LIST_HEAD(&lock->wait_list);
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
osq_lock_init(&lock->osq);
#endif
debug_mutex_init(lock, name, key);
}As shown below, mutex locking follows a multi-path approach, where a simple, uncontended fast path is attempted first. If contention occurs, the mid-path or slow-path is executed instead.
void __sched mutex_lock(struct mutex *lock)
{
might_sleep();
if (!__mutex_trylock_fast(lock))
__mutex_lock_slowpath(lock);
}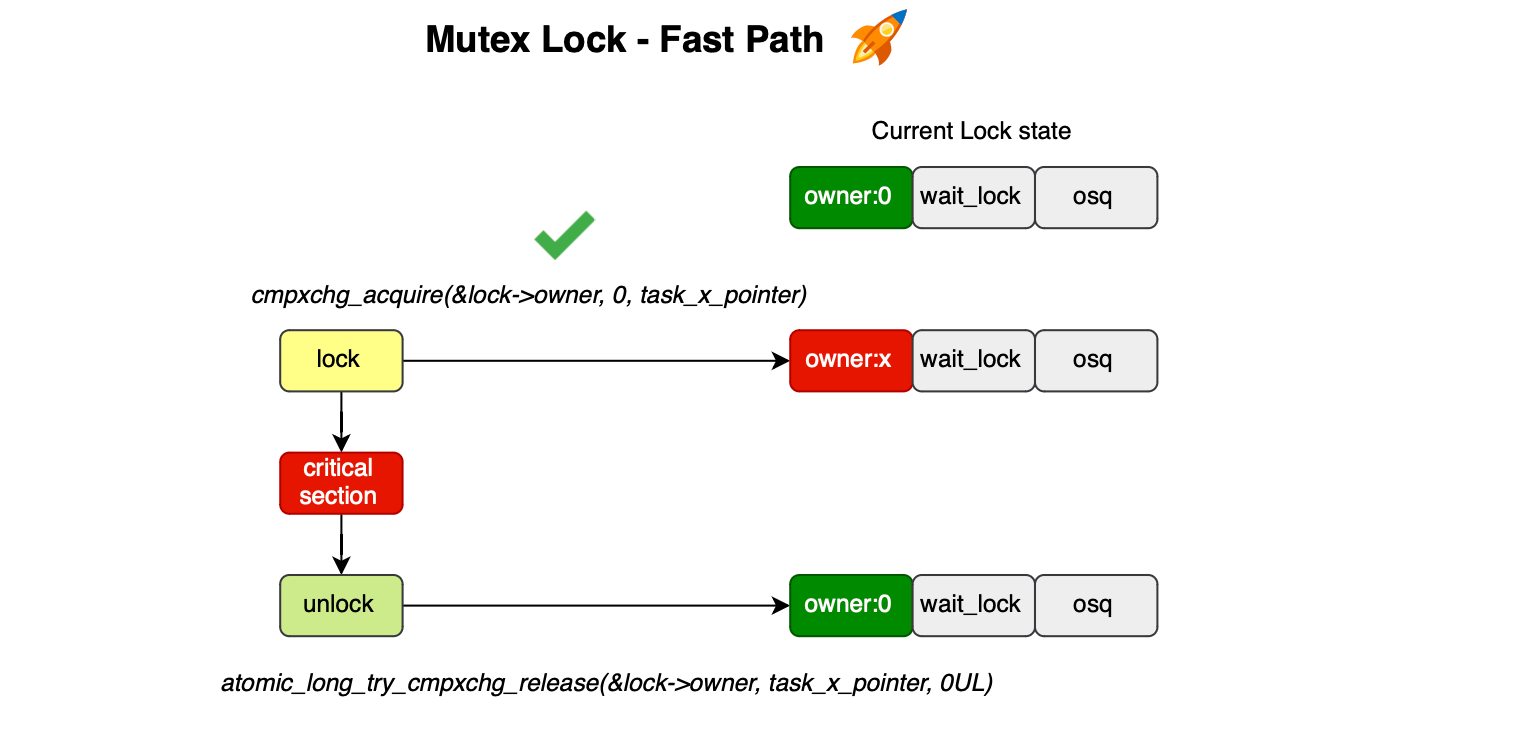
The fast path utilizes a read-modify-write atomic hardware primitive. In the best-case scenario, there is no current owner, allowing the task to acquire the mutex immediately.
static __always_inline bool __mutex_trylock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;
unsigned long zero = 0UL;
if (atomic_long_try_cmpxchg_acquire(&lock->owner, &zero, curr))
return true;
return false;
}The kernel defines the following structure for housing the waiters.
struct mutex_waiter {
struct list_head list;
struct task_struct *task;
struct ww_acquire_ctx *ww_ctx;
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
};Acquiring mutex lock - optimistic/mid path the first step in optimistic spinning is to check whether the lock owner is currently executing on a CPU and whether the current task does not need to sleep (i.e., need_resched() is false, meaning there is no higher-priority task that needs to run). This logic is defined in mutex_can_spin_on_owner(). If spinning is allowed, the task optimistically spins on the owner field, assuming the lock will be released soon. The spinning process is activated through osq_lock(&lock->osq), which enters the MCS queue by swapping the tail. If there is no MCS contention (i.e., you are at the head of the queue), you are promoted to spin directly on the owner. Otherwise, you add yourself to the queue and spin on the per-CPU variable (avoiding hitting cache bus), which the head of the queue will release later once lock is acquired.
