AI, Cybersecurity, Software Engineering and Beyond.
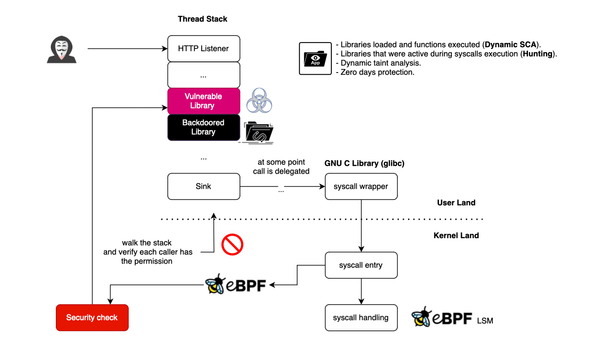
In this blog post, I will discuss how one can use eBPF for runtime application security to detect library profile deviations. More specifically we will use stack traces to observe what libraries/functions are active in the stack when a system call is issued. Stack traces are very valuable signals

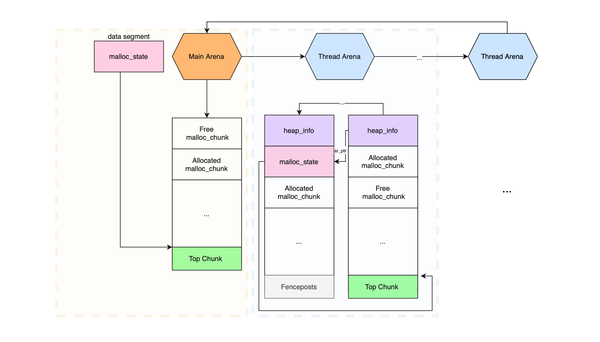
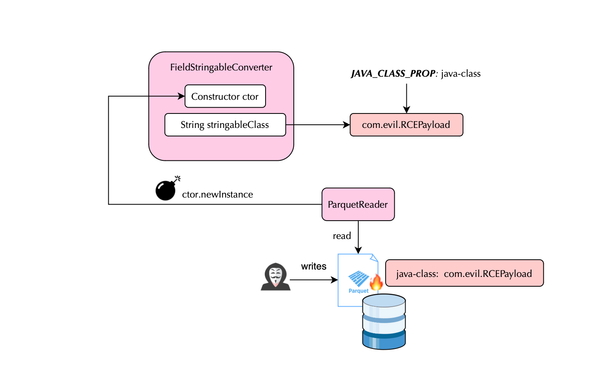
In this post, we will explore why RASP, or Runtime Application Self-Protection, is not always effective in protecting your Java applications and can be bypassed. Introduction Open source security has long been problematic, yet many organizations continue to overlook its importance. Existing sandboxing solutions such as seccomp and LSMs (SELinux,
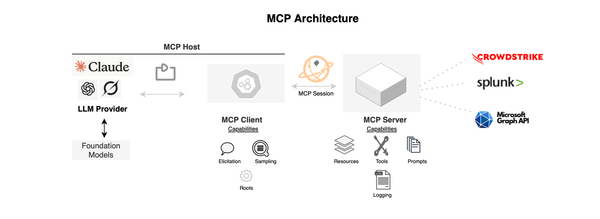
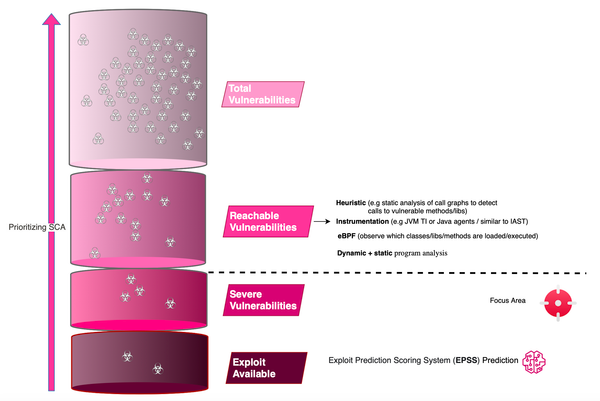
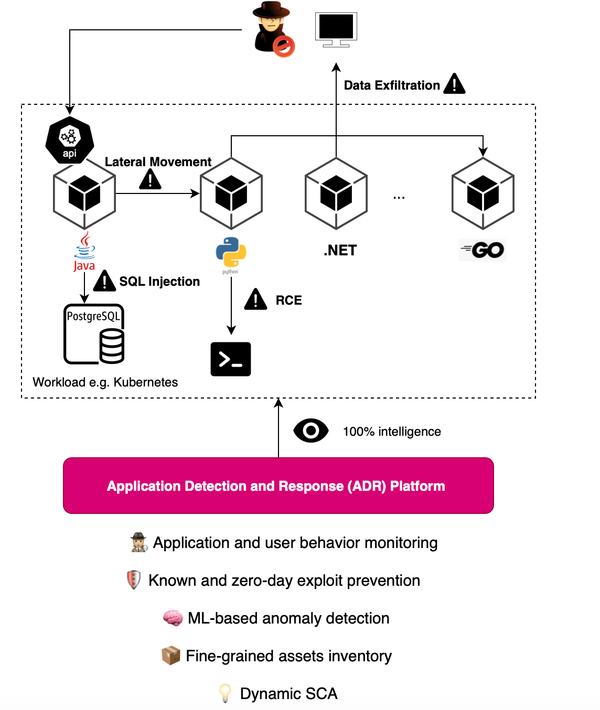
Few companies are starting to pave the way for Application and Detection Response (ADR) including Oligo Security, RevealSecurity and Miggo Security. You may find yourself quickly lost in understanding what these solutions aim to tackle. First, each of these solutions likely focuses on what they do best. For example, Oligo

Cybercrime is growing at a dizzying pace and projected to inflict $9.5 trillion USD global cost in 2024. Java-based applications, often targeted by hackers due to their known and zero-day vulnerabilities, are at high risk. The increased reliance of many Java applications on open source frameworks such as Spring
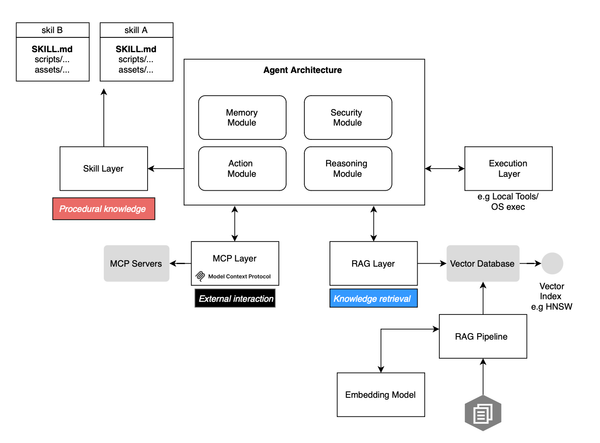
