
During the last few months, I spent a significant amount of time reviewing system modeling literature and exploring the current advancements in this area of research. Specifically, my goal was to apply advanced machine learning including deep learning techniques to efficiently represent system events in a euclidean space and detect

During the last few months, I spent a significant amount of time reviewing system modeling literature and exploring the current advancements in this area of research. Specifically, my goal was to apply advanced machine learning including deep learning techniques to efficiently represent system events in a euclidean space and detect aberrant executions.
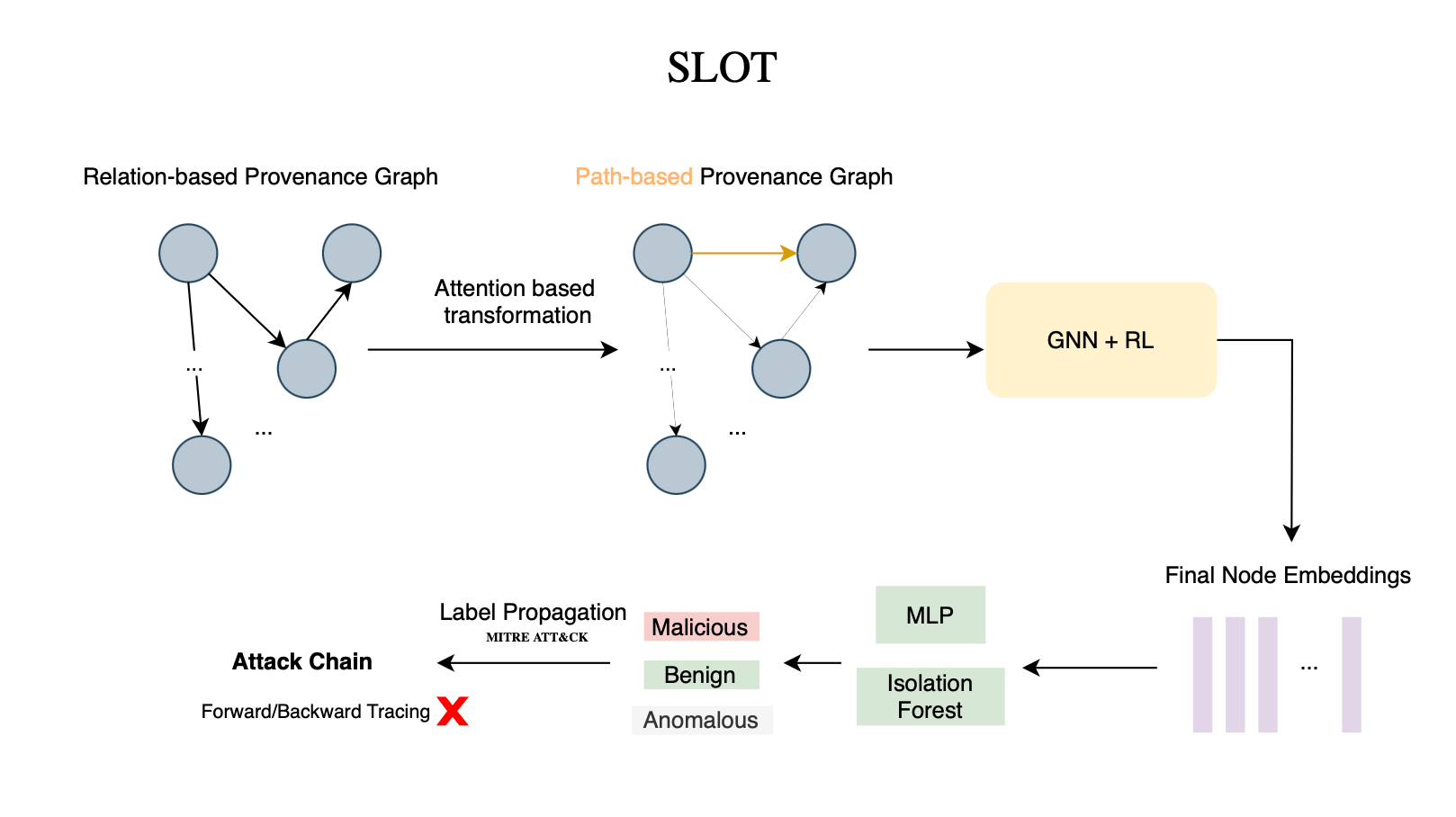
I read several surveys, papers and developed an intense roadmap that included topics such as sequence-based representations (inspired by Forrest et al.'s [1] pioneering work), Hidden Markov Models (HMMs), deep neural networks (DNNs) like LSTM and Transformer-based models, Mimicry attacks, graph representation learning (DeepWalk, Graph Attention Networks (GAT), Graph isomorphism network (GIN)...), provenance graphs and finally provenance-based intrusion detection systems or Prov-HIDS/Prov-EDRs [28] (from Streamspot [18], Unicorn [18], sketching-based methods, to more sophisticated and recent models like SLOT [20] which leverages Graph Neural Networks, or GNNs.
Anyone in the cybersecurity domain understands that signature and rule-based detection systems can be evaded, sometimes with minimal effort. This is primarily because attackers have numerous possibilities and parameters at their disposal to exploit applications, develop and deliver malware and achieve their objectives. The evolution and increasing sophistication of malware necessitate precise system behavior modeling.
This need is particularly critical in cloud workloads, where thousands of pods or containers are deployed, running modern and complex software packed with "magical" features developed by software developers who often have minimal security background and expertise. These workloads are frequently supported by thousands of open-source components, which can introduce vulnerabilities. The introduction of AI assistants in this area may only exacerbate these challenges.
Modeling runtime behavior is essential for detecting malicious, advanced cyberattack campaigns. When representing a system, context should be considered a first-class citizen in the detection process and not only treated as a secondary triage tool to support threat hunting.
Finally, it should be stressed that most Prov-HIDSs perform well in stable environments, such as production workloads or data centers, where network flows are well-defined and can typically be observed during the training phase (closed world assumption) [18]. However, modeling workstations presents additional challenges and remains an open problem to solve.
System calls have long been regarded as the superior de facto information source for detecting attacks and investigating the behavior of computer systems.
Recently, a few companies specializing in Application Runtime Security (ADRs) have emerged, leveraging eBPF to monitor cloud workloads. A notable example is Oligo Security. What sets these approaches apart from traditional Runtime Application Self-Protection (RASP) solutions is that system call sequences can be monitored directly from the kernel, avoiding the burden, overhead, and instability associated with manual instrumentation. While manual instrumentation can provide fine-grained provenance, the kernel-based approach offers a more efficient and stable alternative.

In the early stages of program modeling research, people typically used system call sequences to describe hosts’ behavior. The problem of sequence-based anomaly detection is as follows: given a dataset \( S \), where each \( s^i \in S \) is a sequence over an alphabet \( \Sigma \), that is, \( s_i = (s_1^i, \dots, s_k^i) \) of size \( k \), and each \( s_j^i \in \Sigma \), detect whether a given sequence is valid according to a baseline. There are different methodologies to create a baseline, including a normality database consisting of possible subsequences (n-grams), Finite State Machines (FSMs) etc. Models can be built directly from program source code, dynamically using hooking techniques, or in a hybrid fashion; combining both static and dynamic analysis.