This is illustrated below.
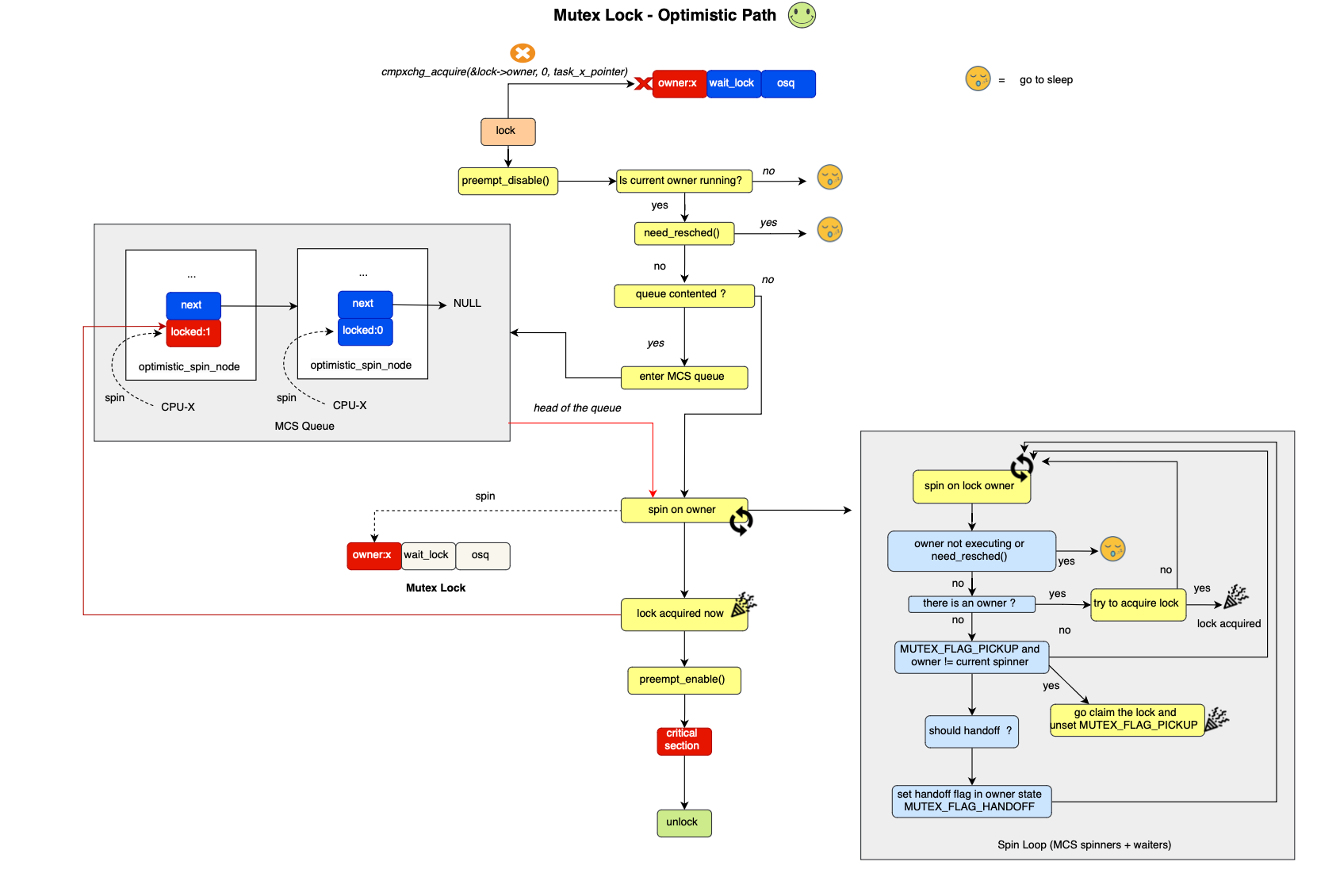
Once you reach the head of the MCS queue, you busy-wait on the lock owner until the owner changes (cmpxchg() checks against 0UL, so all 3 owner state bits have to be 0). When the head of the queue gets its turn, it must release the next in line, allowing them to begin spinning on the owner if possible otherwise it goes to sleep. At this point, the CPU that was previously at the head of the queue becomes the new owner.
Again during spinning, at any moment, an MCS spinner can go to sleep (i.e slow path) if the owner is no longer running or need_resched() becomes true. In this case, it must unlock its queued friends; otherwise, they would be spinning forever 😅.
