AI, Cybersecurity, Software Engineering and Beyond.
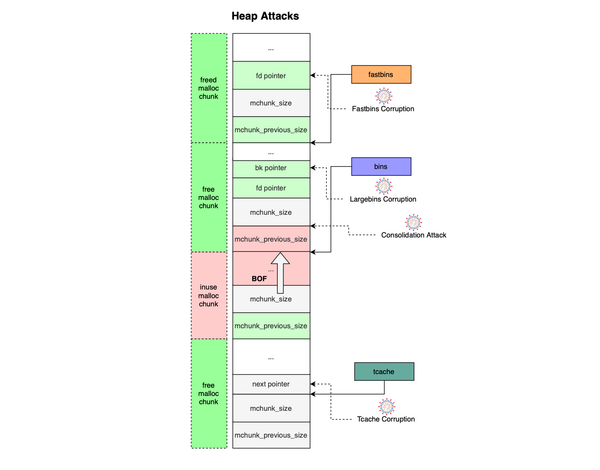
While diving into BPF internals, I discovered certain types of attacks that can be used to mess with the internals of security solutions relying on BPF for prevention and detection. Specifically, an attacker could silently disable the delivery and execution of BPF programs, by stealing a file descriptor and completely

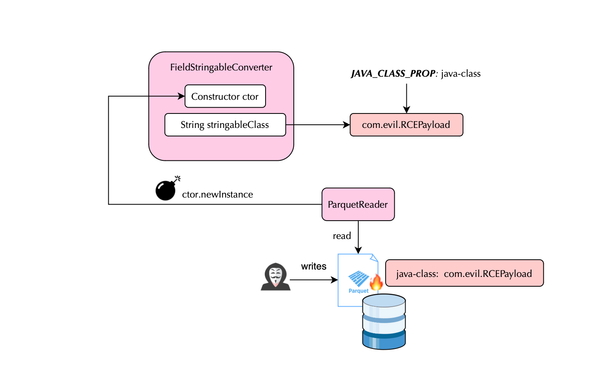
Last week, a vulnerability in Apache Parquet’s Java library CVE-2025-30065 was published, carrying a CVSS score of 10.0. Parquet is widely used in modern data pipelines and analytics systems, including technologies like Apache Spark, Trino, Iceberg, etc. As a result, a malicious actor who is able
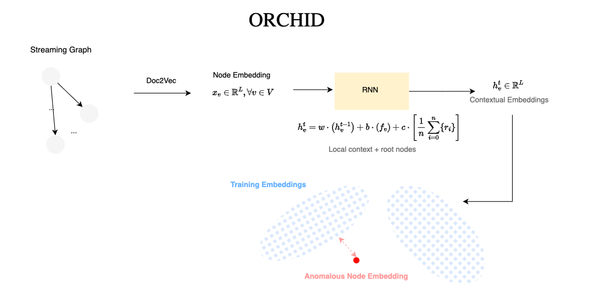
During the last few months, I spent a significant amount of time reviewing system modeling literature and exploring the current advancements in this area of research. Specifically, my goal was to apply advanced machine learning including deep learning techniques to efficiently represent system events in a euclidean space and detect
The goal of this post is to provide an in-depth discussion of BPF ring buffers, covering their internals, including memory allocation, user-space mapping, locking mechanisms, and efficient data sharing with user-land processes. This article is quite detailed, and I understand that some of you may not want
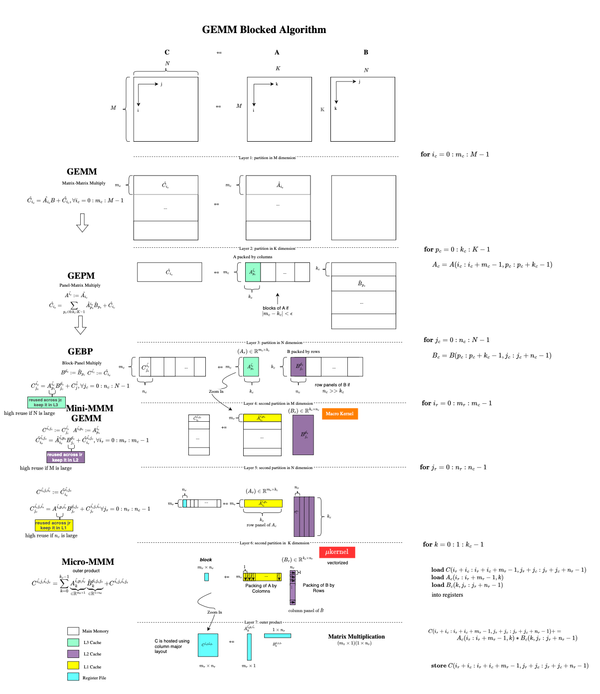
Writing performant, portable, and correct parallel programs in multiprocessor systems or SMP, where each processor may load and store to a single shared address space, is not trivial. Programmers must be aware of the underlying memory semantics, i.e. the system optimizations performed by the clever beast hardware or cpu.