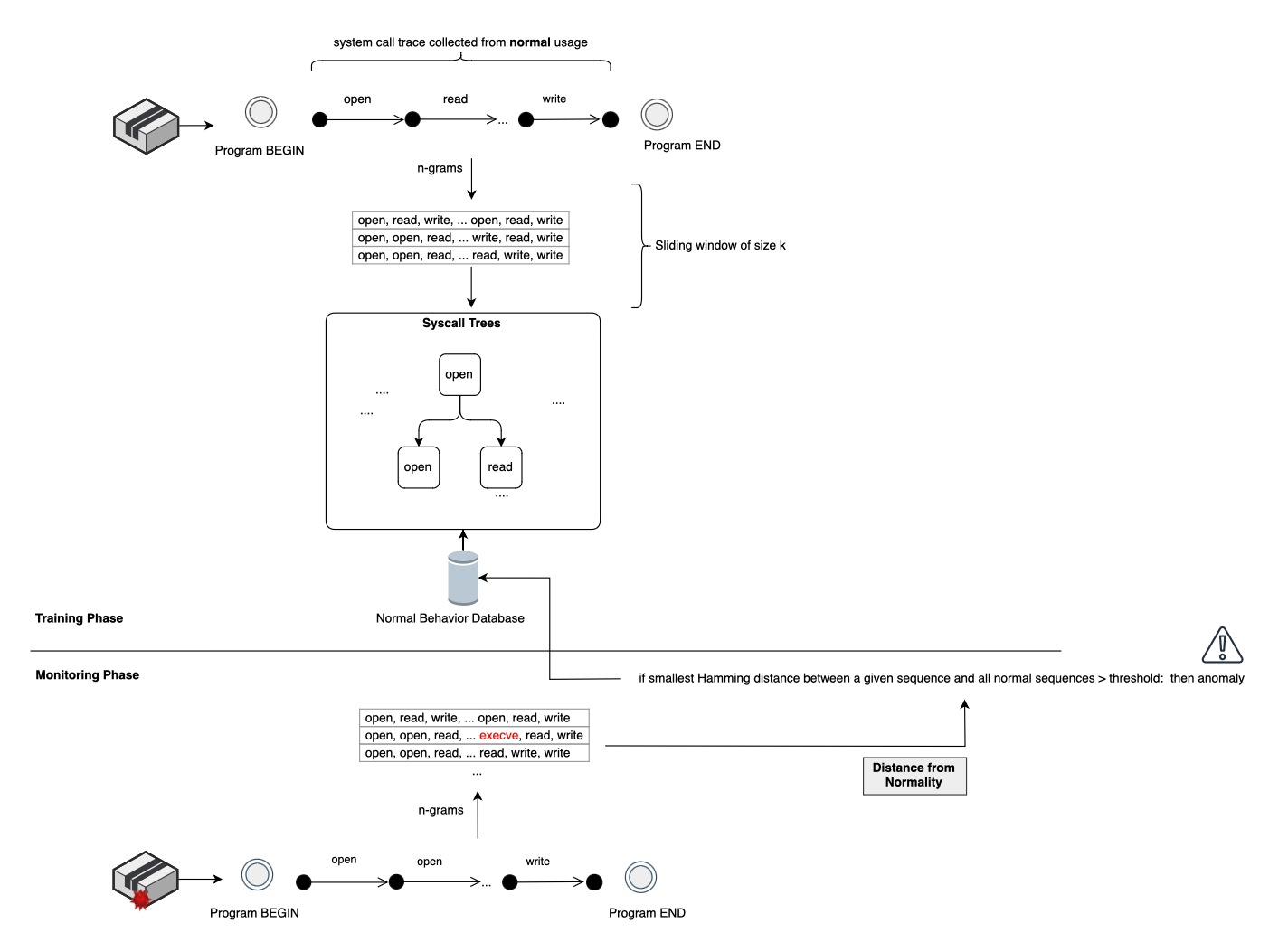
Forrest et al [1] were the first to propose using short sequence of system calls to model program behavior. They proposed monitoring program execution by tracing its system calls and using these sequences as a discriminator between benign and malicious or abnormal behaviors.
Considering that a program trace consists of symbols (e.g. system or function calls), Finite-State Automaton or FSA techniques [2, 3, 4] model the application by constructing a finite state machine whose language defines all possible traces (e.g. sequence of system calls) an application may generate during correct execution. Once a model is trained, non-accepted sequences would signal an anomaly.
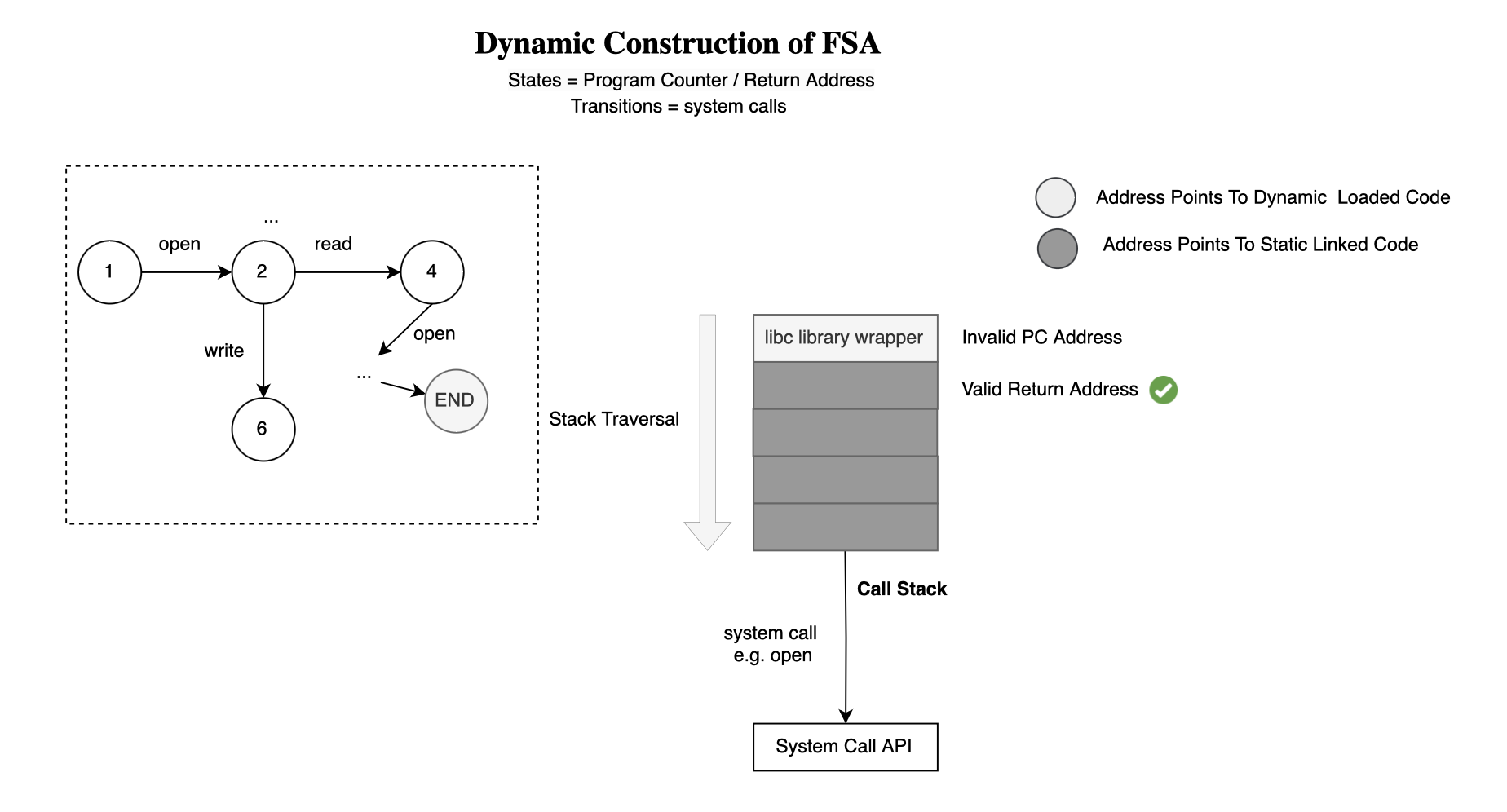
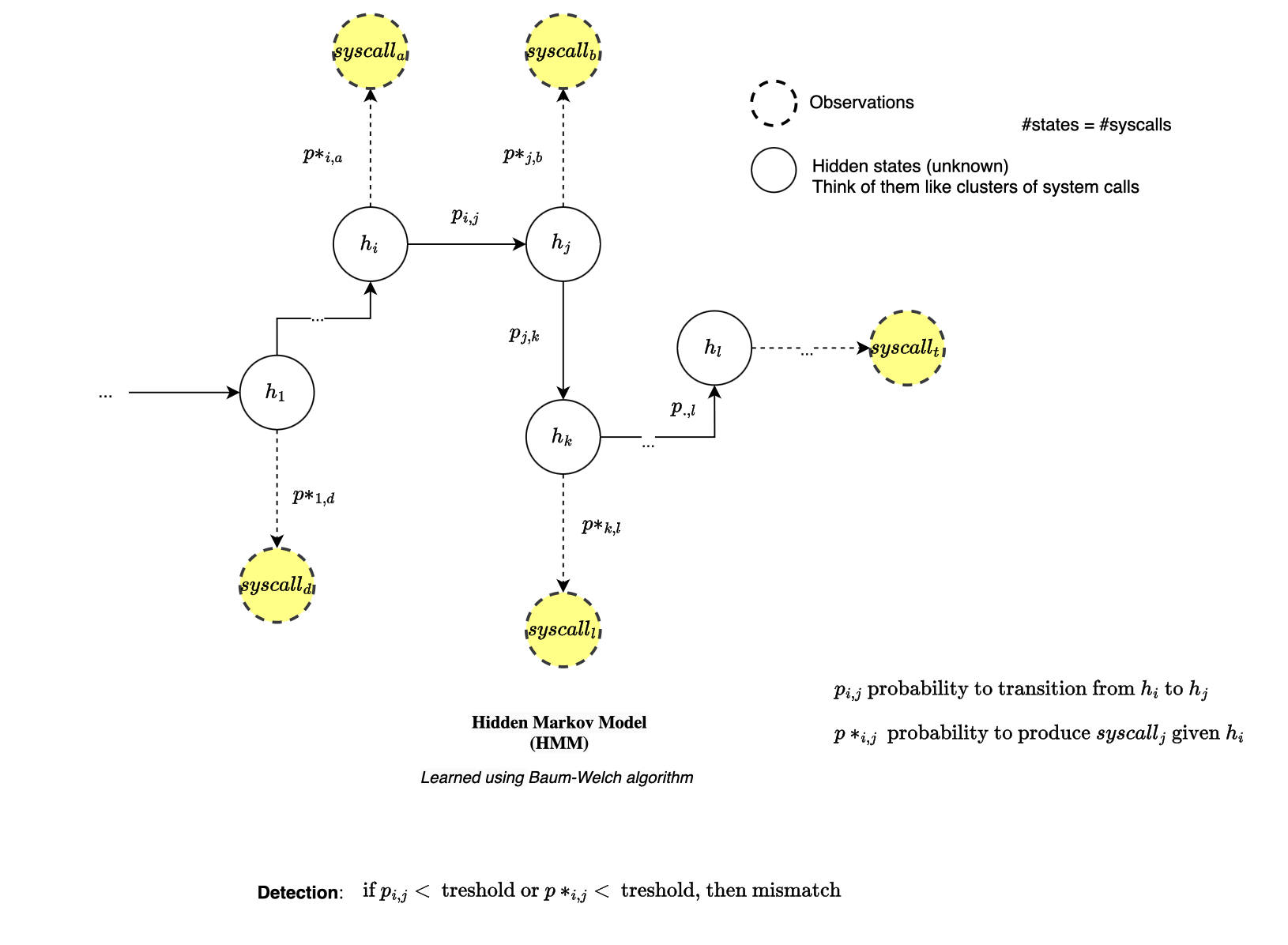
Another class of techniques considers using machine learning to learn the distribution governing the sequence of data. Anomalous sequences can be detected using a threshold, where every sequence’s score beyond that threshold would be considered