Acquiring mutex lock - slow path if we did not manage to take the fastpath or midpath, we proceed to the slow path. The slow path consists of the following steps: acquire the spinlock (wait_lock) because we need to add waiters and synchronize access to the wait queue, check if the lock is now free if so, attempt to acquire it. Otherwise, populate the mutex waiter data structure with the current task, add the waiter to the wait list (__mutex_add_waiter -> list_add_tail(&waiter->list, list)), and set the MUTEX_FLAG_WAITERS flag. This ensures that any new task entering the mutex will see that waiters exist, including the current owner. Call set_current_state() to mark the task as INTERRUPTIBLE. Unlock the spinlock (wait_lock) and then put the task to actual sleep using schedule_preempt_disabled(). When the task wakes up, signal handoff and race with MCS spinner (if any). Finally, we set the task’s state back to running and remove the waiter from the wait list.
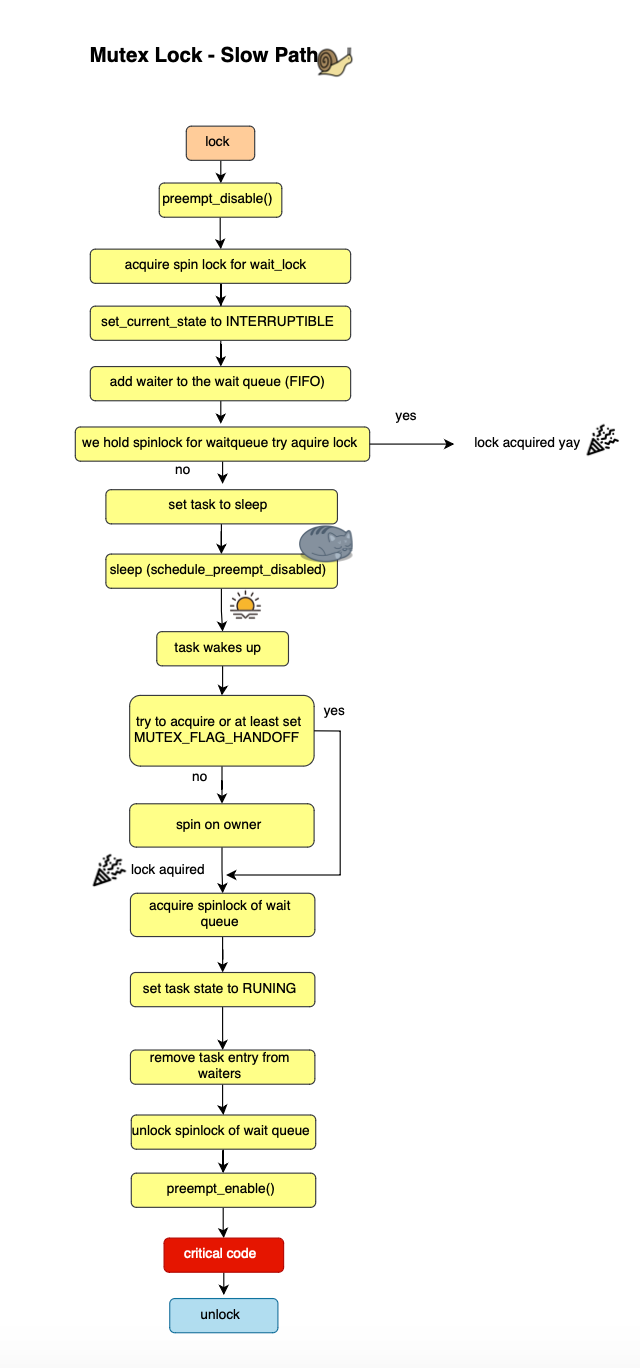
Releasing mutex lock - slow path to release the lock, the current owner (along with encoded flags) is fetched atomically from the mutex lock. Then, only if there is no handoff flag, the owner is cleared while preserving the current flags (now other spinners can fight for it). If the handoff flag is set, it means that a waiter should be granted ownership, and in this case, we do not clear the owner field, as ownership will be delegated. If the wait list is not empty, we take the first waiter, retrieve its task, and wake it up. If handoff flag is set, we are forcing ownership to the task, we need to set the state of the mutex by setting the MUTEX_FLAG_PICKUPwhile preserving MUTEX_FLAG_WAITERS. We then update the owner field accordingly and unlock the spinlock. The corresponding code is listed below.