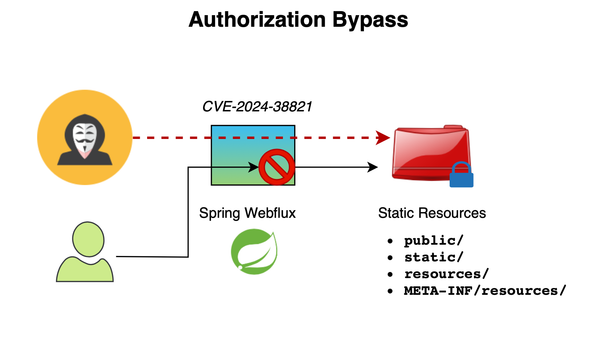
Spring announced on October 25, 2024, CVE-2024-38821, a critical vulnerability allowing attackers to access restricted resources under certain circumstances. The vulnerability specifically impacts Spring WebFlux's static resource serving. For it to affect an application, all of the following must be true: It must be a WebFlux
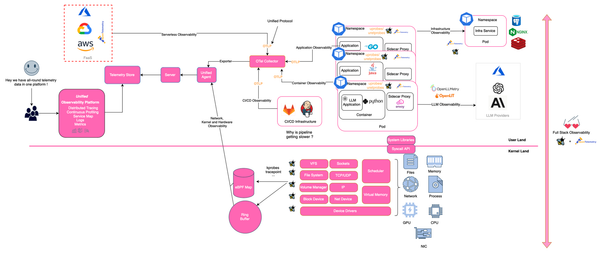
Observability represents the ability to measure how well the internal state of a system can be inferred solely by its external outputs. Observability and the challenges associated with it is by no means a new problem and have existed for decades. Observability is a necessary precursor to ensure the reliability
Last week, I saw this post (https://www.theregister.com/2024/07/12/cisa_broke_into_fed_agency/) discussing the exploitation of an unpatched Oracle vulnerability. The unnamed federal agency took over two weeks to apply the available patch 😜. When I read the post, I was like: Is RASP or
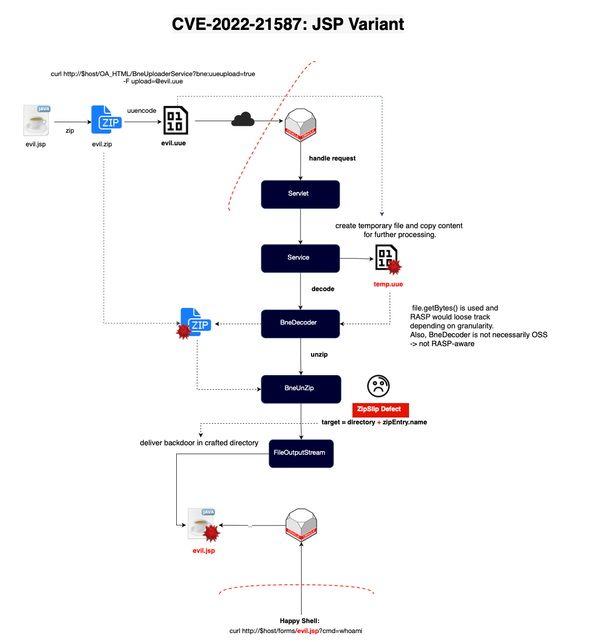
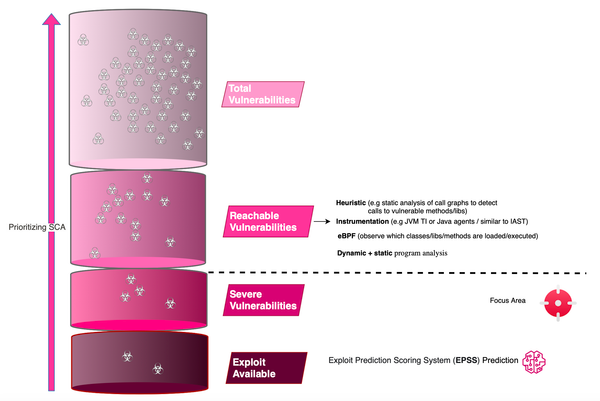
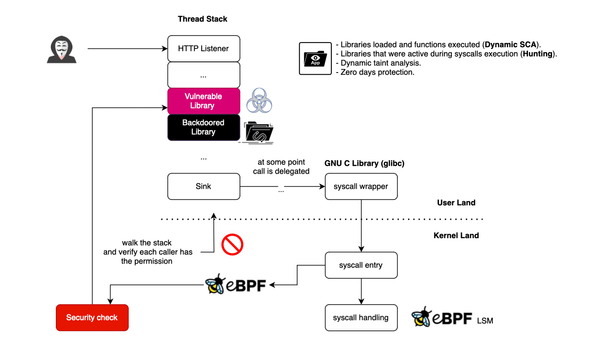
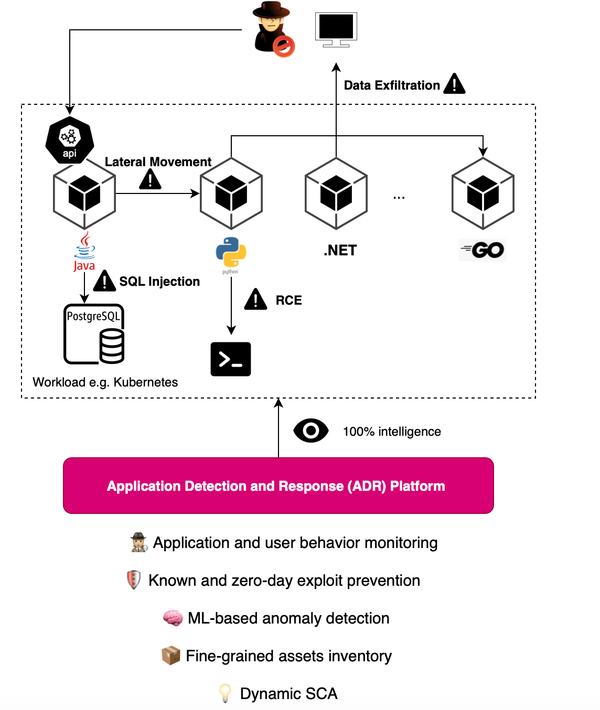
Vulnerabilities are everywhere and here to stay. Defects can exist in source code or third-party and open-source software. However, not all vulnerabilities pose the same threat, and code that is exploitable in one context may not be exploitable in another. Focusing on what matters is crucial for remediation