anomalous. Different methods (will be discussed in separately in later posts) were explored to learn this distribution, including Hidden Markov Models (HMMs) [5, 6,7, 8] , Long Short-Term Memory networks (LSTMs) and Transformers [9, 10, 11, 12], or Large Language Models (LLMs) [13, 14].
HMMs methods consider that an application’s behavior consists of a sequence of program execution states. For instance, Warrender et al. [8] explored different methods for modeling program behaviors using system call traces, including HMMs. They used the number of system calls as the number of hidden states and trained the model using the Baum-Welch algorithm. However, HMMs are computationally expensive, requiring \( O(T S^2) \) time complexity and high storage capacity.
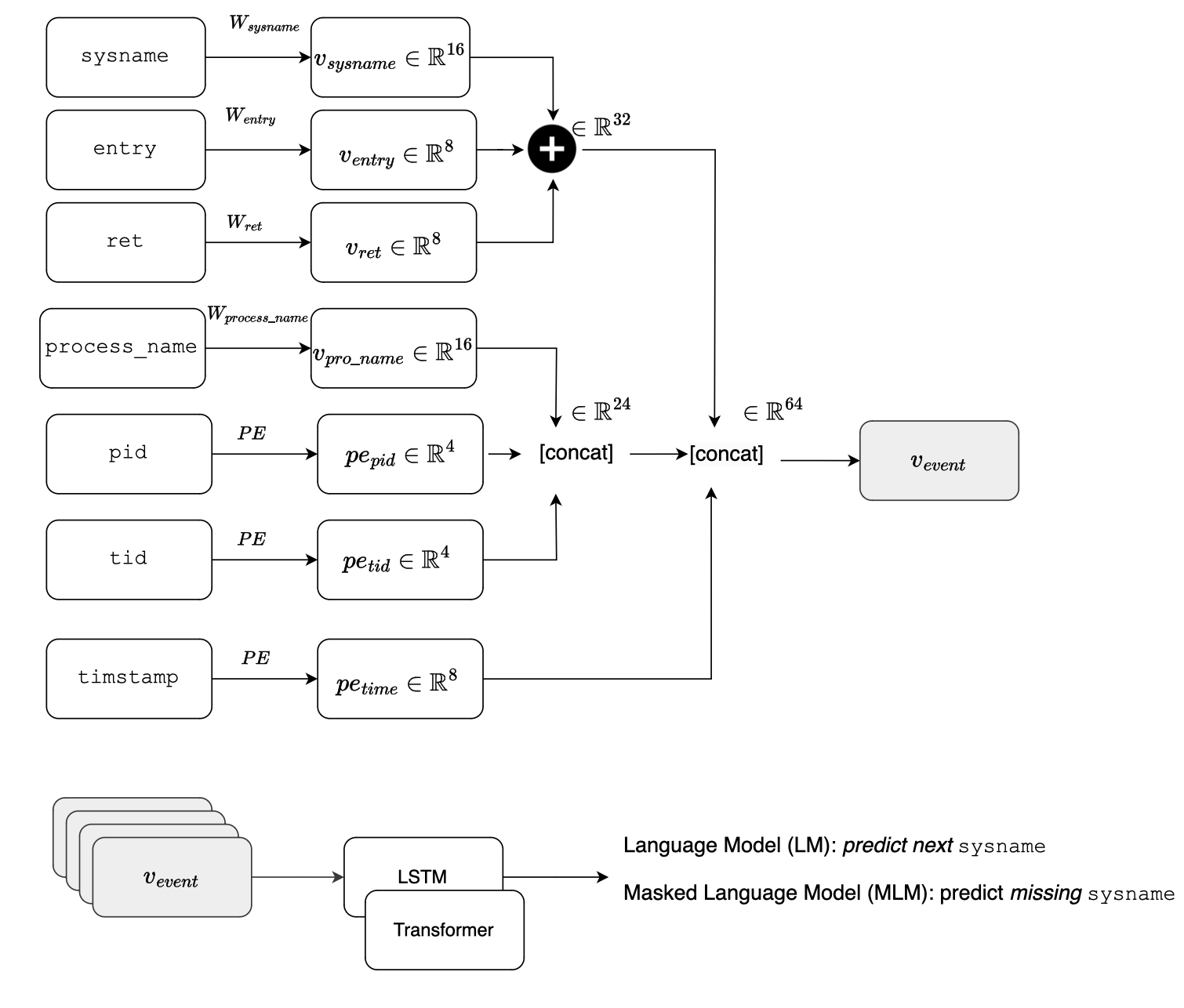
Quentin Fournier et al. in [11, 12], in contrast to most previous work on anomaly detection based on kernel traces, used both system calls along with their arguments, employing both embedding and encoding techniques to train an LSTM and a Transformer.