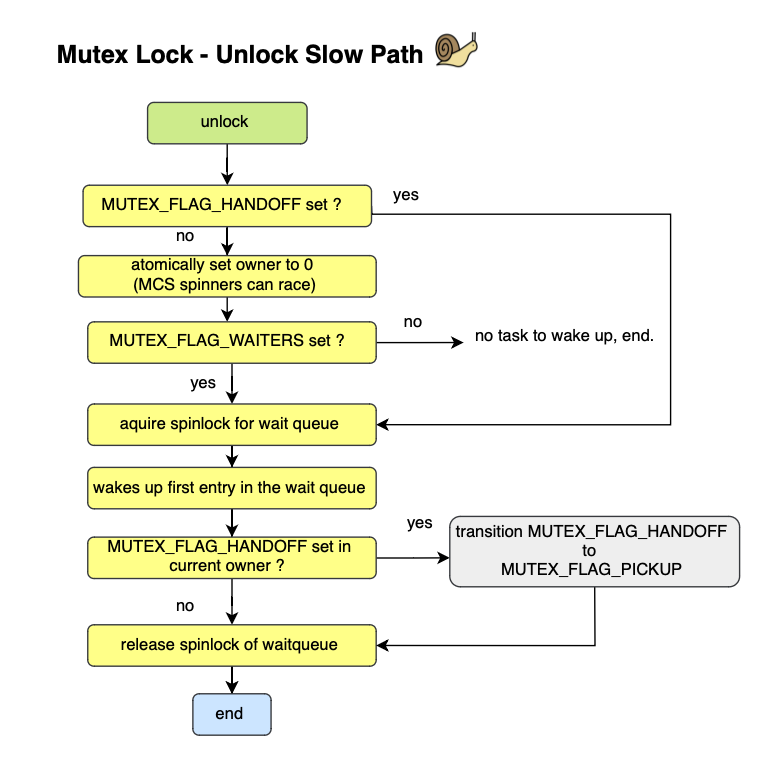
static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigned long ip)
{
struct task_struct *next = NULL;
DEFINE_WAKE_Q(wake_q);
unsigned long owner;
unsigned long flags;
mutex_release(&lock->dep_map, ip);
/*
* Release the lock before (potentially) taking the spinlock such that
* other contenders can get on with things ASAP.
*
* Except when HANDOFF, in that case we must not clear the owner field,
* but instead set it to the top waiter.
*/
owner = atomic_long_read(&lock->owner);
for (;;) {
MUTEX_WARN_ON(__owner_task(owner) != current);
MUTEX_WARN_ON(owner & MUTEX_FLAG_PICKUP);
if (owner & MUTEX_FLAG_HANDOFF)
break;
if (atomic_long_try_cmpxchg_release(&lock->owner, &owner, __owner_flags(owner))) {
if (owner & MUTEX_FLAG_WAITERS)
break;
return;
}
}
raw_spin_lock_irqsave(&lock->wait_lock, flags);
debug_mutex_unlock(lock);
if (!list_empty(&lock->wait_list)) {
/* get the first entry from the wait-list: */
struct mutex_waiter *waiter =
list_first_entry(&lock->wait_list,
struct mutex_waiter, list);
next = waiter->task;
debug_mutex_wake_waiter(lock, waiter);
wake_q_add(&wake_q, next);
}
if (owner & MUTEX_FLAG_HANDOFF)
__mutex_handoff(lock, next);
raw_spin_unlock_irqrestore_wake(&lock->wait_lock, flags, &wake_q);
}A mutex ensures that only one thread can enter a critical section at a time, enforcing strict ownership i.e only the thread that locks the mutex can unlock it. In contrast, a semaphore allows multiple threads to enter a critical section concurrently, effectively applying backpressure and controlling how many processors can access the shared resource simultaneously.
Semaphores in the Linux kernel are represented as follows:
struct semaphore {
raw_spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
Where lock is a spinlock used to serialize access to the semaphore's count. count represents the number of available resources, and wait_list is a wait queue that holds tasks waiting to acquire the semaphore.
Semaphores are acquired and released using the down() and up() APIs. Below is the kernel implementation:
void down(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
__down(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
The logic here is straightforward, a spinlock ensures atomic access to the count. If count is greater than zero (indicating availability), it decrements count and grants access. Otherwise, it calls __down(), which puts the calling task to sleep.
If the semaphore is unavailable, the task is added to the wait queue and put to sleep. Here’s the implementation:
static inline int __sched __down_common(struct semaphore *sem, long state,
long timeout)
{
struct semaphore_waiter waiter;
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = current;
waiter.up = false;
for (;;) {
if (signal_pending_state(state, current))
goto interrupted;
if (unlikely(timeout <= 0))
goto timed_out;
__set_current_state(state);
raw_spin_unlock_irq(&sem->lock);
timeout = schedule_timeout(timeout);
raw_spin_lock_irq(&sem->lock);
if (waiter.up)
return 0;
}
}
The task is added to the wait queue and enters a loop where it checks for signals and timeouts. If still waiting, it sleeps (schedule_timeout(timeout)) and rechecks on wake-up. If waiter.up is set (indicating the semaphore was released), the function exits successfully.