Large Language Models (LLMs) have evolved from being merely passive text generators with limited capabilities to becoming autonomous or semi-autonomous agents navigating complex environments and offering actionable insights. This transformation equips them with a diverse set of tools, perception modules to interpret signals from various modalities, and memory systems to
Multimodal Large Language Models (MLLMs) are garnering significant attention. There has been a plethora of work in recent months dedicated to the development of MLLMs [Flamingo, NExT-GPT, Gemini...]. The key challenge for MLLMs lies in effectively injecting multimodal-data in LLMs. Most research begins with pre-trained LLMs and employs modality-specific encoders
Large Language Models (LLMs) are developed to understand the probability distribution that governs the world language space. Autoregressive models approximate this distribution by predicting subsequent words based on previous context, forming a Markov chain. World knowledge (often referred as parametric knowledge) is stored implicitly within the model's parameters.
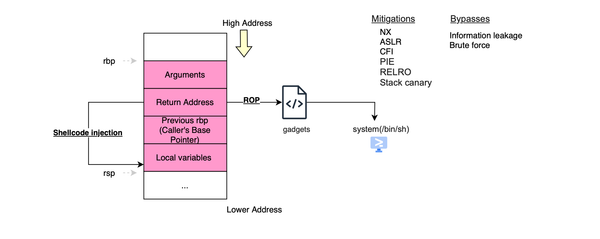
Pre-reading Requirements In this post, I assume you have a basic background in software and cybersecurity engineering. However, even if you're not highly technical, don't worry, I will ensure that you can grasp and understand the intricacies of the vulnerability and the exploit, as well as
Large Language Models (LLMs), exemplified by OpenAI’s GPT-4 and Meta’s LLaMA, continue to impress us with their capabilities, which have surpassed expectations from just a few years ago. Recently, the research community has shifted its focus towards the optimal and efficient usage of resources. Concepts like the Mixture