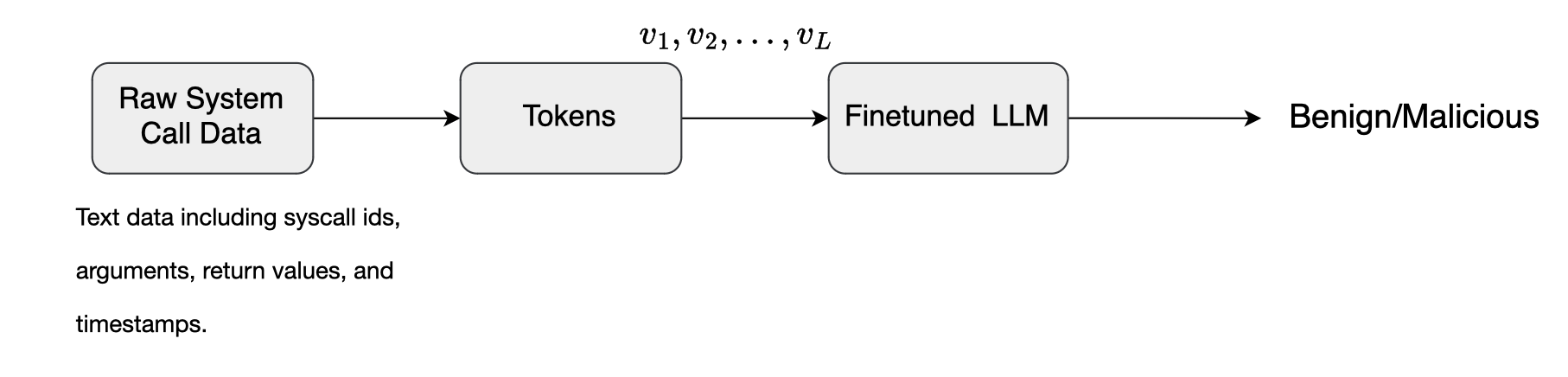
Pedro Miguel Sanchez Sanchez et al. [13] used transfer learning to leverage the knowledge base of LLMs and refine pre-trained LLMs for malware detection. They fine-tuned these models on a dataset of benign and malicious system calls. Several pre-trained LLMs were evaluated including DistilBERT, GPT-2 and Mistral,
with BigBird and Longformer emerging as the best performers.
One of the limitations of simple HIDS models is their inability to capture long-term behaviors or events. Researchers have observed that there is an underlying graph structure in system telemetry data, leading to the emergence of HIDS based on provenance graphs or Prov-HIDS.
What makes provenance graphs particularly interesting is that their graphical structure preserves the causal relationships between events, regardless of how far apart they occur temporally. This allows for a broader context to be considered, which significantly supports threat hunting. In contrast, sequence-based approaches like LSTMs account only for temporal relationships and fail to capture causality, unlike GNN-based approaches.
However, learning event representations on provenance graphs is not a trivial task. Provenance graphs are inherently attributed, heterogeneous, continuous-time temporal, directed graphs. Applying GNN models naively to these graphs is not scalable (computation graph for seed nodes may not fit in memory and you usually restrict the view to k hops). Moreover, designing a system where the embeddings of nodes change dynamically as the graph structure around the seed node evolves is highly challenging (we will discuss this in more detail in a later post).
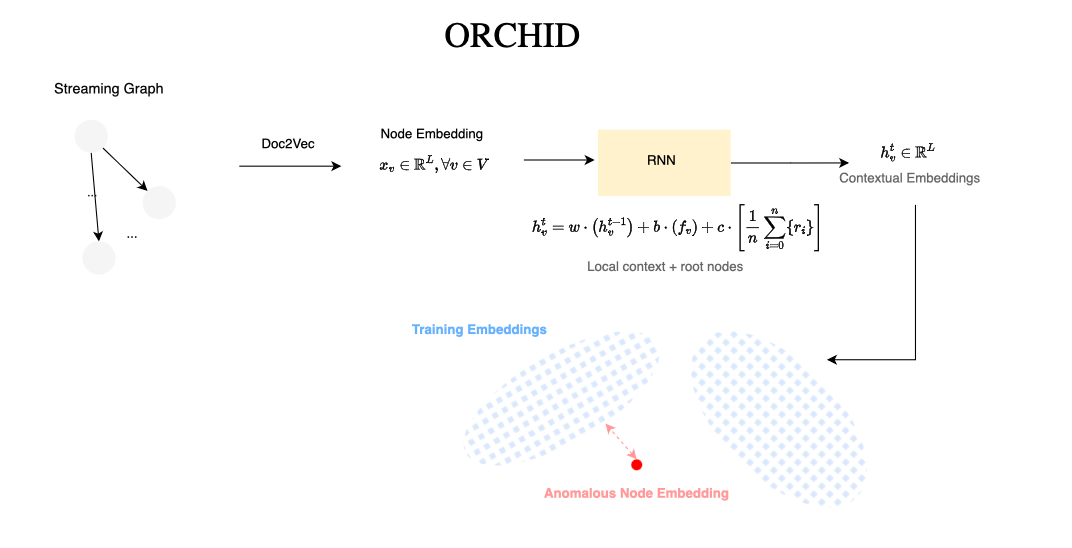
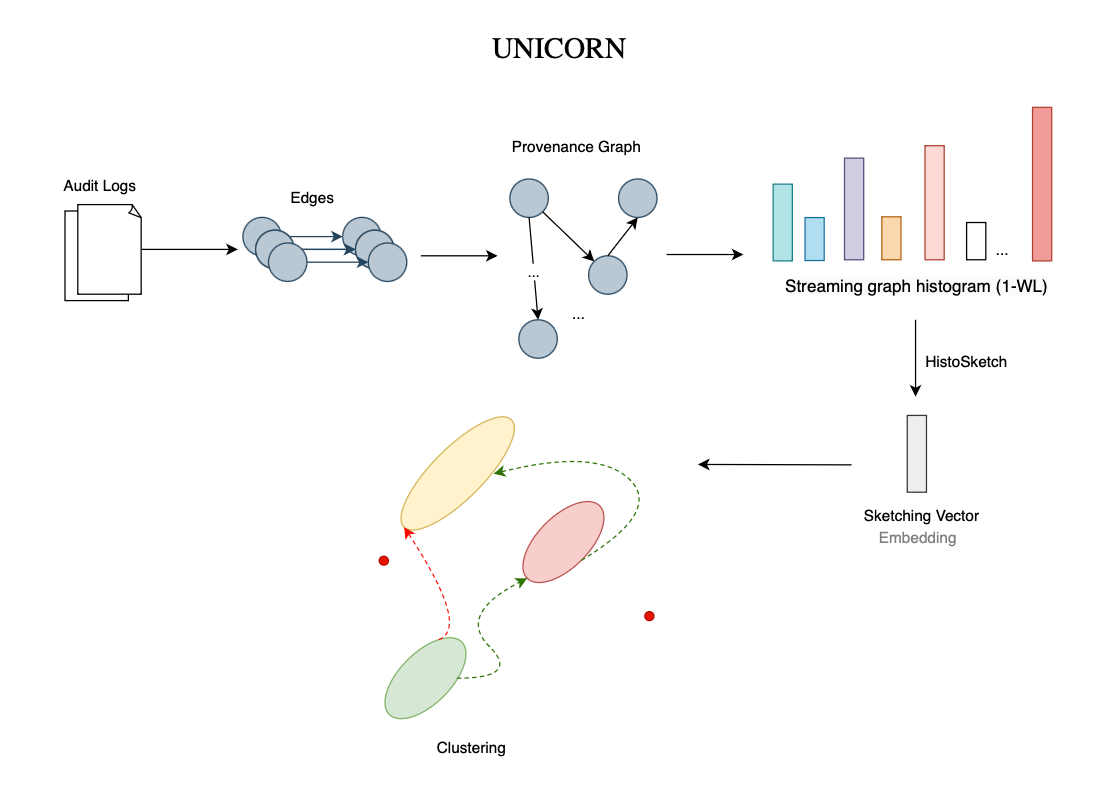
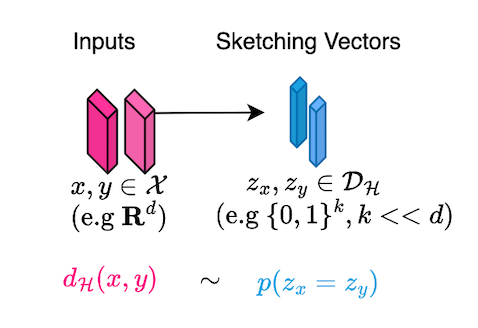
GNNs are not the only approach to generating node embeddings or representations. Several prior works have explored alternative methods, such as sketching techniques employed by frameworks like Unicorn [18] and Node2Bits [22].