Releasing a semaphore is simpler:
void up(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;
else
__up(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
Above the spinlock ensures atomic modification. If no tasks are waiting, count is incremented. Otherwise, if tasks are waiting, __up() wakes up the first task without increasing count, as the next task is guaranteed access. Here is the code for _up():
static noinline void __sched __up(struct semaphore *sem)
{
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
struct semaphore_waiter, list);
list_del(&waiter->list);
waiter->up = true;
wake_up_process(waiter->task);
}
The first waiting task is dequeued. waiter->up is set to indicate it has been granted access. The task is woken up (wake_up_process(waiter->task)).
Unlike mutexes, semaphores do not enforce strict ownership. Any thread can release a semaphore, making them more suitable for signaling rather than strict mutual exclusion.Other types of semaphores, such as read-write semaphores (rw_semaphores), provide more advanced concurrency control but are left as an exercise.
Spinlocks ensure mutual exclusion among concurrent processors for both reads and writes. In reader-writer or rw locks, the lock can be owned by multiple readers simultaneously. In contrast, when a CPU attempts to acquire a write lock, it must wait for exclusive access that is, for all readers to release the lock. Naturally, only one write lock can be owned at any given time.
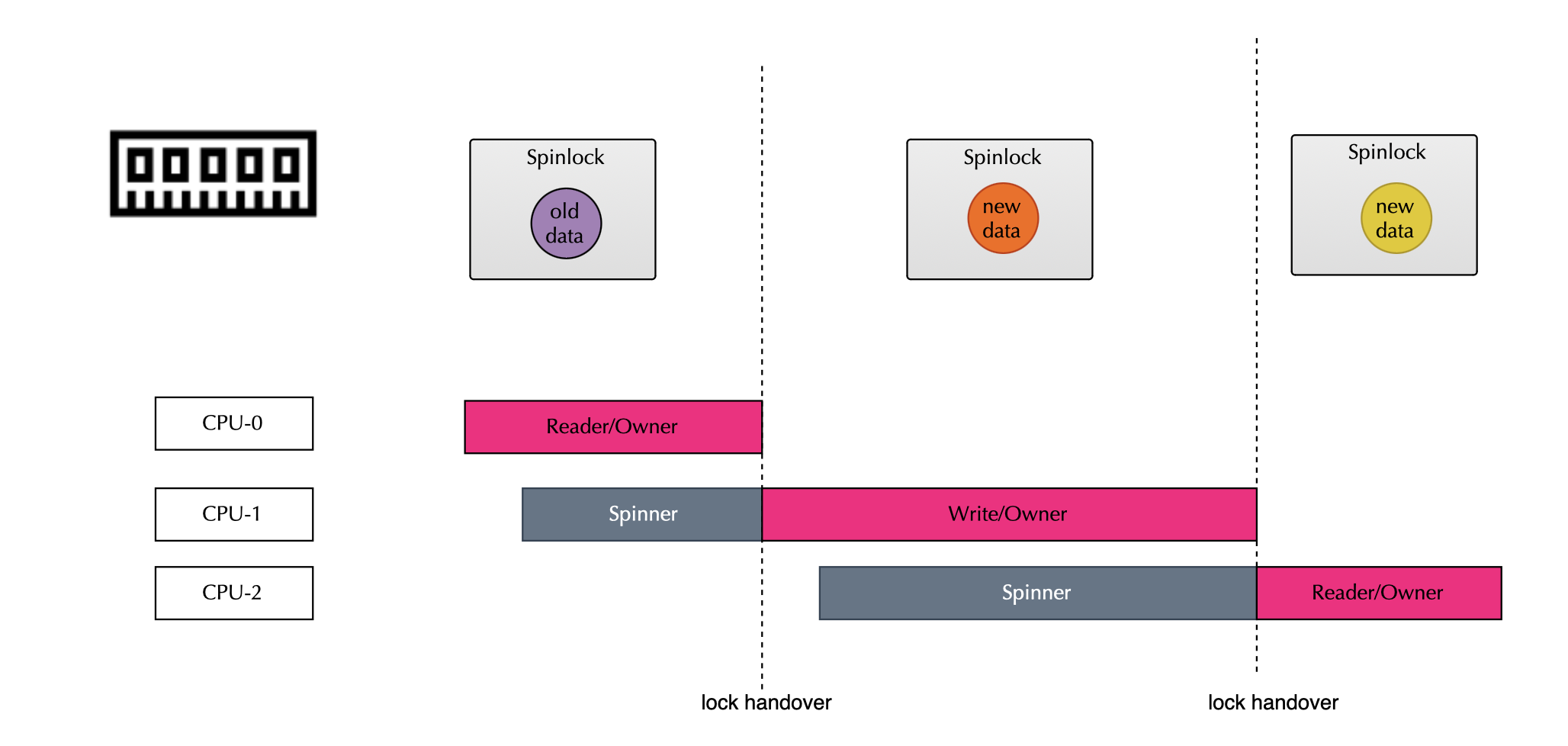
RW locks do not have to be fair and are not scalable, which led to the proposal of Read-Copy-Update (RCU) to achieve lower overhead and better scalability when updates occur infrequently compared to loads (RCUs are not ideal for frequent writes).