We will explore this topic in greater detail later; for now, I wanted to provide a brief context and motivation for what can be achieved with an efficient and effective system telemetry infrastructure and representation.
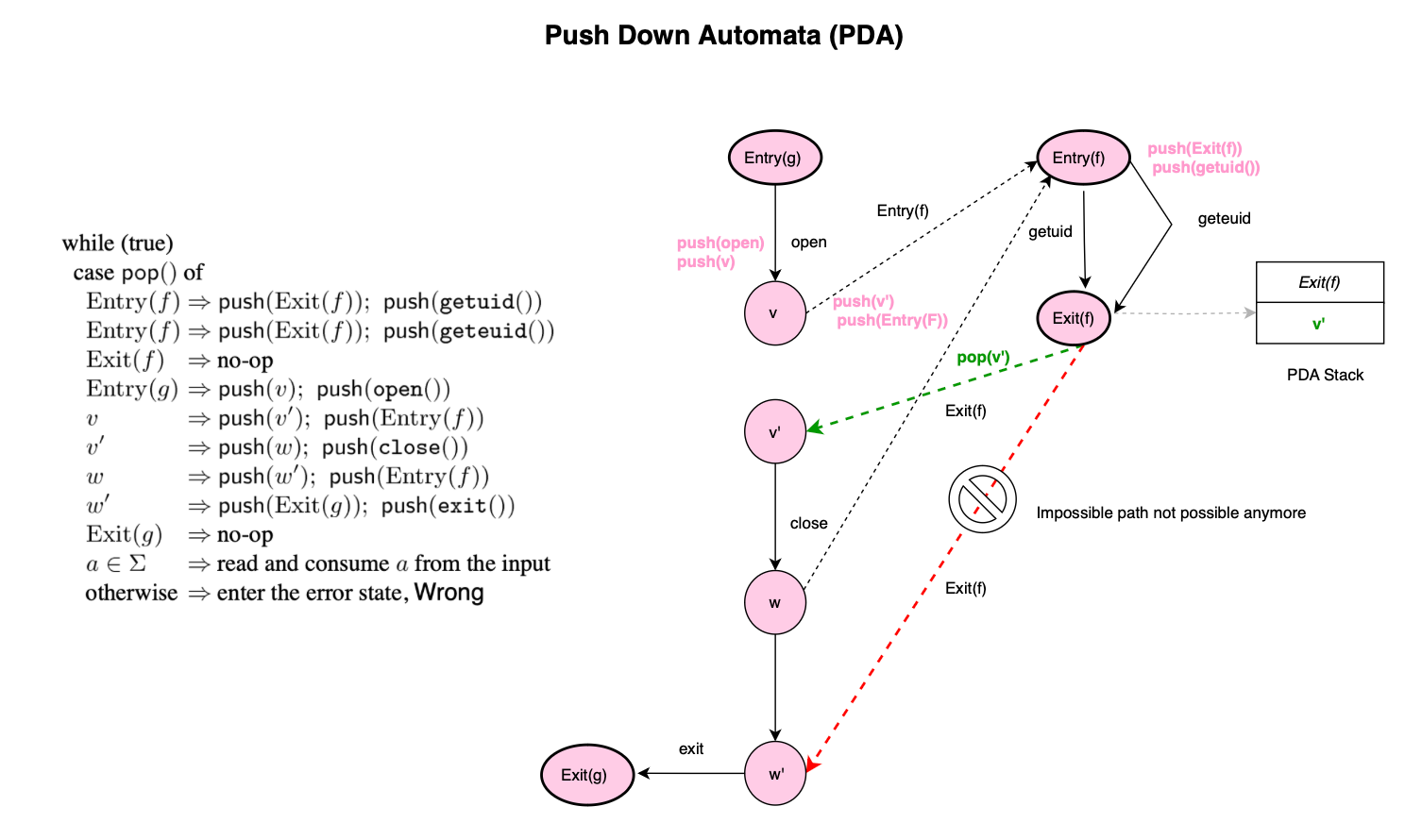
Mimicry attacks [15] were first introduced by Wagner et al., as a means by which an attacker can bypass an anomaly-based IDS. The attack involves issuing dummy system calls to mimic normal behavior, hence the term mimicry attack.
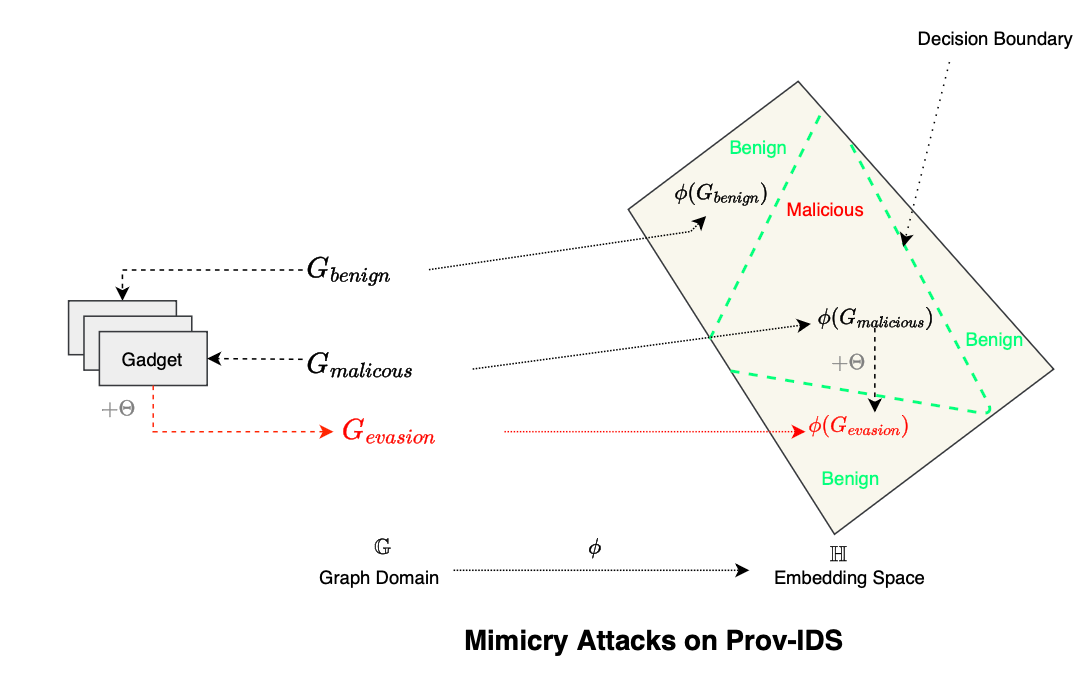
Specifically, subtraces are hidden (such as the one given by Wagner et al., where detection would be trivial: open(), write(), close(), socket(), bind(), listen(), accept(), read(), fork(); with a fork() right after a read() system call). The idea is to insert dummy system calls or no-op system calls with no effect, such as reading 0 bytes from an open file descriptor, to conceal malicious intent within the syscall stream.
Formally, let \(\Sigma\) denote the set of monitored system calls, and \(\Sigma+\) the set of sequences over the alphabet \(\Sigma\). If we denote the set of accepted system call sequences, or the regular language of syscall traces, as \(B \in \Sigma+ \), and let \(A\) denote the set of sequences that preserve the semantics of the attack while achieving its goal, the intersection \(A \cap B\) is essentially what the attacker seeks i.e a sequence that achieves the attack’s objective while being accepted by the model (e.g., an FSA), thus making it an undetected attack.
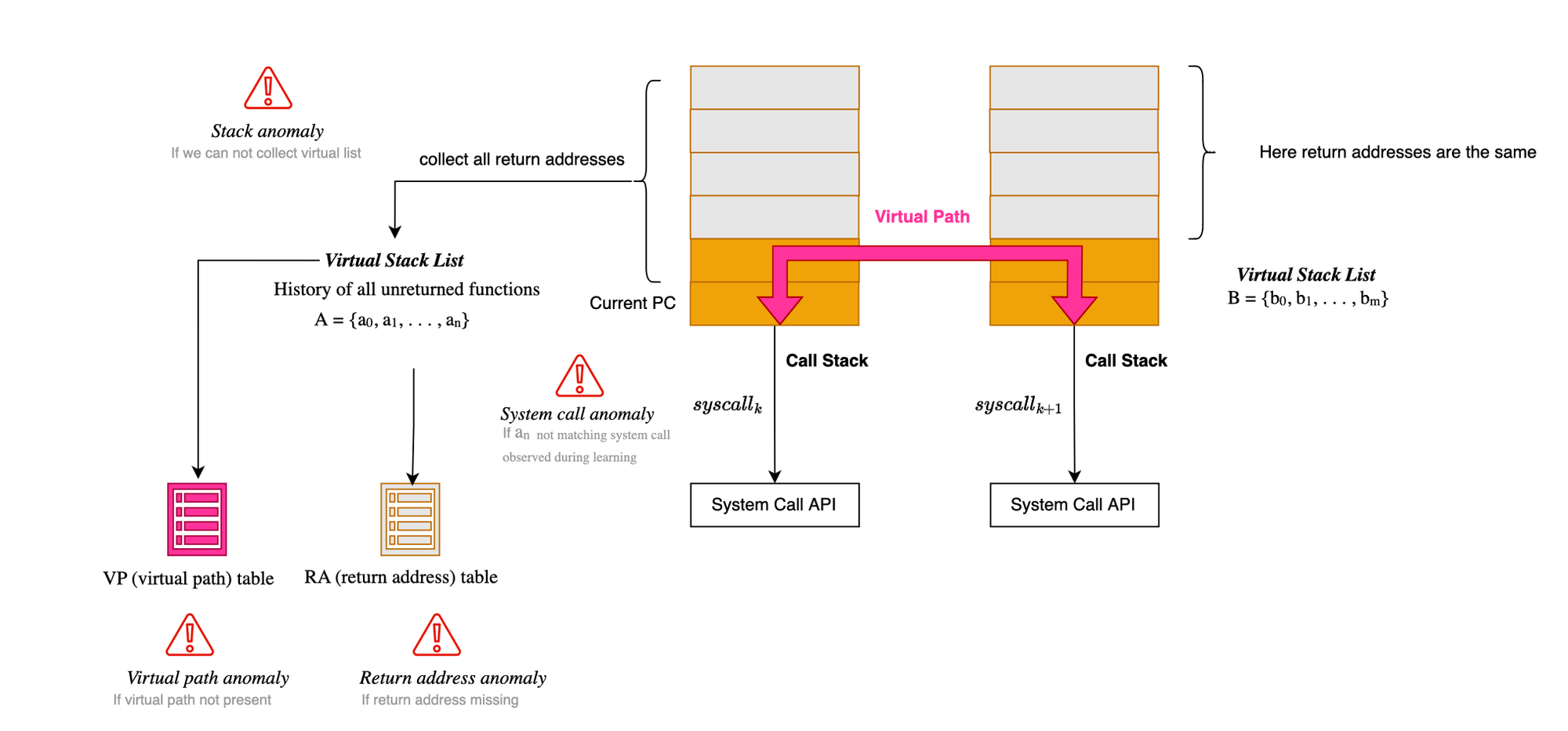
Defenses against this type of attack include inspecting and modeling system call arguments, something often ignored or not implemented by most schemes due to the complexity and variability of the arguments (the argument space is infinite and difficult to model with low false positives). Additionally, inspecting a program’s runtime stack makes mimicry attacks more difficult to achieve.
Sequence-based methods fail to correlate events that are distant in time, which prompted academia and industry to utilize provenance graphs to model system entities. The problem of system profiling is reframed as a graph learning problem. Such an approach is highly effective in detecting APTs and delineating normal from malicious behaviors.