The core idea behind RCU is very simple (yet the linux kernel implementation is quite intense), instead of blocking subsequent readers until writes complete, it defers deletions until all conflicting readers have finished. By maintaining multiple data versions, RCU allows concurrent reads and writes, which contrasts with spinlocks (where only one reader or writer is permitted at a time) and RW locks (which allow multiple readers or one writer). RCU incurs zero overhead to readers in non-preemptible kernels !.
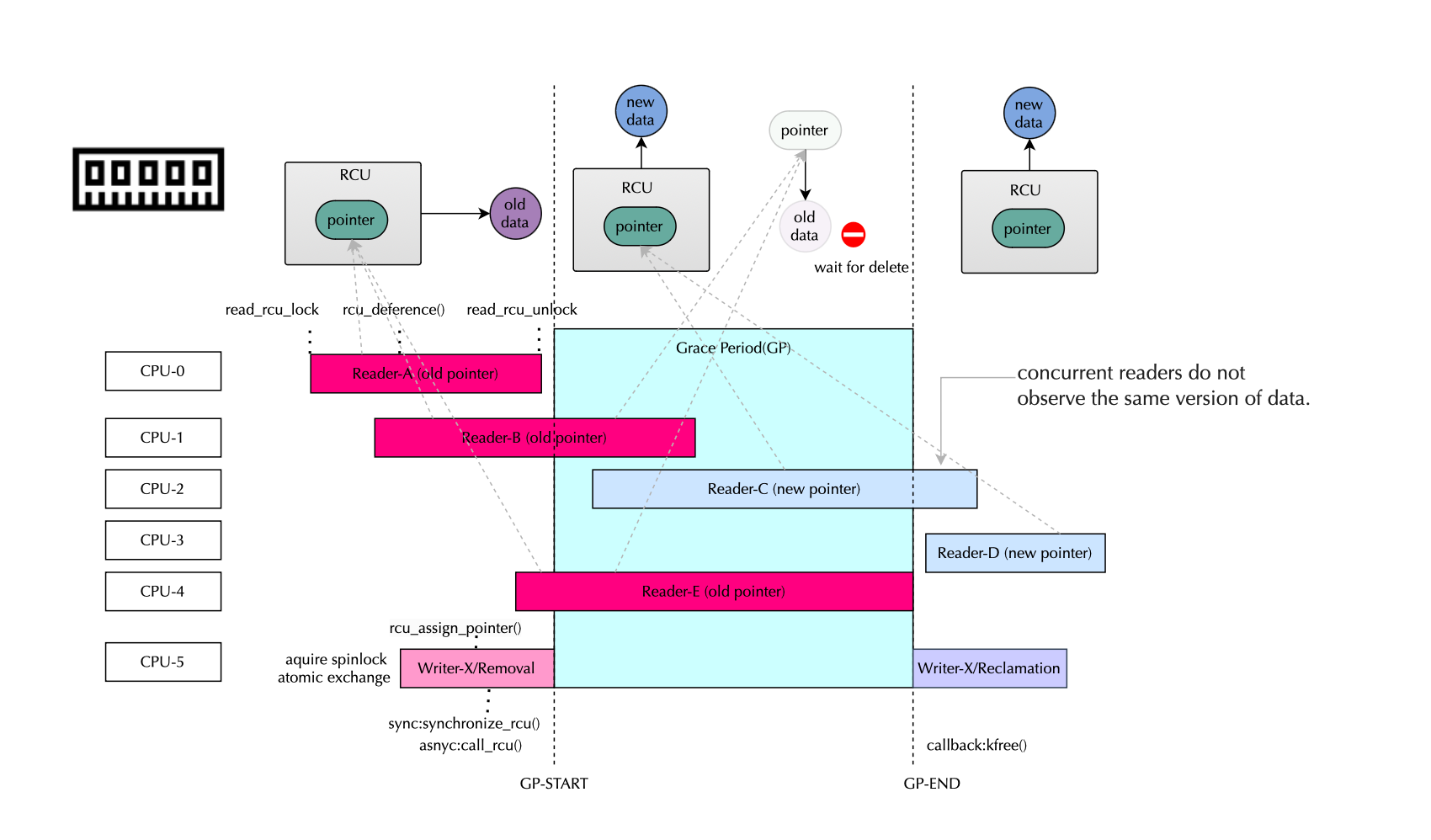
Basically, in RCU, writers update data structures (specifically the pointer) while ensuring that all concurrent readers accessing the shared structure finish their read operations before reclamation (releasing memory), meaning readers continue accessing a pointer to a previous version of the structure hence the name Read-Copy-Update thereby preventing abrupt pointer modifications and avoiding issues such as dereferencing null pointers that could crash readers.