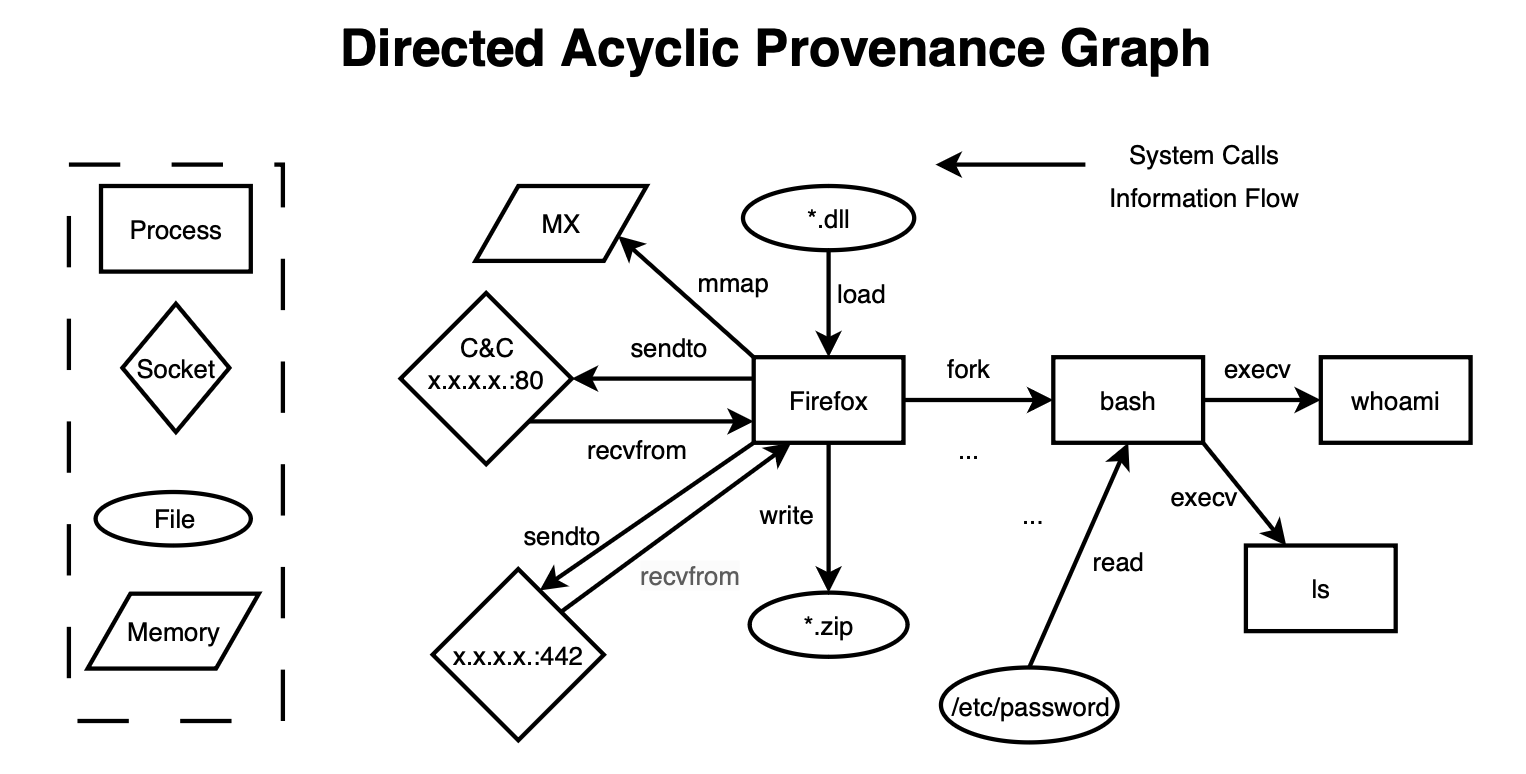
Provenance graphs encodes historical context, that is, detailed traces of system behavior. They consist of a set of system entities such as files and processes/threads created by observing system calls during system or program execution. The edges in a provenance graph represent control and data flows between these entities. They enable the inference of exact provenance (e.g., determining how a process was spawned). By encoding both temporal and spatial contexts in the dependency graph, they reveal attacker activities as additional vertices and edges with unusual topologies or substructures. This makes provenance graphs a potent tool for threat detection, attack reconstruction, and investigation.
Beyond threat detection, provenance graphs can also be used for root cause analysis and impact assessment. For example, given a symptom or point of interest, analysts can perform backward traversal to identify the root cause (entry points) and forward traversal to assess impact (damage of the intrusion). However, naively applying forward and backward analysis does not scale for massive graphs with millions of edges, specially that attack behaviors are extremely sparser than normal behaviors. As the graph becomes too large to analyze, it leads to the needle-in-a-haystack problem. In later posts, we will explore how certain models attempt to filter out unlikely paths and prioritize plausible directions.
Despite their promise, there are several challenges when using provenance graphs as auxiliary knowledge for profiling endpoints or programs. Developing systems capable of monitoring large numbers of hosts is challenging. Workstations and application workloads generate data streams or system calls continuously, could be thousands per second, with one host potentially housing hundreds of processes and generating gigabytes of data per day. This challenge is particularly pronounced when addressing APTs, where attackers can remain dormant for months or years. The storage overhead is also significant; the massive size of provenance graphs prevents them from being stored in memory, and many models in the literature struggle to control memory usage (which leads to OOM); others use node prunning which could be exploited by attackers.
Additionally, in provenance graphs, every output of a process becomes causally dependent on all previous events. This dependency explosion complicates detection, learning, and attack reconstruction, making graph analysis challenging. Furthermore, attack behaviors represent a very tiny portion of the graph (e.g. 0.3%) and are often subtle, crowded out by the noise of benign behaviors. Most models are susceptible to evasion attacks if they are not sensitive to small changes in the graph, e.g mimicry attacks.
Many embedding based models use batch processing to create snapshots of static graphs, which are then passed to GNN-based detection models. This introduces dwell time, increasing detection latency and giving attackers an opportunity to exploit the delay.
Finally, most models operate under the closed-world assumption, which assumes that all benign behaviors are observable during training. However, in real-world scenarios, models are likely to encounter unknown substructures or behaviors (e.g., execution errors), leading to false positives or negatives. Deploying PIDS in complex unpredictable environments remains an open problem.
Certain attacks cannot be detected by intrusion detection models that rely on provenance graphs as their source of information, specifically those that do not traverse the system call interface. For instance, information leakage in the OpenSSL Heartbleed vulnerability (CVE-2014-0160) [16] cannot be detected using provenance data. In this vulnerability, the attacker exploits a code defect to command the server to leak chunks of memory. This type of attack also cannot be detected using system call sequences alone.
Additionally, injection vulnerabilities, such as SQL injection, cannot be effectively detected by analyzing only system calls. For these types of attacks, additional features, such as HTTP parameter values, need to be incorporated into the model for example, through instrumentation or OpenTelemetry (OTel).
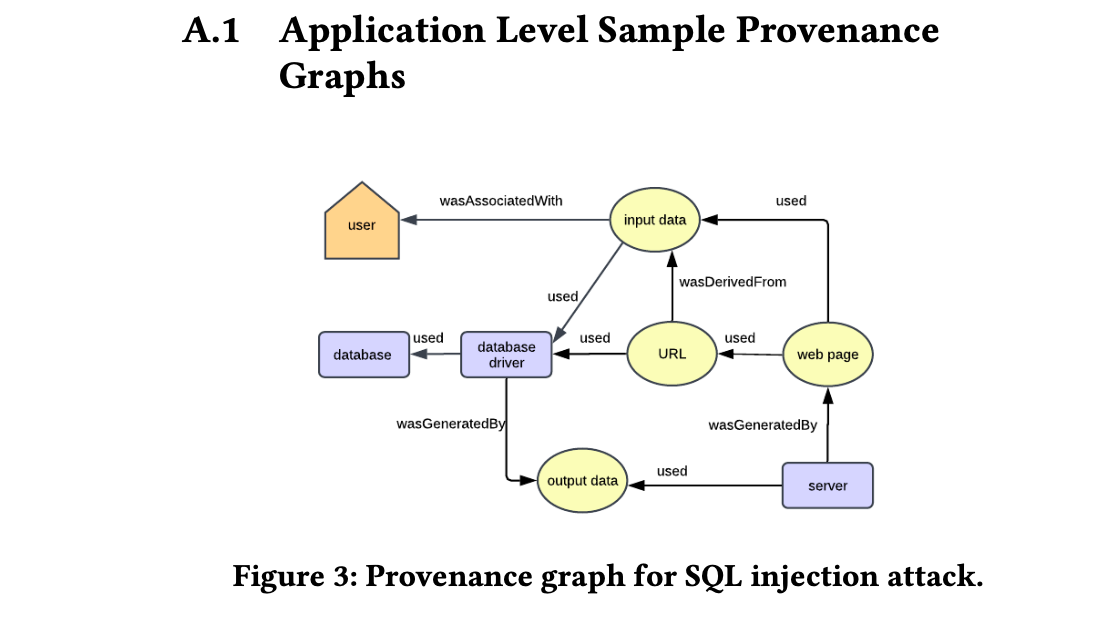
Flurry [19], for instance, captures provenance data across multiple system and application layers. It converts audit logs from these attacks into data provenance graphs. At the kernel layer, Flurry uses CamFlow, while application-level provenance is captured through hooking or instrumentation to trace the flow of data within the web application, providing semantic context to kernel-level events. For graph storage, they use Neo4j, and node embeddings are employed to enrich the data representation.