The update process in RCU is split into two phases: removal and reclamation. The writer can perform the removal phase immediately but defers the reclamation phase until all readers active during the removal phase have finished accessing the data (in simple form wait for all online cpus to perform context switch).
RCU-protected section is delimited by rcu_read_lock() and rcu_read_unlock(). The writer must wait for these read-side critical sections to finish before freeing memory, either by blocking with synchronize_rcu() or by using a callback mechanism with call_rcu(). Later, RCU read-side critical sections that occur after the removal (but before reclamation) do not reference the newly removed structure but instead access the updated pointer.
Writing and reading is basically achieved using rcu_assign_pointer() and rcu_dereference(), which are part of the RCU API for loading and updating data. They can be thought of as a publish-subscribe mechanism, and can be used to protect any data structure.
In the Linux kernel, various data structures such as lists, queues, and trees have RCU APIs that can be leveraged. As I will cover in a future post, the Maple tree (which replaced the red-black tree and doubly linked lists in Linux) uses RCU.
Note, however, that RCU does not protect concurrent writers or producers. That is, to avoid race conditions between writers, you need to introduce an additional synchronization primitive (e.g spinlock) to ensure atomicity when updating the data structure. This is similar to our earlier discussion on BPF ring buffers.
As shown below, rcu_assign_pointer takes as parameters p a pointer and a value v to assign or publish. In order to protect the RCU pointer from being accessed directly i.e without going though rcu_dereference or rcu_assign_pointer, it is marked with __rcu during initialization (annotation is only for static analysis and does not generate any code).
#define rcu_assign_pointer(p, v) \
do { \
uintptr_t _r_a_p__v = (uintptr_t)(v); \
rcu_check_sparse(p, __rcu); \
\
if (__builtin_constant_p(v) && (_r_a_p__v) == (uintptr_t)NULL) \
WRITE_ONCE((p), (typeof(p))(_r_a_p__v)); \
else \
smp_store_release(&p, RCU_INITIALIZER((typeof(p))_r_a_p__v)); \
} while (0)#define RCU_INITIALIZER(v) (typeof(*(v)) __force __rcu *)(v)rcu_check_parse is purely used for static analysis and generates a warning if the pointer is not annotated with __rcu .
#define rcu_check_sparse(p, space) \
((void)(((typeof(*p) space *)p) == p))To ensure that the data is initialized before the new pointer
becomes visible to other cores or readers a release barrier (smp_store_release) is used.
The code for rcu_dereference is shown below.
#define rcu_dereference(p) rcu_dereference_check(p, 0)
...
#define rcu_dereference_check(p, c) \
__rcu_dereference_check((p), __UNIQUE_ID(rcu), \
(c) || rcu_read_lock_held(), __rcu)
...
#define __rcu_dereference_check(p, local, c, space) \
({ \
/* Dependency order vs. p above. */ \
typeof(*p) *local = (typeof(*p) *__force)READ_ONCE(p); \
RCU_LOCKDEP_WARN(!(c), "suspicious rcu_dereference_check() usage"); \
rcu_check_sparse(p, space); \
((typeof(*p) __force __kernel *)(local)); \
})
The pointer is accessed safely using READ_ONCE() (as discussed earlier, preventing compiler optimizations). Access to rcu_dereference() must always be performed within an rcu_read_lock()/rcu_read_unlock() section.
The __rcu_dereference_check() function reads a copy of the variable pointed to by the RCU-protected pointer (sparse: __rcu annotation is checked) and finally returns the enhanced pointer as a local variable.
Writers use rcu_dereference_protected(), which does not require being inside an RCU critical section, unlike rcu_dereference().
#define rcu_dereference_protected(p, c) \
__rcu_dereference_protected((p), __UNIQUE_ID(rcu), (c), __rcu)
....
#define __rcu_dereference_protected(p, local, c, space) \
({ \
RCU_LOCKDEP_WARN(!(c), "suspicious rcu_dereference_protected() usage"); \
rcu_check_sparse(p, space); \
((typeof(*p) __force __kernel *)(p)); \The key idea of RCU is that readers do not wait for writers to finish. Instead, a writer waits for all active readers before and once the grace period finishes, reclamation happens. However, it should be stressed that RCU does not care how writers synchronize their updates. However, it expects appropriate locking mechanisms such as spinlock primitives to be used when performing writes.
Since the data being modified is accessed via a pointer, one can eliminate the need for spinlocks in some cases by using atomic exchange (xchg) to update the pointer atomically. As long as synchronize_rcu() is called before freeing memory.
Below is an example demonstrating how spinlocks can be combined with concurrent readers to safely free elements.