EDRs or rule-based systems are often considered the primary contributors to the threat fatigue problem. They generate a large volume of false positive alerts, leaving cybersecurity analysts overwhelmed with the necessity of verifying the veracity of every alert. This leads directly to the threat fatigue problem.
To verify the validity of these alerts, analysts must sift through an enormous amount of low-level events. Modern computer systems and cloud workloads generate massive amounts of data; one host alone can produce gigabytes of audit logs in a single day. This abundance of data provides a boon to attackers, who can hide and bury their anomalous activities within the immense volume of logs. Compounding the issue, the context of these executions available to analysts is often limited or cannot be efficiently analyzed, creating a needle-in-a-haystack problem.
When employing machine learning, simplistic recurrent models are effective at capturing short-term behavior but struggle to capture distant, long-term information during learning and prediction. Consequently, such models are not well-suited for detecting APTs.
The next post will be about building streaming provenance graph, we will cover how to implement fast and scalable telemetry infrastructure using eBPF, that is, demonstrate how to collect system calls fast, at cloud scale, using lightweight, non-intrusive collection, and transform them into high-level representations using graph structures. These representations will serve as the foundation for applying reasoning techniques in later articles.
[1] S. Forrest, S.A. Hofmeyr, A. Somayaji, and T.A. Longstaff. A sense of self for unix processes. In Proceedings 1996 IEEE Symposium on Security and Privacy, pages 120–128, 1996.
[2] R. Sekar, M. Bendre, D. Dhurjati, and P. Bollineni. A fast automaton-based method for detecting anomalous program behaviors. In Proceedings 2001 IEEE Symposium on Security and Privacy. SP 2001, pages 144–155, 2001.
[3] Zhen Liu. Combining static analysis and dynamic learning to build context sensitive models of program behavior. PhD thesis, USA, 2005. AAI3206997.
[4] D. Wagner and R. Dean. Intrusion detection via static analysis. In Proceedings 2001 IEEE Symposium on Security and Privacy. SP 2001, pages 156–168, 2001.
[5] Y. Qiao, X.W. Xin, Y. Bin, and S. Ge. Anomaly intrusion detection method based on hmm. Electronics Letters, 38:663 – 664, 07 2002.
[6] Kui Xu, Danfeng Daphne Yao, Barbara G. Ryder, and Ke Tian. Probabilistic program modeling for high-precision anomaly classification. In 2015 IEEE 28th Computer Security Foundations Symposium, pages 497–511, 2015.
[7] Cheng Zhang and Qinke Peng. Anomaly detection method based on hmms using system call and call stack information. In Yue Hao, Jiming Liu, Yu-Ping Wang, Yiu-ming Cheung, Hujun Yin, Licheng Jiao, Jianfeng Ma, and Yong-Chang Jiao, editors, Computational Intelligence and Security, pages 315–321, Berlin, Heidelberg, 2005. Springer Berlin Heidelberg.
[8] C. Warrender, S. Forrest, and B. Pearlmutter. Detecting intrusions using system calls: alternative data models. In Proceedings of the 1999 IEEE Symposium on Security and Privacy (Cat. No.99CB36344), pages 133–145, 1999.
[9] Sunwoo Ahn, Hayoon Yi, Ho Bae, Sungroh Yoon, and Yunheung Paek. Data embedding scheme for efficient program behavior modeling with neural networks. IEEE Transactions on Emerging Topics in Computational Intelligence, 6(4):982–993, 2022.
[10] Quentin Fournier, Daniel Aloise, Seyed Vahid Azhari, and Francois Tetreault. On improving deep learning trace analysis with system call arguments. CoRR, abs/2103.06915, 2021.
[11] Quentin Fournier, Daniel Aloise, Seyed Vahid Azhari, and Francois Tetreault. On improving deep learning trace analysis with system call arguments. CoRR, abs/2103.06915, 2021.
[12] Quentin Fournier, Daniel Aloise, and Leandro R. Costa. Language models for novelty detection in system call traces, 2023.
[13] Pedro Miguel Sanchez Sanchez, Alberto Huertas Celdran, Gerome Bovet, and Gregorio Martınez Perez. Transfer learning in pre-trained large language models for malware detection based on system calls, 2024.
[14] Mahmood Sharif, Pubali Datta, Andy Riddle, Kim Westfall, Adam Bates, Vijay Ganti, Matthew Lentzk, and David Ott. Drsec: Flexible distributed representations for efficient endpoint security. In 2024 IEEE Symposium on Security and Privacy (SP), pages 3609–3624, 2024.
[15] David A. Wagner and Paolo Soto. Mimicry attacks on host-based intrusion detection systems. In Conference on Computer and Communications Security, 2002.
[16] Jonathan Knudsen, How to cybersecurity: Heartbleed deep dive, https://www.blackduck.com/blog/heartbleed-vulnerability-appsec-deep-dive.html.
[17] Xueyuan Han, Thomas F. J.-M. Pasquier, Adam Bates, James Mickens, and Margo I. Seltzer. 2020. UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats. CoRR abs/2001.01525 (2020). arXiv:2001.01525 http://arxiv. org/abs/2001.01525.
[18] Emaad A. Manzoor, Sadegh Momeni, Venkat N. Venkatakrishnan, and Leman Akoglu. 2016. Fast Memory-efficient Anomaly Detection in Streaming Heteroge- neous Graphs. arXiv:1602.04844.
[19] Kapoor, Maya & Melton, Joshua & Ridenhour, Michael & Sriram, Mahalavanya & Moyer, Thomas & Krishnan, Siddharth. (2022). Flurry: a Fast Framework for Reproducible Multi-layered Provenance Graph Representation Learning. 10.48550/arXiv.2203.02744.
[20] Wei Qiao, Yebo Feng, Teng Li, Zijian Zhang, Zhengzi Xu, Zhuo Ma, Yulong Shen, JianFeng Ma, and Yang Liu. Slot: Provenance-driven apt detection through graph reinforcement learning, 2024.
[21] H. H. Feng, O. M. Kolesnikov, P. Fogla, W. Lee and Weibo Gong, "Anomaly detection using call stack information," 2003 Symposium on Security and Privacy, 2003., Berkeley, CA, USA, 2003, pp. 62-75, doi: 10.1109/SECPRI.2003.1199328.
[22] Di Jin, Mark Heimann, Ryan Rossi, and Danai Koutra. node2bits: Compact time- and attribute-aware node representations for user stitching, 2019.
[23] R. Sekar, H. Kimm and R. Aich, "eAudit: A Fast, Scalable and Deployable Audit Data Collection System*," in 2024 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 2024.
[24] Dong, Feng et al. “Are we there yet? An Industrial Viewpoint on Provenance-based Endpoint Detection and Response Tools.” Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security (2023).
[25] Taylor, T., Araujo, F., & Shu, X. (2020, December). Towards an open format for scalable system telemetry. In 2020 IEEE International Conference on Big Data (Big Data) (pp. 1031-1040). IEEE.
[27] Goyal, A., Liu, J., Bates, A., & Wang, G. (2024). ORCHID: Streaming Threat Detection over Versioned Provenance Graphs. arXiv preprint arXiv:2408.13347.
[28] Dong, F., Li, S., Jiang, P., Li, D., Wang, H., Huang, L., ... & Chen, X. (2023, November). Are we there yet? an industrial viewpoint on provenance-based endpoint detection and response tools. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security (pp. 2396-2410).]