/* Reader*/
rcu_read_lock();
list_for_each_entry_rcu(i, head) {
/* Critical section: no sleeping, blocking calls, or context switches allowed */
}
rcu_read_unlock();
/* Updater*/
spin_lock(&lock);
list_del_rcu(&node->list);
spin_unlock(&lock);
synchronize_rcu(); // Wait all pre-existing readers have finished
kfree(node);
/* Writer*/
spin_lock(&lock);
list_add_rcu(&node->list, head);
spin_unlock(&lock);
I will stop here and cover the RCU implementation (both preemptive and non-preemptive Tree RCU) in a future post. Here are some good references:
Memory Model = Instruction Reordering + Store Atomicity: https://acg.cis.upenn.edu/rg_papers/memo-493.pdf
Understanding OrderAccess, Managing Data Races in a Hostile Environment: https://cr.openjdk.org/~dholmes/presentations/Understanding-OrderAccess-v1.1.pdf
Shared Memory Consistency Models: A Tutorial: https://www.lri.fr/~cecile/ENSEIGNEMENT/IPAR/Exposes/Consistency.pdf
Lockless patterns: some final topics: https://lwn.net/Articles/850202/
OZZ: Identifying Kernel Out-of-Order Concurrency Bugs with In-Vivo Memory Access Reordering: https://dl.acm.org/doi/pdf/10.1145/3694715.3695944
Memory Model and Synchronization Primitive - Part 1: Memory Barrier: https://www.alibabacloud.com/blog/memory-model-and-synchronization-primitive—part-1-memory-barrier_597460
Nine ways to break your systems code using volatile: https://blog.regehr.org/archives/28
On lock-free programming patterns: https://www.researchgate.net/publication/295858544_On_lock-free_programming_patterns
Non-scalable locks are dangerous: https://www.kernel.org/doc/ols/2012/ols2012-zeldovich.pdf
Everything You Always Wanted to Know About Synchronization but Were Afraid to Ask: https://dl.acm.org/doi/pdf/10.1145/2517349.2522714
Verifying and Optimizing Compact NUMA-Aware Locks on Weak Memory Models: https://arxiv.org/pdf/2111.15240
Java Memory Model Under The Hood: https://gvsmirnov.ru/blog/tech/2014/02/10/jmm-under-the-hood.html
Memory Barriers: a Hardware View for Software Hackers, Paul E. McKenney Linux Technology Center.
Memory Models for C/C++ Programmers: https://arxiv.org/pdf/1803.04432
Data Races, what are they, and why are they evil? https://liyz.pl/2020/08/01/2020-8-1-datarace/
Load-Acquire and Store-Release instructions: https://developer.arm.com/documentation/102336/0100/Load-Acquire-and-Store-Release-instructions.
Unreliable Guide To Locking: https://www.kernel.org/doc/html/v4.19/kernel-hacking/locking.html
An Interaction of Coherence Protocols and Memory Consistency Models in DSM Systems: https://dl.acm.org/doi/pdf/10.1145/271019.271027
A Primer on Memory Consistency and Cache Coherence: https://pages.cs.wisc.edu/~markhill/papers/primer2020_2nd_edition.pdf
Java Memory Model (JMM): https://www.cs.umd.edu/~pugh/java/memoryModel/ProposedFinalDraft.pdf
Symmetric Multi-Processing: https://linux-kernel-labs.github.io/refs/pull/183/merge/lectures/smp.html
Improving ticket spinlocks: https://lwn.net/Articles/531254/
Jeff Preshing posts: https://preshing.com
Is Parallel Programming Hard, And, If So, What Can You Do About It?: https://arxiv.org/pdf/1701.00854
Documentation/RCU/rcu_dereference.rst: https://www.kernel.org/doc/Documentation/RCU/rcu_dereference.rst
Provided that data dependencies between the instructions are preserved, CPUs and compilers are allowed to reorder instructions in the absence of memory fences. In order to hide the latency of stores, some architecture relaxes program order, trading atomicity for performance.
While full memory barriers prevent both CPU and compiler reordering, they introduce performance overhead. Using less aggressive barriers such as one-way acquire/release barriers is usually sufficient.
Synchronization primitives that enforce mutual exclusion require careful programming. Programs can be interrupted due to preemption (to prevent a task monopolizing the CPU) or due to interrupts. Depending on the nature of access to the critical section, appropriate synchronization APIs should be used.
Semaphores and mutexes send waiters to sleep when a lock cannot be acquired immediately, making them suitable when contention is expected and the lock is not expected to be acquired very soon (linux mutex implementation uses hybrid approach). Semaphores and mutexes cannot be used in an interrupt context. In contrast, spinlocks allow multiple cores to actively spin until the lock is acquired. Therefore, the critical section should be kept short, as spinlocks cannot sleep.
RCU is a specialized synchronization primitive great in scenarios where a data structure experiences mostly reads with few updates.
Much effort for scalable locks has been devoted to minimization of the traffic necessary to maintain coherence on bus systems. For better performance, per-cpu variables were introduced.
Finally remember that memory consistency model = coherence protocol + memory ordering.
Do not hesitate to read the Linux document Documentation/memory-barriers.txt. It covers various topics not included in this document, such as speculative loads.
Please let me know if you think you found a mistake or I misunderstood something.

